Dada una string S que consta de letras en minúsculas de tamaño N y Q consultas en el rango [L, R] , la tarea es imprimir el recuento de caracteres distintos en la substring por rango dado para cada consulta.
Ejemplos:
Entrada: S = “geeksforgeeks”, Q[][] = {{0, 4}, {3, 7}}
Salida:
4
5
Explicación:
los caracteres distintos en la substring S[0:4] son ’g’, ‘e ‘, ‘k’ y ‘s’
Los caracteres distintos en la substring en S[3:7] son ’k’, ‘s’ ‘f’, ‘o’ y ‘r’Entrada: S = «geeksforgeeksisacomputerscienceportal», Q[][] = {{0, 10}, {15, 18}, {12, 20}}
Salida:
7
4
8
Enfoque ingenuo: la idea es usar hashing para mantener la frecuencia de cada carácter en la substring dada y luego contar los caracteres con una frecuencia igual a 1.
A continuación se muestra la implementación del enfoque anterior:
C++
// C++ Program for Naive Approach
#include <bits/stdc++.h>
using namespace std;
void findCount(string s, int L, int R)
{
// counter to count distinct char
int distinct = 0;
// Initializing frequency array to
// count characters as the appear in
// substring S[L:R]
int frequency[26] = {};
// Iterating over S[L] to S[R]
for (int i = L; i <= R; i++) {
// incrementing the count
// of s[i] character in frequency array
frequency[s[i] - 'a']++;
}
for (int i = 0; i < 26; i++) {
// if frequency of any character is > 0
// then increment the counter
if (frequency[i] > 0)
distinct++;
}
cout << distinct << endl;
}
/* Driver code*/
int main()
{
string s = "geeksforgeeksisacomputerscienceportal";
int queries = 3;
int Q[queries][2] = { { 0, 10 },
{ 15, 18 },
{ 12, 20 } };
for (int i = 0; i < queries; i++)
findCount(s, Q[i][0], Q[i][1]);
return 0;
}
Java
// Java program for the naive approach
class GFG{
static void findCount(String s, int L,
int R)
{
// Counter to count distinct char
int distinct = 0;
// Initializing frequency array
// to count characters as the
// appear in subString S[L:R]
int []frequency = new int[26];
// Iterating over S[L] to S[R]
for(int i = L; i <= R; i++)
{
// Incrementing the count of s[i]
// character in frequency array
frequency[s.charAt(i) - 'a']++;
}
for(int i = 0; i < 26; i++)
{
// If frequency of any character
// is > 0 then increment the counter
if (frequency[i] > 0)
distinct++;
}
System.out.print(distinct + "\n");
}
// Driver code
public static void main(String[] args)
{
String s = "geeksforgeeksisa" +
"computerscienceportal";
int queries = 3;
int Q[][] = { { 0, 10 },
{ 15, 18 },
{ 12, 20 } };
for(int i = 0; i < queries; i++)
findCount(s, Q[i][0], Q[i][1]);
}
}
// This code is contributed by sapnasingh4991
Python3
# Python3 program for Naive Approach
def findCount(s, L, R):
# Counter to count distinct char
distinct = 0
# Initializing frequency array to
# count characters as the appear in
# substring S[L:R]
frequency = [0 for i in range(26)]
# Iterating over S[L] to S[R]
for i in range(L, R + 1, 1):
# Incrementing the count of s[i]
# character in frequency array
frequency[ord(s[i]) - ord('a')] += 1
for i in range(26):
# If frequency of any character is > 0
# then increment the counter
if (frequency[i] > 0):
distinct += 1
print(distinct)
# Driver code
if __name__ == '__main__':
s = "geeksforgeeksisacomputerscienceportal"
queries = 3
Q = [ [ 0, 10 ],
[ 15, 18 ],
[ 12, 20 ] ]
for i in range(queries):
findCount(s, Q[i][0], Q[i][1])
# This code is contributed by Bhupendra_Singh
C#
// C# program for the naive approach
using System;
class GFG{
static void findCount(String s, int L,
int R)
{
// Counter to count distinct char
int distinct = 0;
// Initializing frequency array
// to count characters as the
// appear in subString S[L:R]
int []frequency = new int[26];
// Iterating over S[L] to S[R]
for(int i = L; i <= R; i++)
{
// Incrementing the count of s[i]
// character in frequency array
frequency[s[i] - 'a']++;
}
for(int i = 0; i < 26; i++)
{
// If frequency of any character
// is > 0 then increment the counter
if (frequency[i] > 0)
distinct++;
}
Console.Write(distinct + "\n");
}
// Driver code
public static void Main(String[] args)
{
String s = "geeksforgeeksisa" +
"computerscienceportal";
int queries = 3;
int [,]Q = {{ 0, 10 },
{ 15, 18 },
{ 12, 20 }};
for(int i = 0; i < queries; i++)
findCount(s, Q[i, 0], Q[i, 1]);
}
}
// This code is contributed by sapnasingh4991
Javascript
<script>
// Javascript Program for Naive Approach
function findCount(s, L, R)
{
// counter to count distinct char
var distinct = 0;
// Initializing frequency array to
// count characters as the appear in
// substring S[L:R]
var frequency = Array(26).fill(0);
// Iterating over S[L] to S[R]
for (var i = L; i <= R; i++) {
// incrementing the count
// of s[i] character in frequency array
frequency[s[i].charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
for (var i = 0; i < 26; i++) {
// if frequency of any character is > 0
// then increment the counter
if (frequency[i] > 0)
distinct++;
}
document.write( distinct + "<br>");
}
/* Driver code*/
var s = "geeksforgeeksisacomputerscienceportal";
var queries = 3;
var Q = [ [ 0, 10 ],
[ 15, 18 ],
[ 12, 20 ] ];
for (var i = 0; i < queries; i++)
findCount(s, Q[i][0], Q[i][1]);
</script>
7 4 8
Complejidad del tiempo: O(Q×N)
Enfoque eficiente: un enfoque eficiente sería almacenar la posición de cada carácter tal como aparece en la string en una array. Para cada consulta dada, repetiremos los 26 alfabetos en minúsculas. Si la letra actual está en la substring S[L: R], entonces el primer elemento mayor o igual que L en el vector de posición correspondiente debe existir y ser menor o igual que R, es decir, debe haber un valor de posición entre L y R que denota la presencia del alfabeto en el rango de consulta.
Por ejemplo:
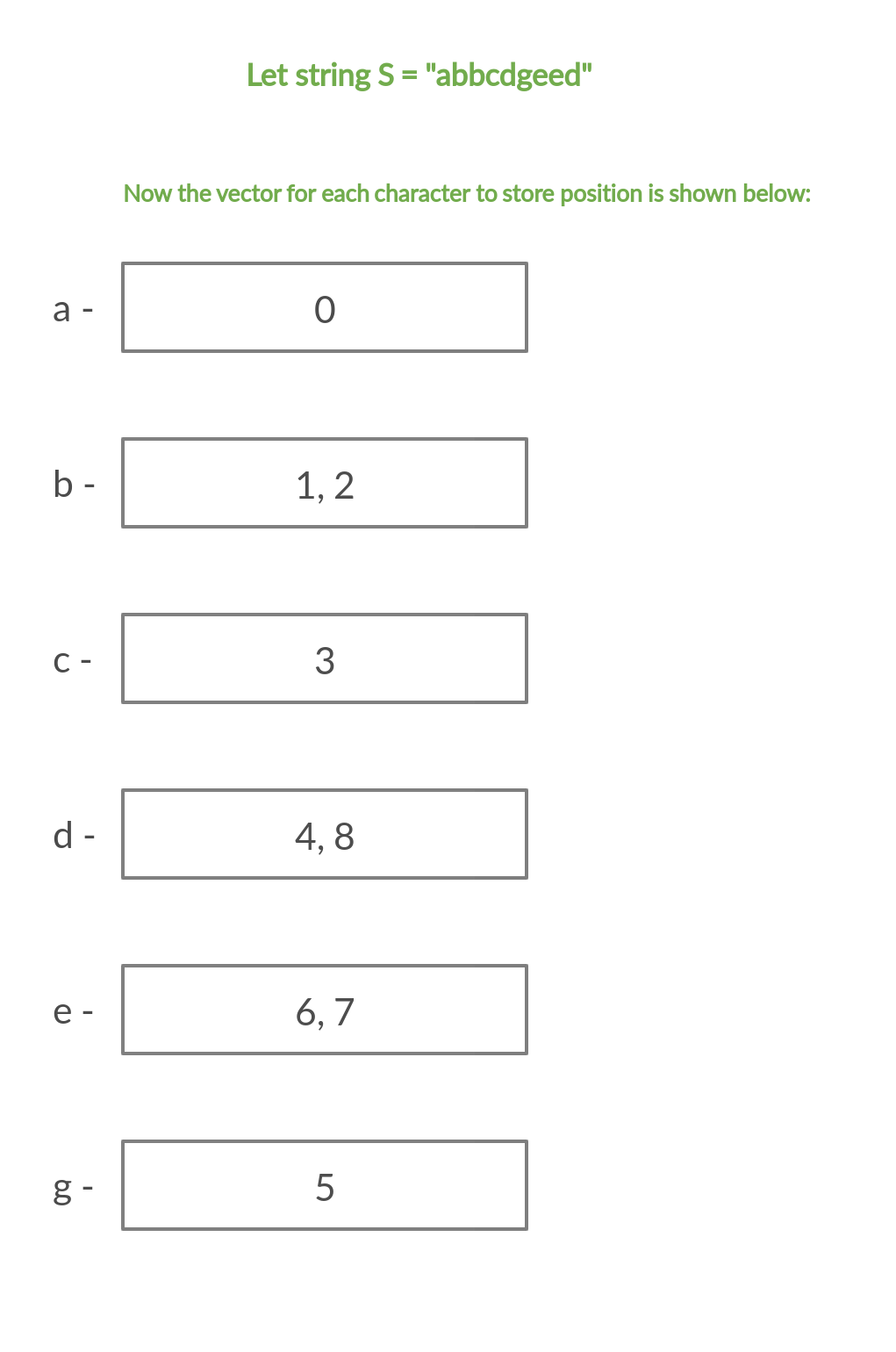
A continuación se muestra la implementación del enfoque anterior:
C++
// C++ Program for Efficient Approach
// to count the no. of distinct characters
// in a substring using STL
#include <bits/stdc++.h>
using namespace std;
// vector of vector to store
// position of all characters
// as they appear in string
vector<vector<int> > v(26);
void build_position_vector(string s)
{
for (int i = 0; i < s.size(); i++) {
// inserting position of
// character as they appear
v[s[i] - 'a'].push_back(i);
}
}
void findCount(string s, int L, int R)
{
build_position_vector(s);
// counter to count distinct char
int distinct = 0;
// iterating over all 26 characters
for (int i = 0; i < 26; i++) {
// Finding the first element
// which is greater than or equal to L
auto first = lower_bound(
v[i].begin(),
v[i].end(), L);
// Check if first pointer exists
// and is less than or equal to R
if (first != v[i].end()
&& *first <= R) {
distinct++;
}
}
cout << distinct << endl;
}
/* Driver code*/
int main()
{
string s = "geeksforgeeksisacomputerscienceportal";
int queries = 3;
int Q[queries][2] = { { 0, 10 },
{ 15, 18 },
{ 12, 20 } };
for (int i = 0; i < queries; i++)
findCount(s, Q[i][0], Q[i][1]);
return 0;
}
7 4 8
Complejidad temporal: O(N + Q logN)
Publicación traducida automáticamente
Artículo escrito por saurabhshadow y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA