Enviar una solicitud HTTP a una URL en particular y luego extraer HTML de esa página web para obtener información útil se conoce como rastreo o web scraping.
Módulos que se utilizarán para rastrear en Nodejs:
- solicitud : para enviar una solicitud HTTP a la URL
- cheerio : para analizar DOM y extraer HTML de la página web
- fs : para leer o escribir los datos en el archivo
Instalación de estos módulos:
La forma más fácil de instalar módulos en Nodejs es usando NPM.
se puede hacer de dos maneras:
- Instalación global: si instalamos cualquier módulo globalmente, podemos usarlo en cualquier parte de nuestro sistema.
Se puede hacer con el siguiente comando:npm i -g package_name
- Instalación local: si instalamos cualquier módulo localmente, podemos usarlo solo dentro de ese directorio de proyecto en particular.
Se puede hacer con el siguiente comando:npm i package_name
Para esta tarea usaremos la instalación local:
Pasos para el rastreo web con Cheerio:
- Paso 1: crea una carpeta para este proyecto
- Paso 2: Abra la terminal dentro del directorio del proyecto y luego escriba el siguiente comando:
npm init
Creará un archivo llamado
package.json
que contiene toda la información sobre los módulos, el autor, el repositorio de github y sus versiones también.
Para obtener más información sobre package.json , visite este enlace:
explicación de package.jsonPara instalar los módulos localmente usando NPM simplemente haga lo siguiente:
npm install request npm install cheerio npm install fs
Esto también se puede hacer en una sola línea usando NPM:
npm install request cheerio fs
Después de instalar con éxito los módulos, nuestro paquete.json tendrá una estructura como esta:

Aquí, en esta captura de pantalla, podemos ver que todas nuestras dependencias se han enumerado dentro del objeto de dependencias, lo que implica que las hemos instalado correctamente en nuestro directorio de proyecto actual.
- Paso 3: ahora codificaremos para el rastreador
Pasos para codificar:
- Primero importaremos todos nuestros módulos requeridos
- Luego, enviaremos una solicitud HTTP a la URL y luego el servidor del sitio web deseado responderá con una página web, se hará con el módulo de solicitud
- Ahora, tenemos el HTML de la página web, nuestra tarea es extraer la información útil de él, por lo que recorreremos el árbol DOM y encontraremos los selectores.
- Después de extraer nuestra información, la guardaremos en un archivo, esta tarea se realizará con la ayuda del módulo fs
- Código para el rastreador:
- Cree un archivo llamado server.js y agregue las siguientes líneas:
const request = require('request'); const cheerio = require('cheerio'); const mongoose = require('fs');Explicación de estas líneas de código:
aquí, en estas tres líneas, estamos importando estos tres módulos, necesarios para rastrear y guardar datos en un archivo. - Presionaremos la URL desde donde queremos rastrear los datos:
aquí vamos a rastrear la lista de teléfonos inteligentes de un sitio web de comercio electrónico Flipkart.La URL para mostrar la lista de teléfonos inteligentes es la siguiente en flipkart:
const URL = "https://www.flipkart.com/search?q=mobiles";
En esta URL, la página web se ve así:

Ahora le daremos a esta URL con la ayuda de
request
módulo:
request(URL, function (err, res, body) { if(err) { console.log(err, "error occurred while hitting URL"); } else { console.log(body); } });Entendamos este fragmento de código:
aquí estamos usando el módulo de solicitud para enviar la solicitud HTTP a la URL del flipkart de los teléfonos inteligentes, y la función dentro del módulo de solicitud toma tres parámetros error, respuesta, cuerpo respectivamente.
Aquí, si aparece un error, lo registramos; de lo contrario, registramos el cuerpo.Para probarlo, cuando ejecutaremos nuestro script por
node server.js
podemos ver todo el HTML de la página en nuestra consola.
Es el HTML completo de la página web para esta URL.Ahora nuestra tarea es extraer la información útil, por lo que visitaremos el árbol DOM y encontraremos los selectores al inspeccionar el elemento.
Para hacerlo, haga clic derecho en la página web y vaya al elemento de inspección como este:
Ahora visitaremos el DOM:

Ahora cambiaremos nuestra solicitud para acceder a la URL de acuerdo con la inspección:
request(URL, function (err, res, body) { if(err) { console.log(err); } else { let $= cheerio.load(body); //loading of complete HTML body $('div._1HmYoV > div.col-10-12>div.bhgxx2>div._3O0U0u').each(function(index){ const link = $(this).find('div._1UoZlX>a').attr('href'); const name = $(this).find('div._1-2Iqu>div.col-7-12>div._3wU53n').text(); console.log(link); //link for smartphone console.log(name); //name of smartphone }); } }); - Guardando los datos en el archivo
Para hacerlo crearemos una array y un objetolet arr = []; //creating an array let object = { link : link, name : name, } //creating an object fs.writeFile('data.txt', arr, function (err) { if(err) { console.log(err); } else{ console.log("success"); } });Y en cada iteración empujaremos nuestro objeto a la array después de convertirlo en una string;
Por último, escribiremos toda la array en el archivo. con este método, nuestros datos completos se guardarán en el archivo con éxito.Ahora a todo nuestro código le gustará:
// Write Javascript code hereconst request = require('request');const cheerio = require('cheerio');const fs = require('fs');request(URL,function(err, res, body) {if(err){console.log(err);}else{const arr = [];let $= cheerio.load(body);$('div._1HmYoV > div.col-10-12>div.bhgxx2>div._3O0U0u').each(function(index){const data = $(this).find('div._1UoZlX>a').attr('href');const name = $(this).find('div._1-2Iqu>div.col-7-12>div._3wU53n').text();const obj = {data : data,name : name};console.log(obj);arr.push(JSON.stringify(obj));});console.log(arr.toString());fs.writeFile('data.txt', arr,function(err) {if(err) {console.log(err);}else{console.log("success");}});}});
Ahora ejecuta el código:
node server.js
Puede ver la salida en la terminal de esta manera mientras ejecuta el código:
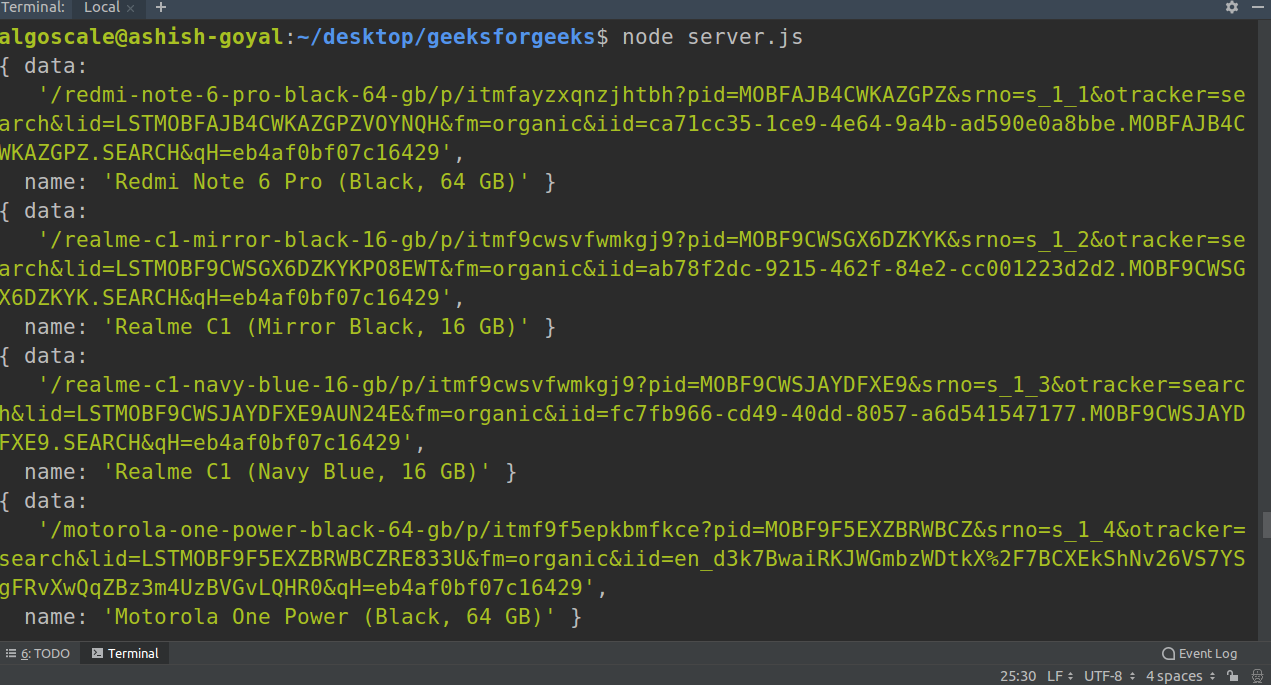
Después de ejecutar con éxito el código, hay un archivo llamado data.txt que también tiene todos los datos extraídos. podemos encontrar este archivo en nuestro directorio de proyectos.
Entonces, es un ejemplo simple de cómo crear un web scraper en nodejs usando el módulo cheerio. Desde aquí, puede intentar eliminar cualquier otro sitio web de su elección. En caso de cualquier consulta, publíquela a continuación en la sección de comentarios.
Publicación traducida automáticamente
Artículo escrito por AshishkrGoyal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA