Random Forest en R Programming es básicamente una técnica de embolsado. Por el nombre, podemos interpretar claramente que este algoritmo básicamente crea el bosque con muchos árboles. Es un algoritmo de clasificación supervisado.
En un escenario general, si tenemos una mayor cantidad de árboles en un bosque, brinda el mejor atractivo estético para todos y se cuenta como el mejor bosque. Lo mismo es el escenario en el clasificador de bosque aleatorio, cuanto mayor sea el número de árboles, mejor será la precisión y, por lo tanto, resulta ser un mejor modelo. En un bosque aleatorio, no se utilizará el mismo enfoque que utiliza en el árbol de decisiones, es decir, la entropía y la ganancia de información. Aquí, en el bosque aleatorio, extraemos muestras de arranque aleatorias del conjunto de entrenamiento.
Ventajas del bosque aleatorio:
- Bueno para manejar grandes conjuntos de datos.
- El aprendizaje es rápido y proporciona una alta precisión.
- Puede manejar un montón de variables a la vez.
- El sobreajuste no es un problema en este algoritmo.
Desventajas de Random Forest:
- La complejidad es un problema importante. Dado que el algoritmo crea una cantidad de árboles y combina su salida para producir la mejor salida, requiere más tiempo y recursos computacionales.
- El período de tiempo generalmente para entrenar un modelo de bosque aleatorio es mayor ya que genera una gran cantidad de árboles.
Computación paralela
La computación paralela básicamente se refiere al uso de dos o más núcleos (o procesadores) en la misma instancia para obtener la solución de un problema existente. El objetivo principal aquí es dividir la tarea en subtareas más pequeñas y realizarlas simultáneamente.
Un ejemplo matemático simple aclarará la idea básica detrás de la computación paralela:
Supongamos que tenemos la siguiente expresión para evaluar:
Z= 7a + 8b + 2c + 3d
Donde, a = 1, b = 2, c = 9, d = 5.
El proceso normal sin computación paralela sería:
Paso 1: Introduciendo los valores de las variables.
Z = (7*1) + (8*2) + (2*9) + (3*5)
Paso 2: Evaluando la expresión:
Z = 7 + (8*2) + (2*9) + (3*5)
Paso 3:
Z = 7 + 16 + (2*9) + (3*5)
Paso 4:
Z = 7 + 16 + 18 + (3*5)
Paso 5:
Z = 7 + 16 + 18 + 15
Paso 6:
Z = 56
La misma expresión evaluación en el escenario de la computación paralela sería la siguiente:
Paso 1: Introduciendo los valores de las variables.
Z = (7*1) + (8*2) + (2*9) + (3*5)
Paso 2: Evaluando la expresión:
Z = 7 + 16 + 18 + 15
Paso 3:
Z = 56
Entonces podemos ver la diferencia anterior de que la evaluación de la expresión es mucho más rápida en el segundo caso.
Entonces, tomé un conjunto de datos de datos de radar. Consta de un total de 35 atributos. El atributo 35 es la variable de destino que es «g» o «b». Esta variable objetivo representa principalmente los electrones libres en la ionosfera. Los retornos de radar “g” es bueno” son aquellos que muestran evidencia de algún tipo de estructura en la ionosfera y los retornos “b” es malo” son aquellos que no lo hacen; sus señales pasan a través de la ionosfera. Básicamente, es una tarea de clasificación binaria. Comencemos con la parte de codificación.
Cargando las bibliotecas requeridas:
library(caret) library(randomForest) library(doParallel)
Lectura del conjunto de datos:
datafile<-read.csv("C:/Users/prana/Downloads/ionosphere.data.csv")
datafile
Convertir la variable de destino en una variable de factor con las etiquetas 0 y 1. También verifique los valores faltantes, si los hay.
datafile$target0] set.seed(100)
Como no faltan valores, tenemos un conjunto de datos limpio. Por lo tanto, pasando a la parte de construcción del modelo. Dividir el conjunto de datos en una proporción de 80:20, es decir, conjunto de entrenamiento y conjunto de prueba, respectivamente.
Trainingindex<-createDataPartition(datafile$target, p=0.8, list=FALSE) trainingset<-datafile[Trainingindex, ] testingset<-datafile[-Trainingindex, ]
Implementación de Random Forest sin Computación Paralela
Ahora construiremos un modelo normalmente y registraremos el tiempo necesario para el mismo:
start.time<-proc.time() model<-train(target~., data=trainingset, method='rf') stop.time<-proc.time() run.time<-stop.time -start.time print(run.time)
Producción:
user system elapsed 13.05 0.20 13.62
Implementación de Random Forest con Computación Paralela
Ahora construimos el modelo con el concepto de computación paralela, cargando la biblioteca do Parallel en R (aquí ya la hemos cargado al principio, así que no es necesario cargarla nuevamente). Podemos ver la función makePSOCKcluster()que crea un conjunto de copias de R ejecutándose en paralelo y comunicándose a través de sockets. Detiene stopCluster()el Node del motor en el clúster en cl. También registraremos el tiempo necesario para construir el modelo con este enfoque.
cl<-makePSOCKcluster(5) registerDoParallel(cl) start.time<-proc.time() model<-train(target~., data=trainingset, method='rf') stop.time<-proc.time() run.time<-stop.time -start.time print(run.time) stopCluster(cl)
Producción:
user system elapsed 0.56 0.02 6.19
Tabla de comparación de diferencias horarias
Así que ahora formulamos una tabla que nos mostrará los tiempos de los 2 enfoques.
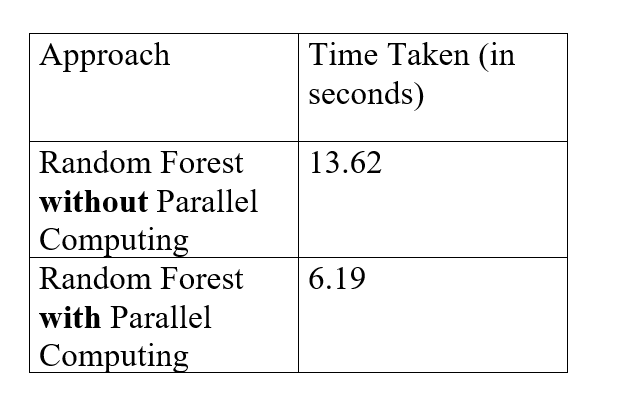
Entonces, de la tabla anterior, podemos concluir que con computación paralela el proceso de modelado es 2.200323 (=13.62/6.19) veces más rápido que el enfoque normal.
Publicación traducida automáticamente
Artículo escrito por pranavkotak40 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA