Hashing es una estructura de datos que se utiliza para almacenar una gran cantidad de datos, a los que se puede acceder en O(1)el tiempo mediante operaciones como buscar, insertar y eliminar. Varias aplicaciones de Hashing son:
- Indexación en la base de datos
- Criptografía
- Tablas de símbolos en compilador/intérprete
- Diccionarios, cachés, etc.
Concepto de Hashing, Tabla Hash y Función Hash
Hashing es una estructura de datos importante que está diseñada para usar una función especial llamada función Hash que se usa para mapear un valor dado con una clave particular para un acceso más rápido a los elementos. La eficiencia del mapeo depende de la eficiencia de la función hash utilizada.
Ejemplo:
h(large_value) = large_value % m
Aquí, h()está la función hash requerida y ‘m’ es el tamaño de la tabla hash. Para valores grandes, las funciones hash producen valor en un rango determinado.
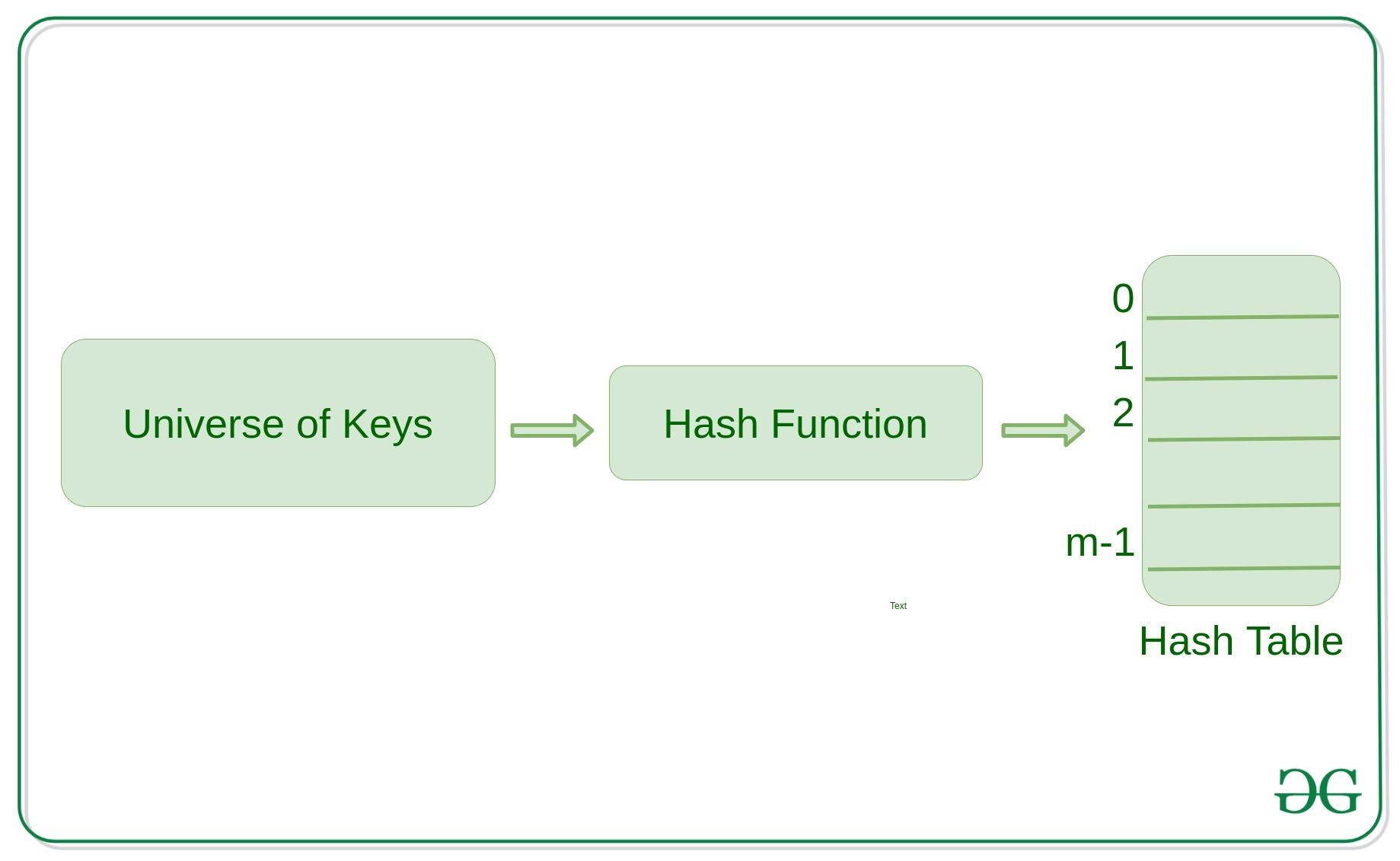
¿Cómo funciona la función hash?
- Siempre debe asignar claves grandes a claves pequeñas.
- Siempre debe generar valores entre 0 y m-1, donde m es el tamaño de la tabla hash.
- Debe distribuir uniformemente las claves grandes en las ranuras de la tabla hash.
- Enstringmiento
- Direccionamiento abierto (sondeo lineal, sondeo cuadrático, hash doble)
Manejo de colisiones
Si conocemos las claves de antemano, entonces podemos tener un hashing perfecto. En hashing perfecto, no tenemos ninguna colisión. Sin embargo, si no conocemos las claves, entonces podemos usar los siguientes métodos para evitar colisiones:

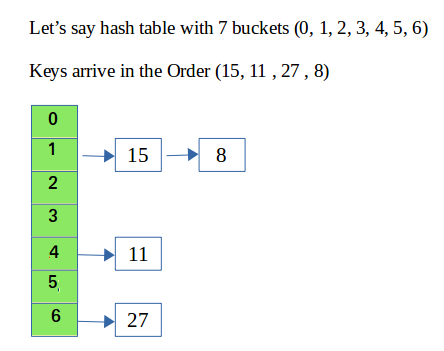
Enstringmiento
Durante el hash, la función hash puede provocar una colisión en la que dos o más claves se asignan al mismo valor. El hash de string evita la colisión. La idea es hacer que cada celda de la tabla hash apunte a una lista vinculada de registros que tienen el mismo valor de función hash.
Nota: En el sondeo lineal, cada vez que se produce una colisión, sondeamos hasta el siguiente espacio vacío. Mientras que en el sondeo cuadrático, cada vez que ocurre una colisión, buscamos un i^2thespacio en la i-ésima iteración y seguimos sondeando hasta que se encuentra un espacio vacío en la tabla hash.
Rendimiento de hashing
El rendimiento del hashing se evalúa sobre la base de que es igualmente probable que cada clave tenga un hash para cualquier ranura de la tabla hash.
m = Length of Hash Table n = Total keys to be inserted in the hash table Load factor lf = n/m Expected time to search = O(1 +lf ) Expected time to insert/delete = O(1 + lf) The time complexity of search insert and delete is O(1) if lf is O(1)
Implementación Python de hashing
# Function to display hashtable
def display_hash(hashTable):
for i in range(len(hashTable)):
print(i, end = " ")
for j in hashTable[i]:
print("-->", end = " ")
print(j, end = " ")
print()
# Creating Hashtable as
# a nested list.
HashTable = [[] for _ in range(10)]
# Hashing Function to return
# key for every value.
def Hashing(keyvalue):
return keyvalue % len(HashTable)
# Insert Function to add
# values to the hash table
def insert(Hashtable, keyvalue, value):
hash_key = Hashing(keyvalue)
Hashtable[hash_key].append(value)
# Driver Code
insert(HashTable, 10, 'Allahabad')
insert(HashTable, 25, 'Mumbai')
insert(HashTable, 20, 'Mathura')
insert(HashTable, 9, 'Delhi')
insert(HashTable, 21, 'Punjab')
insert(HashTable, 21, 'Noida')
display_hash (HashTable)
Producción:
0 --> Allahabad --> Mathura 1 --> Punjab --> Noida 2 3 4 5 --> Mumbai 6 7 8 9 --> Delhi
Publicación traducida automáticamente
Artículo escrito por simranjenny84 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA