Requisito previo: hashing
Un sistema distribuido es una red que consta de computadoras autónomas que están conectadas mediante un middleware de distribución. Ayudan a compartir diferentes recursos y capacidades para proporcionar a los usuarios una red coherente única e integrada.
Una de las formas en que se puede implementar el hashing en un sistema distribuido es tomando Modulo hash de varios Nodes.
La función hash se puede definir como node_number = hash(key)mod_N donde N es el número de Nodes.
Para agregar/recuperar una clave al/desde el Node, el cliente calcula el valor hash de esa clave y usa el resultado para contactar al Node apropiado buscando su dirección IP. Si se encuentra la clave, se recupera; de lo contrario, se agrega al grupo de Node.
Por ejemplo, un cliente quiere recuperar 1. Su valor hash = 7739. Irá al número de Node (7739%3). Por lo tanto, se pondrá en contacto con el Node 2. Si no se encuentra la clave, se agrega al grupo.
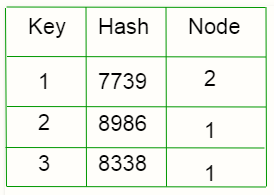
Desventaja: El problema de Rehashing.
Supongamos que el número de Nodes ha cambiado. Como las claves se distribuyen según la cantidad de Nodes, dado que la cantidad de Nodes ha cambiado, el valor de la función hash cambiará, por lo que las claves se redistribuirán.
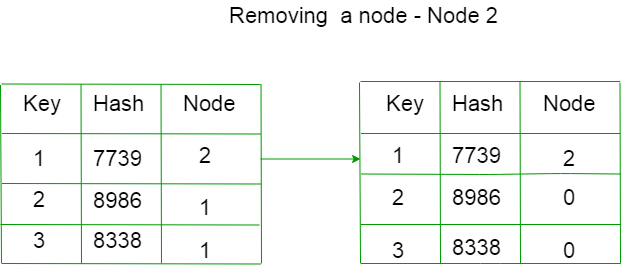
Por ejemplo, eliminemos C.
Los Nodes asignados para cada tecla han cambiado.
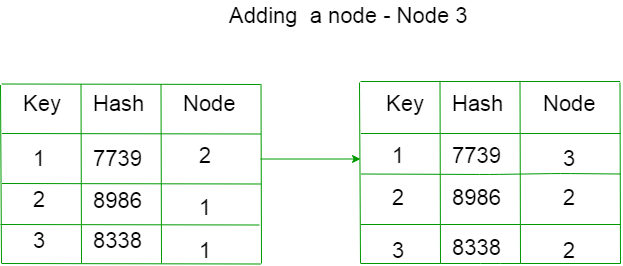
For example, let’s add a new node D
The allocated nodes for each key has changed.
So, the distribution changes whenever we change the number of Nodes.
Lo que sucede es que a mayor cantidad de redistribuciones, mayor cantidad de errores, mayor cantidad de recuperaciones de memoria, lo que coloca una carga adicional en el Node y, por lo tanto, disminuye el rendimiento.
Hashing consistente.
El problema anterior se puede resolver mediante Hashing consistente .
Este método opera independientemente del número de Nodes ya que la función hash no depende del número de Nodes. Aquí asumimos que se forma una string/anillo y colocamos las llaves y los Nodes en el anillo y los distribuimos.
El valor hash se puede calcular como position_on_chain = hash(key)mod_360
(Se elige 360 porque estamos representando cosas en un círculo. Y un círculo tiene 360 grados).
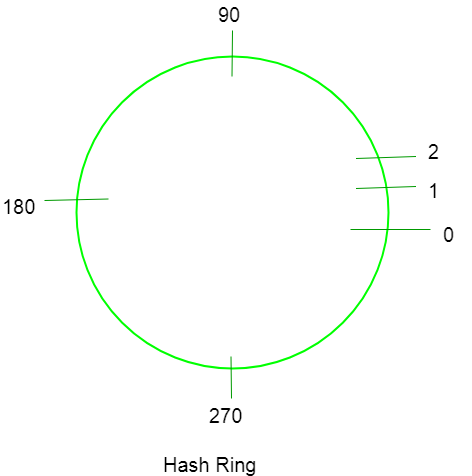
Steps for the arrangement –
1) Encuentre los valores hash de las claves y colóquelos en el anillo de acuerdo con el valor hash.
2) Encuentre los valores hash de los Nodes individuales y colóquelos en el anillo de acuerdo con el valor hash.
3) Ahora asigne cada clave con el Node que está más cerca de ella en el sentido contrario a las agujas del reloj.
4) Si la posición de un Node y una clave es la misma, asigne esa clave al Node.
Entonces, ahora para ubicar un Node, simplemente atravesaremos el anillo desde el punto de la posición de la llave hasta que encontremos un Node en la dirección contraria a las manecillas del reloj.
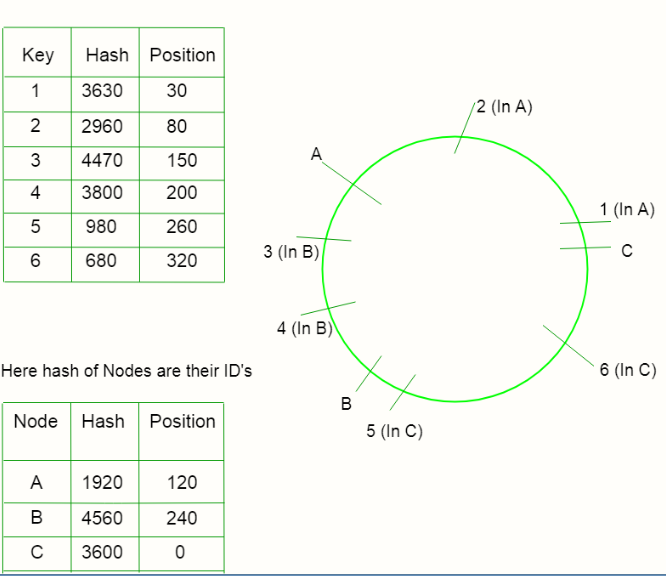
Operations –
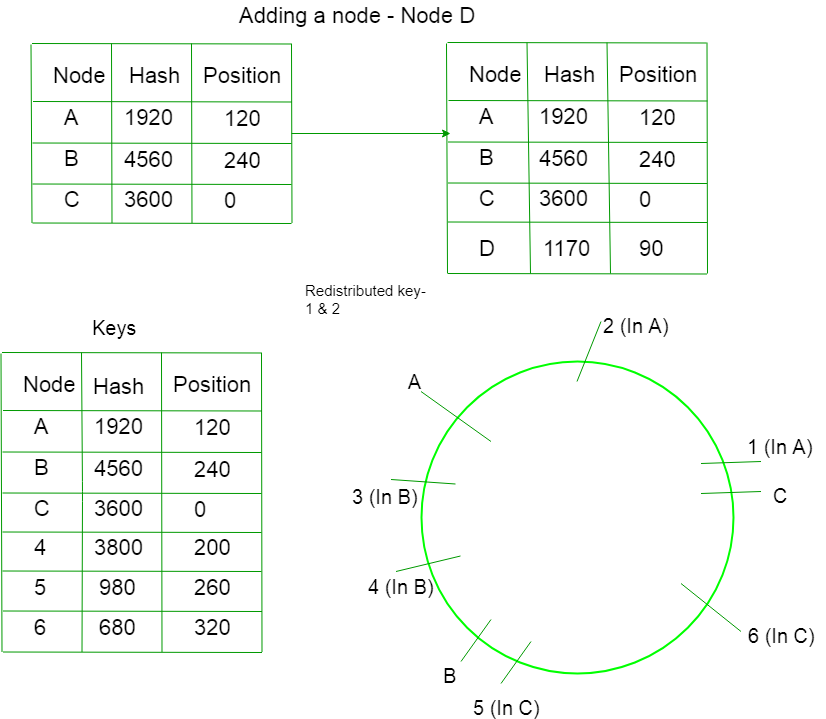
Case 1) Adding a node –
Suppose we add a new node D in the ring by calculating the hash. Only those keys will be redistributed whose values lie between the D and C. Now they will not point towards A, they will point towards D.
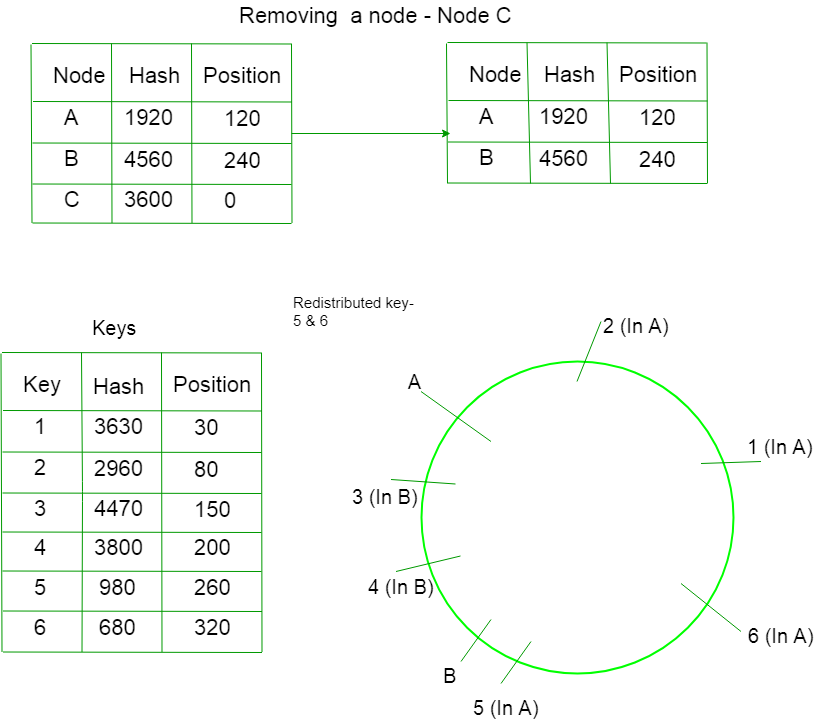
Caso 2) Eliminación de un Node –
Supongamos que eliminamos un Node C del anillo. Solo se redistribuirán aquellas claves cuyos valores se encuentren entre la C y la B. Ahora no apuntarán hacia la C, apuntarán hacia la A.
Así es como el hashing consistente resuelve el problema del rehashing. Se minimiza la cantidad de claves que deben redistribuirse después de la repetición. Por lo tanto, menos cantidad de recuperaciones de memoria. Por lo tanto, se optimiza el rendimiento.
Publicación traducida automáticamente
Artículo escrito por akisonlyforu y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA