Cuando las personas comienzan a aprender sobre aprendizaje automático y ciencia de datos, un hecho/observación que siempre escucharán es que ajustar los modelos de aprendizaje automático a un conjunto de datos es fácil, pero preparar el conjunto de datos para la tarea no lo es. Al resolver problemas de ML, a menudo se nos pide que sigamos una serie de pasos antes de que podamos encontrar el mejor algoritmo de ML que se ajuste con precisión a nuestro conjunto de datos. Algunos pasos importantes se pueden nombrar como:
- Recopilación de datos: se puede recopilar de varias fuentes, ya sea a partir de datos de la vida real o se puede realizar manualmente.
- Preprocesamiento de conjuntos de datos: después de recopilar los datos sin procesar, debemos convertirlos en una forma significativa, para que los algoritmos puedan interpretarlos bien. También implica una serie de pasos, como: comprender los datos mediante el análisis exploratorio de datos, eliminar los valores faltantes en el conjunto de datos (mediante métodos de imputación/manualmente).
- Ingeniería de características: en la ingeniería de características, implementamos procesos como convertir características categóricas en características numéricas, estandarización, normalización, selección de características utilizando diferentes métodos, como la prueba de chi-cuadrado , utilizando un clasificador de árbol adicional .
- Manejo del desequilibrio en el conjunto de datos: A veces, el conjunto de datos que recopilamos se encuentra en un estado muy desequilibrado. Ajustar cualquier modelo a este tipo de conjunto de datos puede darnos resultados inexactos porque el modelo siempre tiene un sesgo hacia los datos que ocurren con frecuencia dentro del conjunto de datos.
- Elaboración de modelos de línea de base: en esto ajustamos diferentes algoritmos de ML en nuestros datos e intentamos averiguar qué modelo nos da un resultado más preciso.
- Ajuste de hiperparámetros: después de seleccionar el mejor modelo de todos los modelos, ajustamos los hiperparámetros del modelo para aumentar la precisión de nuestro modelo resolviendo el problema de ajuste insuficiente/sobreajuste.
Por lo tanto, podemos concluir que antes de obtener los resultados deseados, tenemos que pasar por muchos pasos diferentes. Hablando en términos de tiempo, alrededor del 80 % del tiempo se consume en la preparación de datos para que el modelo se ajuste a ellos y el 20 % restante se requiere para adaptarse a los algoritmos de ML y hacer predicciones. Por lo tanto, seguramente es una tarea exhaustiva llevar a cabo todas estas tareas, pero qué tal si podemos usar algún método/función/biblioteca para que nuestra tarea se vuelva fácil.
En este artículo, vamos a leer acerca de uno de estos paquetes de Python de código abierto llamado Pywedge .
¿Qué es Pywedge?
Pywedge es un paquete de Python de código abierto y se puede instalar mediante pip, desarrollado por Venkatesh Rengarajan Muthu y puede ayudarnos a automatizar la tarea de escribir código para el preprocesamiento de datos, la visualización de datos, la ingeniería de funciones, el manejo de datos desequilibrados y la creación de una línea de base estándar. modelos, sintonización de hiperparámetros de una manera muy interactiva.
Características de Pywedge:
- Puede hacer 8 tipos diferentes de gráficos interactivos como: gráfico de dispersión, gráfico circular, gráfico de caja, gráfico de barras, histograma, etc.
- Preprocesamiento de datos utilizando métodos interactivos, como el manejo de valores faltantes, la conversión de características categóricas en características numéricas, la estandarización, la normalización, el manejo del desequilibrio de clases, etc.
- Ajusta automáticamente nuestros datos en diferentes algoritmos de ML y nos brinda los 10 mejores modelos de referencia.
- También podemos aplicar el ajuste de hiperparámetros en nuestro modelo deseado.
Usemos esta biblioteca de pywedge para resolver un problema de regresión en el que tenemos que predecir la energía generada por una planta de energía usando el conjunto de datos tomado del Desafío de inteligencia artificial de predicción de energía de la planta de energía de Dockship .
Importación de bibliotecas importantes
Python3
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
Cargando el conjunto de datos de entrenamiento y prueba:
Python
# Loading testing Data
test_data = pd.read_csv("TEST.csv")
# Loading training Data
data = pd.read_csv("TRAIN.csv")
# Printing the shape of train dataset
data.shape
(8000, 5)
Ahora, verificaremos cómo se ve nuestro conjunto de datos usando el método head() y verificaremos parte de su información en el paso siguiente como:
Python
data.head()
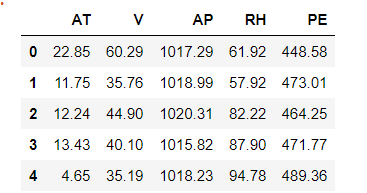
Podemos inferir de la imagen de arriba que nuestro conjunto de datos tiene 5 columnas en las que las primeras cuatro columnas son nuestras características y la última columna (PE) es nuestra columna de destino.
Python
data.info()
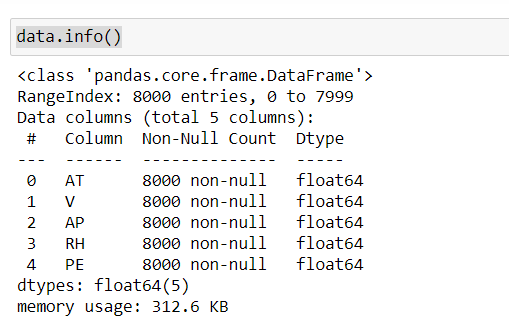
Usando el método info() , podemos interpretar que nuestro conjunto de datos no tiene valores faltantes y que el tipo de datos de cada característica es de tipo float64.
Usando la biblioteca pywedge:
Python
import pywedge as pw ppd = pw.Pre_process_data(data, test_data, y='PE',c=None,type="Regression") new_X, new_y, new_test = ppd.dataframe_clean()
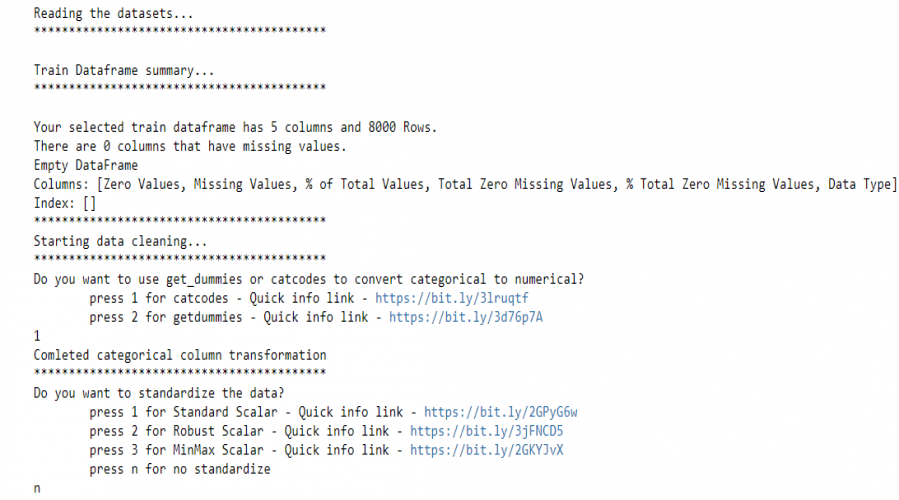
Usamos el método Pre_process_data de pywedge para cargar los datos de entrenamiento y crear un objeto Pre_process_data , el objeto tiene un método dataframe_clean que devuelve datos preprocesados. Este método solicita de forma interactiva métodos para convertir características categóricas en características numéricas y también brinda opciones para elegir diferentes técnicas de estandarización para estandarizar el conjunto de datos.
Preparando modelos de línea de base usando pywedge:
Hacer el tren modificado y los datos de prueba y preparar los modelos de referencia.
Python
# Assigning preprocessed data to make train and test data X_train = new_X y_train = new_y X_test = new_test # calling baseline_model method to prepare all the baseline models blm = pw.baseline_model(X_train,y_train) # printing the regression summary blm.Regression_summary()
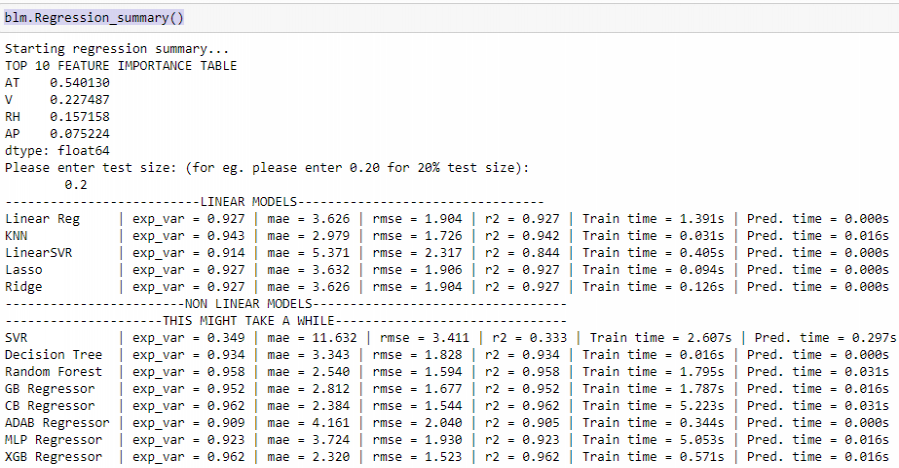
modelos de referencia estándar
El método de línea base_modelo crea un objeto ‘blm’ y el método Regression_summary() devuelve un resumen sobre los modelos implementados. Nos brinda las 10 características más importantes calculadas con el regresor AdaBoost y los mejores modelos de referencia. Además, podemos comprobar qué algoritmo tarda cuánto tiempo en entrenarse y hacer predicciones. También se muestran diferentes métricas con las que evaluamos nuestro modelo. Sin embargo, no realiza ningún ajuste de hiperparámetro, por lo que el mejor modelo puede ajustarse más tarde para obtener resultados más precisos.
Por lo tanto, podemos notar lo rápido que podemos averiguar qué modelo de aprendizaje automático debemos usar para nuestro problema con solo escribir unas pocas líneas de código.
Publicación traducida automáticamente
Artículo escrito por saurabh48782 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA