En este artículo, cubriremos cómo funciona el analizador léxico y también cubriremos la arquitectura básica del analizador léxico. Discutamos uno por uno.
Requisito previo : introducción al analizador léxico
Analizador léxico:
- Es la primera fase de un compilador que se conoce como Scanner (Es escanear el programa).
- Lexical Analyzer dividirá el programa en algunas strings significativas que se conocen como token.
Tipos de token de la siguiente manera:
- identificador
- Palabra clave
- Operador
- constantes
- Símbolo especial(@, $, #)
Arriba está la terminología de token, que es el componente clave para trabajar en Lexical Analyzer. Ahora, con la ayuda del ejemplo, verá cómo funciona.
Consideremos el siguiente programa en C que se proporciona a continuación para comprender el funcionamiento.
int main)(
}
x = y+z;
int x, y, z;
print("Goto GFG %d%d", a);
{
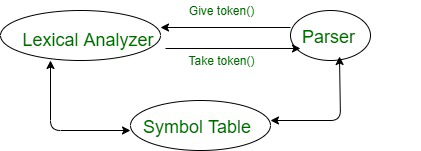
En la primera fase, el compilador no verifica la sintaxis. Entonces, aquí este programa como entrada al analizador léxico y convertirlo en tokens. Entonces, la tokenización es uno de los funcionamientos importantes del analizador léxico.
El número total de fichas para este programa es 26. A continuación se muestra el diagrama de cómo contará la ficha.

En este diagrama anterior, puede verificar y contar la cantidad de tokens y puede comprender cómo funciona la tokenización en la fase del analizador léxico.
Así es como puede comprender cada fase del compilador con claridad y tendrá una idea de cómo funciona el compilador internamente y cada fase del compilador es el paso clave.
Publicación traducida automáticamente
Artículo escrito por Ashish_rana y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA