HTML Parser es un programa/software mediante el cual se pueden extraer declaraciones útiles, dejando atrás las etiquetas html (como <h1>, <span>, <p>, etc.).
Ejemplos:
Entrada: <h1>Geeks for Geeks</h1>
Salida: Geeks for Geeks
Explicación : <h1> y </h1> abren y cierran etiquetas de encabezado, por lo que se analizaron dejando «Geeks for Geeks» como salida.Entrada: <p> Geeks for Geeks</p>
Salida: Geeks for Geeks
Explicación : <p> y </p> abren y cierran etiquetas de párrafo, por lo que se analizan y el analizador ignora el carácter de espacio, dejando «Geeks for Geeks». ” como salida.
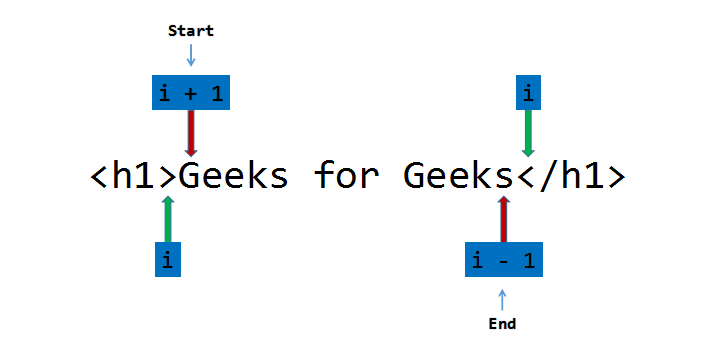
Enfoque: Deje que la string de entrada sea S de tamaño N. Siga los pasos a continuación para resolver el problema:
- Declare dos variables , start y end para señalar el punto inicial y final de la declaración.
- Recorra la string , S usa la variable iy si S[i] es igual a ‘>’, actualice la variable de inicio a i+1 y salga del ciclo .
- Elimine los espacios en blanco desde el principio ejecutando un bucle mientras S[start] es igual a ‘ ‘ e incremente la variable de inicio en 1 en cada iteración.
- Nuevamente, recorra la string, S desde el inicio usando la variable i y si S[i] es igual a ‘<‘, actualice el final a i-1 y salga del ciclo.
- Ejecute un ciclo e imprima los caracteres de la string S en el rango [inicio, fin].
A continuación se muestra la implementación del enfoque anterior en lenguaje C :
// C program for the above approach
#include <stdbool.h>
#include <stdio.h>
#include <string.h>
// Function to parse the HTML code
void parser(char* S)
{
// Store the length of the
// input string
int n = strlen(S);
int start = 0, end = 0;
int i, j;
// Traverse the string
for (i = 0; i < n; i++) {
// If S[i] is '>', update
// start to i+1 and break
if (S[i] == '>') {
start = i + 1;
break;
}
}
// Remove the blank spaces
while (S[start] == ' ') {
start++;
}
// Traverse the string
for (i = start; i < n; i++) {
// If S[i] is '<', update
// end to i-1 and break
if (S[i] == '<') {
end = i - 1;
break;
}
}
// Print the characters in the
// range [start, end]
for (j = start; j <= end; j++) {
printf("%c", S[j]);
}
printf("\n");
}
// Driver Code
int main()
{
// Given Input
char input1[] = "<h1>This is a statement</h1>";
char input2[] = "<h1> This is a statement with some spaces</h1>";
char input3[] = "<p> This is a statement with some @ #$ ., / special characters</p> ";
printf("Parsed Statements:\n");
// Function Call
parser(input1);
parser(input2);
parser(input3);
return 0;
}
Parsed Statements: This is a statement This is a statement with some spaces This is a statement with some @ #$., / special characters
A continuación se muestra la implementación del enfoque anterior en lenguaje C++ :
// C++ program for the
// above approach
#include <bits/stdc++.h>
using namespace std;
// Function to parse the
// HTML code
void parser(char* S)
{
// Store the length of the
// input string
int n = strlen(S);
int start = 0, end = 0;
// Traverse the string
for (int i = 0; i < n; i++) {
// If S[i] is '>', update
// start to i+1 and break
if (S[i] == '>') {
start = i + 1;
break;
}
}
// Remove the blank space
while (S[start] == ' ') {
start++;
}
// Traverse the string
for (int i = start; i < n; i++) {
// If S[i] is '<', update
// end to i-1 and break
if (S[i] == '<') {
end = i - 1;
break;
}
}
// Print the characters in the
// range [start, end]
for (int j = start; j <= end; j++) {
cout << S[j];
}
cout << endl;
}
// Driver Code
int main()
{
// Given Input
char input1[] = "<h1>This is a statement</h1>";
char input2[] = "<h1> This is a statement with some spaces</h1>";
char input3[] = "<p> This is a statement with some @ #$ ., / special characters</p> ";
cout << "Parsed Statements:\n";
// Function Call
parser(input1);
parser(input2);
parser(input3);
return 0;
}
Parsed Statements: This is a statement This is a statement with some spaces This is a statement with some @ #$., / special characters
Tiempo Complejidad :O(N)
Espacio Auxiliar : O(1)
Nota: este programa analiza solo una declaración a la vez.