Es una utilidad o característica que viene con una distribución de Hadoop que permite a los desarrolladores o programadores escribir el programa Map-Reduce usando diferentes lenguajes de programación como Ruby, Perl, Python, C++, etc. Podemos usar cualquier lenguaje que pueda leer desde el estándar. entrada (STDIN) como entrada de teclado y todo y escribir usando salida estándar (STDOUT). Todos sabemos que Hadoop Framework está completamente escrito en Java, pero los programas para Hadoop no necesariamente necesitan codificarse en el lenguaje de programación Java. La característica de Hadoop Streaming está disponible desde la versión 0.14.1 de Hadoop.
Cómo funciona la transmisión de Hadoop
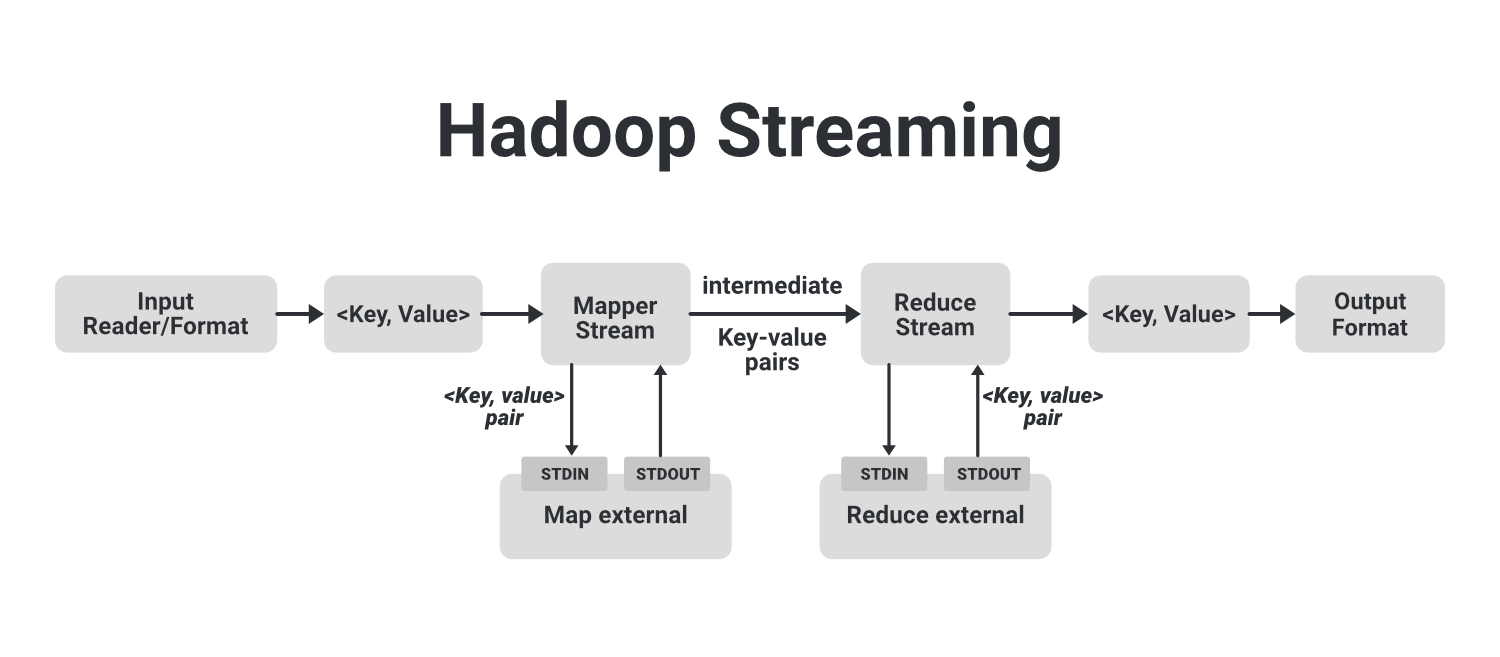
En la imagen de ejemplo anterior, podemos ver que el flujo que se muestra en un bloque punteado es un trabajo básico de MapReduce. En eso, tenemos un Input Reader que es responsable de leer los datos de entrada y produce la lista de pares clave-valor. Podemos leer datos en formato .csv, en formato delimitador, desde una tabla de base de datos, datos de imagen (.jpg, .png), datos de audio, etc. El único requisito para leer todo este tipo de datos es que tenemos que crear un formato de entrada para esos datos con estos lectores de entrada. El lector de entrada contiene la lógica completa sobre los datos que está leyendo. Supongamos que queremos leer una imagen, luego tenemos que especificar la lógica en el lector de entrada para que pueda leer los datos de esa imagen y finalmente generará pares clave-valor para esos datos de imagen.
Si estamos leyendo los datos de una imagen, podemos generar un par clave-valor para cada píxel, donde la clave será la ubicación del píxel y el valor será su valor de color de (0-255) para una imagen en color. Ahora, esta lista de pares clave-valor se envía a la fase de mapa y Mapper trabajará en cada uno de estos pares clave-valor de cada píxel y generará algunos pares clave-valor intermedios que luego se envían al reductor después de barajar y clasificar. la salida final producida por el reductor se escribirá en el HDFS. Así es como funciona un trabajo Map-Reduce simple.
Ahora veamos cómo podemos usar diferentes lenguajes como Python, C++, Ruby con Hadoop para la ejecución. Podemos ejecutar este lenguaje arbitrario ejecutándolos como un proceso separado. Para eso, crearemos nuestro mapeador externo y lo ejecutaremos como un proceso externo separado. Estos procesos de mapas externos no forman parte del flujo básico de MapReduce. Este mapeador externo tomará la entrada de STDIN y producirá una salida a STDOUT. A medida que los pares clave-valor se pasan al mapeador interno, el proceso del mapeador interno enviará estos pares clave-valor al mapeador externo donde hemos escrito nuestro código en algún otro lenguaje como Python con la ayuda de STDIN. Ahora, estos mapeadores externos procesan estos pares clave-valor y generan pares clave-valor intermedios con la ayuda de STDOUT y los envían a los mapeadores internos.
Del mismo modo, Reducer hace lo mismo. Una vez que los pares clave-valor intermedios se procesan a través del proceso de reproducción aleatoria y clasificación, se envían al reductor interno, que enviará estos pares al proceso reductor externo que funciona por separado con la ayuda de STDIN y recopila la salida generada por los reductores externos con ayuda. de STDOUT y finalmente la salida se almacena en nuestro HDFS.
Así es como funciona Hadoop Streaming en Hadoop, que está disponible de forma predeterminada en Hadoop. Solo estamos utilizando esta función al hacer nuestro mapeador externo y reductores. Ahora podemos ver cuán poderosa es la función de transmisión de Hadoop. Cualquiera puede escribir su código en cualquier idioma de su elección.
Algunos comandos de transmisión de Hadoop
|
Opción |
Descripción |
|---|---|
| -introduzca nombre_directorio o nombre de archivo | Ubicación de entrada para el mapeador. |
| -salida nombre_directorio | Ubicación de entrada para el reductor. |
| -mapper ejecutable o JavaClassName | El comando que se ejecutará como el mapeador |
| -reductor ejecutable o secuencia de comandos o JavaClassName | El comando que se ejecutará como el reductor |
| -archivo nombre-archivo | Haga que el ejecutable del mapeador, reductor o combinador esté disponible localmente en los Nodes de cómputo |
| -formato de entrada nombre de clase Java | De forma predeterminada, TextInputformat se usa para devolver el par clave-valor de la clase Text. Podemos especificar nuestra clase, pero eso también debería devolver un par clave-valor. |
| -formato de salida Nombre de clase Java | De forma predeterminada, TextOutputformat se usa para tomar pares clave-valor de la clase Text. Podemos especificar nuestra clase, pero eso también debería tomar un par clave-valor. |
| -partitioner JavaClassName | La clase que determina qué clave reducir. |
| -combiner streamingCommand o JavaClassName | El ejecutable Combiner para la salida del mapa |
| -verboso | La salida detallada. |
| -numReduceTasks | Especifica el número de reductores. |
| -mapdebug | Script para llamar cuando falla la tarea del mapa |
| -depuración reducida | Script para llamar cuando falla la tarea de reducción |
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA