En este artículo, aprenderemos el qué, el por qué y el cómo de los subprocesos múltiples y el procesamiento múltiple en Python. Antes de sumergirnos en el código, comprendamos qué significan estos términos.
- Un programa es un archivo ejecutable que consiste en un conjunto de instrucciones para realizar alguna tarea y generalmente se almacena en el disco de su computadora.
- Un proceso es lo que llamamos un programa que se ha cargado en la memoria junto con todos los recursos que necesita para funcionar. Tiene su propio espacio de memoria.
- Un hilo es la unidad de ejecución dentro de un proceso. Un proceso puede tener múltiples subprocesos ejecutándose como parte de él, donde cada subproceso usa el espacio de memoria del proceso y lo comparte con otros subprocesos.
- El subproceso múltiple es una técnica en la que un proceso genera múltiples subprocesos para realizar diferentes tareas, aproximadamente al mismo tiempo, solo uno tras otro. Esto le da la ilusión de que los subprocesos se ejecutan en paralelo, pero en realidad se ejecutan de manera concurrente. En Python, Global Interpreter Lock (GIL) evita que los subprocesos se ejecuten simultáneamente.
- El multiprocesamiento es una técnica en la que se logra el paralelismo en su forma más auténtica. Se ejecutan múltiples procesos en múltiples núcleos de CPU, que no comparten los recursos entre ellos. Cada proceso puede tener muchos subprocesos ejecutándose en su propio espacio de memoria. En Python, cada proceso tiene su propia instancia de intérprete de Python que realiza el trabajo de ejecutar las instrucciones.
Ahora, saltemos al programa donde intentamos ejecutar dos tipos diferentes de funciones: vinculadas a IO y vinculadas a CPU de seis maneras diferentes. Dentro de la función vinculada a IO, le pedimos a la CPU que permanezca inactiva y pase el tiempo mientras que, dentro de la función vinculada a la CPU, la CPU estará ocupada produciendo algunos números.
Requisitos:
- Una computadora con Windows (Mi máquina tiene 6 núcleos).
- Python 3.x instalado.
- Cualquier editor de texto/IDE para escribir programas en Python (estoy usando Sublime Text aquí).
Nota: A continuación se muestra la estructura de nuestro programa, que será común en las seis partes. En el lugar donde se menciona # YOUR CODE SNIPPET HERE, reemplázalo con el fragmento de código de cada parte a medida que avanzas.
import time, os
from threading import Thread, current_thread
from multiprocessing import Process, current_process
COUNT = 200000000
SLEEP = 10
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
def cpu_bound(n):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start counting...")
while n>0:
n -= 1
print(f"{pid} * {processName} * {threadName} \
---> Finished counting...")
if __name__=="__main__":
start = time.time()
# YOUR CODE SNIPPET HERE
end = time.time()
print('Time taken in seconds -', end - start)
Parte 1: Ejecutar la tarea enlazada a IO dos veces, una tras otra…
# Code snippet for Part 1 io_bound(SLEEP) io_bound(SLEEP)
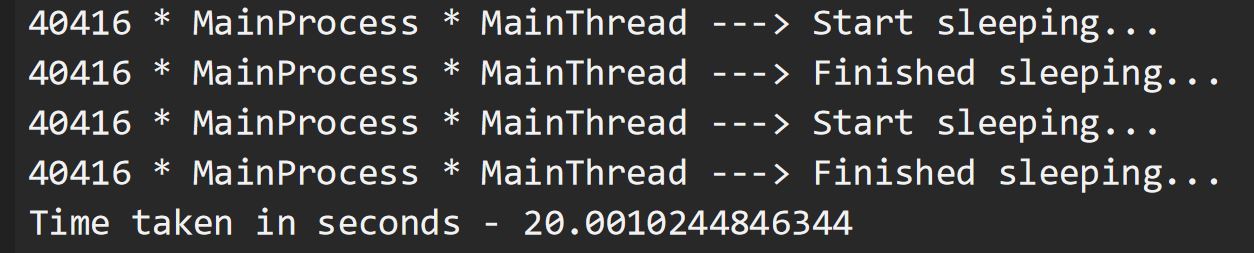
Aquí, le pedimos a nuestra CPU que ejecute la función io_bound(), que toma un número entero (10, aquí) como parámetro y le pide a la CPU que duerma durante esa cantidad de segundos. Esta ejecución tarda un total de 20 segundos, ya que la ejecución de cada función tarda 10 segundos en completarse. Tenga en cuenta que es el mismo MainProcess el que llama a nuestra función dos veces, una tras otra, utilizando su subproceso predeterminado, MainThread.
Parte 2: uso de subprocesos para ejecutar las tareas vinculadas a IO…
# Code snippet for Part 2 t1 = Thread(target = io_bound, args =(SLEEP, )) t2 = Thread(target = io_bound, args =(SLEEP, )) t1.start() t2.start() t1.join() t2.join()
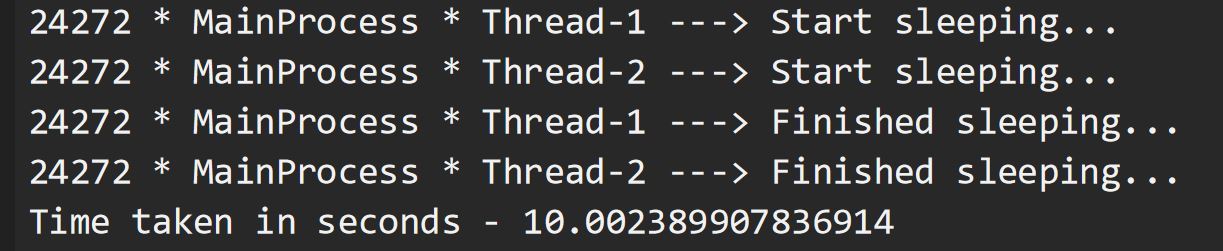
Aquí, usemos subprocesos en Python para acelerar la ejecución de las funciones. Los hilos Thread-1 y Thread-2 son iniciados por nuestro MainProcess, cada uno de los cuales llama a nuestra función, casi al mismo tiempo. Ambos subprocesos completan su trabajo de dormir durante 10 segundos, al mismo tiempo. Esto redujo el tiempo total de ejecución de todo nuestro programa en un significativo 50%. Por lo tanto, los subprocesos múltiples son la solución ideal para ejecutar tareas en las que el tiempo de inactividad de nuestra CPU se puede utilizar para realizar otras tareas. Por lo tanto, ahorra tiempo al hacer uso del tiempo de espera.
Parte 3: Ejecutar la tarea vinculada a la CPU dos veces, una tras otra…
# Code snippet for Part 3 cpu_bound(COUNT) cpu_bound(COUNT)
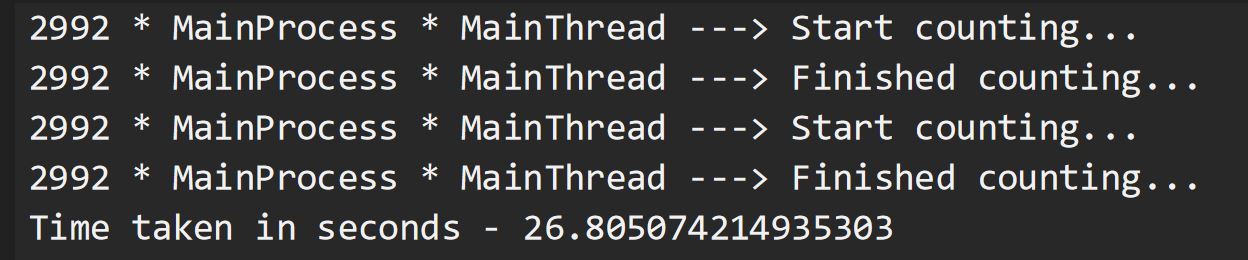
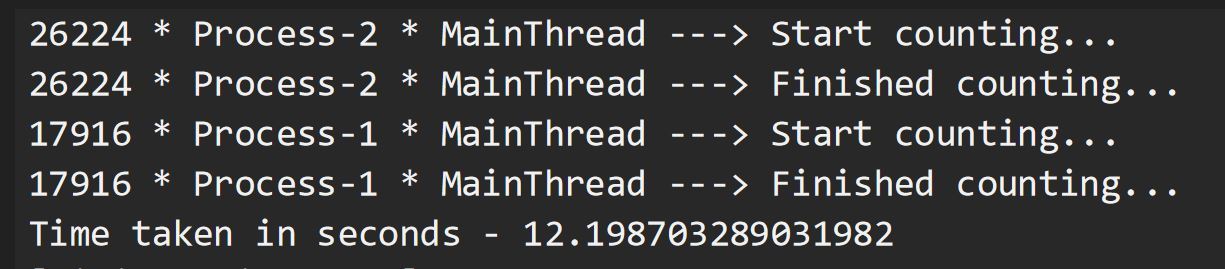
Aquí, llamaremos a nuestra función cpu_bound(), que toma un número grande (200000000, here)como parámetro y lo decrementa en cada paso hasta que es cero. Se le pide a nuestra CPU que haga la cuenta regresiva en cada llamada de función, lo que toma alrededor de 12 segundos (este número puede diferir en su máquina). Por lo tanto, la ejecución de todo el programa tardó unos 26 segundos en completarse. Tenga en cuenta que, una vez más, nuestro MainProcess llama a la función dos veces, una tras otra, en su subproceso predeterminado, MainThread.
Parte 4: ¿Pueden los subprocesos acelerar nuestras tareas vinculadas a la CPU?
# Code snippet for Part 4 t1 = Thread(target = cpu_bound, args =(COUNT, )) t2 = Thread(target = cpu_bound, args =(COUNT, )) t1.start() t2.start() t1.join() t2.join()
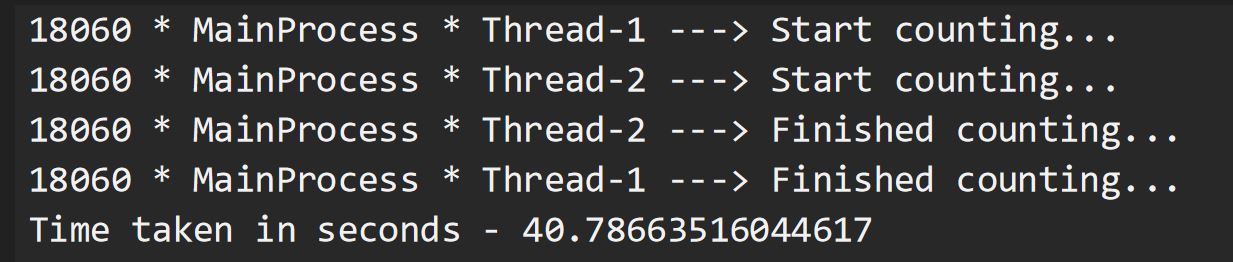
De acuerdo, acabamos de demostrar que los subprocesos funcionaron sorprendentemente bien para múltiples tareas vinculadas a IO. Usemos el mismo enfoque para ejecutar nuestras tareas vinculadas a la CPU. Bueno, inició nuestros subprocesos al mismo tiempo inicialmente, pero al final, ¡vemos que la ejecución completa del programa tomó alrededor de 40 segundos! ¿Lo que acaba de suceder? Esto se debe a que cuando se inició Thread-1, adquirió el Bloqueo de intérprete global (GIL) que impidió que Thread-2 hiciera uso de la CPU. Por lo tanto, Thread-2 tuvo que esperar a que Thread-1 terminara su tarea y liberara el bloqueo para que pudiera adquirir el bloqueo y realizar su tarea. Esta adquisición y liberación del bloqueo agregó una sobrecarga al tiempo total de ejecución. Por lo tanto, podemos decir con seguridad que la creación de subprocesos no es una solución ideal para tareas que requieren que la CPU funcione en algo.
Parte 5: Entonces, ¿funciona dividir las tareas como procesos separados?
# Code snippet for Part 5 p1 = Process(target = cpu_bound, args =(COUNT, )) p2 = Process(target = cpu_bound, args =(COUNT, )) p1.start() p2.start() p1.join() p2.join()
Vamos a cortar por lo sano. El multiprocesamiento es la respuesta. Aquí, MainProcess hace girar dos subprocesos, que tienen diferentes PID, cada uno de los cuales hace el trabajo de reducir el número a cero. Cada proceso se ejecuta en paralelo, haciendo uso de un núcleo de CPU separado y su propia instancia del intérprete de Python, por lo tanto, la ejecución completa del programa tomó solo 12 segundos. Tenga en cuenta que la salida puede imprimirse de forma desordenada ya que los procesos son independientes entre sí. Cada proceso ejecuta la función en su propio subproceso predeterminado, MainThread. Abra su Administrador de tareas durante la ejecución de su programa. Puede ver 3 instancias del intérprete de Python, una para MainProcess, Process-1 y Process-2. También puede ver que durante la ejecución del programa, el uso de energía de los dos subprocesos es «Muy alto»,

Parte 6: Oye, usemos el multiprocesamiento para nuestras tareas vinculadas a IO…
# Code snippet for Part 6 p1 = Process(target = io_bound, args =(SLEEP, )) p2 = Process(target = io_bound, args =(SLEEP, )) p1.start() p2.start() p1.join() p2.join()
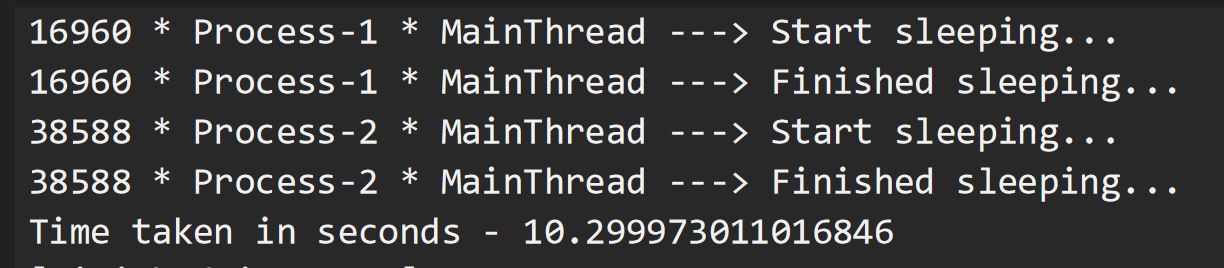
Ahora que tenemos una idea clara sobre cómo el multiprocesamiento nos ayuda a lograr el paralelismo, intentaremos usar esta técnica para ejecutar nuestras tareas vinculadas a IO. Sí observamos que los resultados son extraordinarios, al igual que en el caso del multihilo. Dado que los procesos Process-1 y Process-2 están realizando la tarea de pedir a su propio núcleo de CPU que permanezca inactivo durante unos segundos, no encontramos un uso de energía alto. Pero la creación de procesos en sí es una tarea pesada para la CPU y requiere más tiempo que la creación de subprocesos. Además, los procesos requieren más recursos que los hilos. Por lo tanto, siempre es mejor tener el multiprocesamiento como la segunda opción para las tareas vinculadas a IO, siendo el multiproceso la primera.

Bueno, eso fue todo un paseo. Vimos seis enfoques diferentes para realizar una tarea, que tomó aproximadamente unos 10 segundos, según si la tarea es liviana o pesada en la CPU.
En resumen: subprocesos múltiples para tareas vinculadas a IO. Multiprocesamiento para tareas vinculadas a la CPU.
Publicación traducida automáticamente
Artículo escrito por varunkumar032 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA