No siempre es posible obtener el conjunto de datos en formato CSV. Entonces, Pandas nos proporciona las funciones para convertir conjuntos de datos en otros formatos al marco de datos. Un archivo de Excel tiene un formato ‘.xlsx’.
Antes de comenzar, necesitamos instalar algunas bibliotecas.
pip install pandas pip install xlrd
Para importar un archivo de Excel a Python usando Pandas, tenemos que usar la función pandas.read_excel() .
Sintaxis: pandas.read_excel( io , sheet_name=0 , header=0 , names=Ninguno ,….)
Retorno: DataFrame o dictado de DataFrames.
Supongamos que el archivo de Excel se ve así:
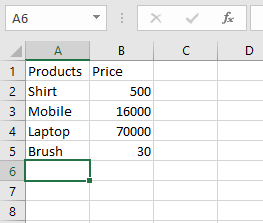
Ahora, podemos sumergirnos en el código.
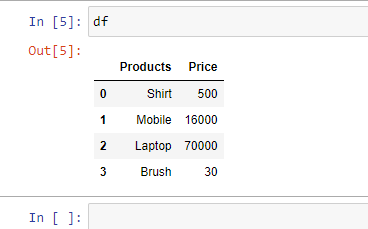
Ejemplo 1: leer un archivo de Excel.
Python3
import pandas as pd
df = pd.read_excel("sample.xlsx")
print(df)
Producción:
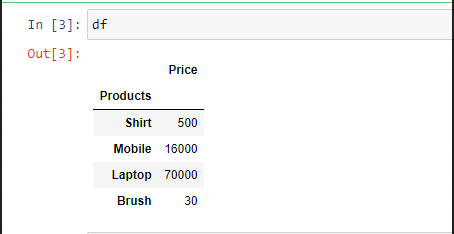
Ejemplo 2: Para seleccionar una columna en particular, podemos pasar un parámetro » index_col «.
Python3
import pandas as pd
# Here 0th column will be extracted
df = pd.read_excel("sample.xlsx",
index_col = 0)
print(df)
Producción:
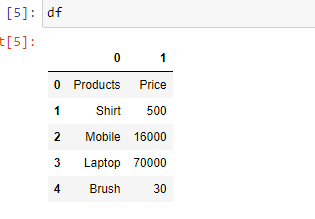
Ejemplo 3: En caso de que no prefieras el encabezado inicial de las columnas, puedes cambiarlo a índices usando el parámetro “ header”.
Python3
import pandas as pd
df = pd.read_excel('sample.xlsx',
header = None)
print(df)
Producción:
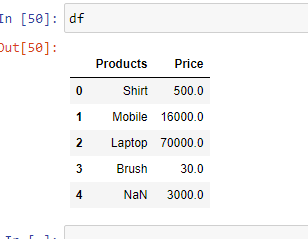
Ejemplo 4: si desea cambiar el tipo de datos de una columna en particular, puede hacerlo usando el parámetro » dtype «.
Python3
import pandas as pd
df = pd.read_excel('sample.xlsx',
dtype = {"Products": str,
"Price":float})
print(df)
Producción:
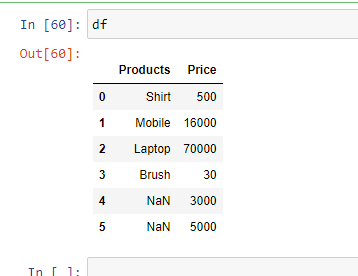
Ejemplo 5: en caso de que tenga valores desconocidos, puede manejarlos usando el parámetro » na_values «. Convertirá los valores desconocidos mencionados en » NaN «.
Python3
import pandas as pd
df = pd.read_excel('sample.xlsx',
na_values =['item1',
'item2'])
print(df)
Producción:
Publicación traducida automáticamente
Artículo escrito por ayushmankumar7 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA