Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos.
A veces, el archivo csv tiene valores nulos, que luego se muestran como NaN en el marco de datos. Al igual que el dropna()método pandas administra y elimina valores nulos de un marco de datos, fillna()administra y permite que el usuario reemplace los valores NaN con algún valor propio.
Sintaxis:
DataFrame.fillna(valor=Ninguno, método=Ninguno, eje=Ninguno, en el lugar=Falso, límite=Ninguno, downcast=Ninguno, **kwargs)
Parámetros:
valor: estático, diccionario, array, serie o marco de datos para llenar en lugar de NaN.
método: el método se usa si el usuario no pasa ningún valor. Pandas tiene diferentes métodos comobfill,backfilloffillque llena el lugar con valor en el índice Adelante o Anterior/Atrás respectivamente.
eje: el eje toma un valor int o de string para filas/columnas. La entrada puede ser 0 o 1 para Integer y ‘index’ o ‘columns’ para String
inplace: es un booleano que hace los cambios en el marco de datos si es True.
limit : Este es un valor entero que especifica el número máximo de rellenos consecutivos de valor de NaN hacia adelante/hacia atrás.
abatido:Se necesita un dictado que especifica qué dtype abatir a cuál. Como Float64 a int64.
**kwargs: cualquier otro argumento de palabra clave
Para obtener un enlace al archivo CSV utilizado en el código, haga clic aquí .
Ejemplo #1: Reemplazar los valores de NaN con un valor estático.
Antes de reemplazar:
# importing pandas module
import pandas as pd
# making data frame from csv file
nba = pd.read_csv("nba.csv")
nba
Producción: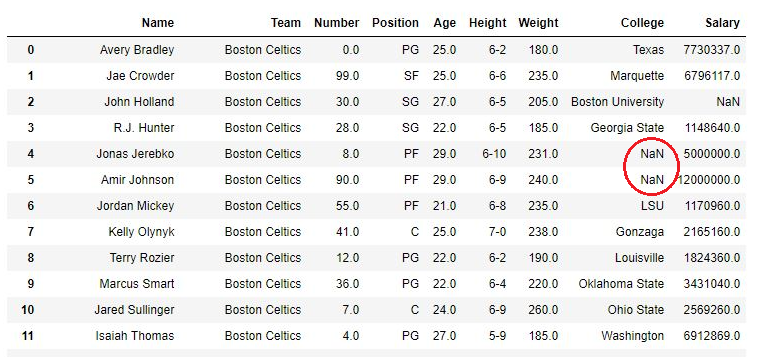
Después de reemplazar:
En el siguiente ejemplo, todos los valores nulos en la columna Universidad se reemplazaron con la string «Sin universidad». En primer lugar, el marco de datos se importa de CSV y luego se selecciona la columna College y fillna()se usa el método en ella.
# importing pandas module
import pandas as pd
# making data frame from csv file
nba = pd.read_csv("nba.csv")
# replacing na values in college with No college
nba["College"].fillna("No College", inplace = True)
nba
Producción: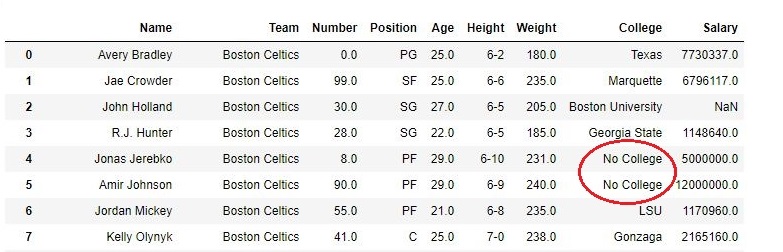
Ejemplo #2: Uso del parámetro del método
En el siguiente ejemplo, el método se establece como relleno y, por lo tanto, el valor en la misma columna reemplaza el valor nulo. En este caso , el estado de Georgia reemplazó el valor nulo en la columna de la universidad de las filas 4 y 5.
De manera similar, también se pueden usar los métodos bfill, backfill y pad.
# importing pandas module
import pandas as pd
# making data frame from csv file
nba = pd.read_csv("nba.csv")
# replacing na values in college with No college
nba["College"].fillna( method ='ffill', inplace = True)
nba
Producción: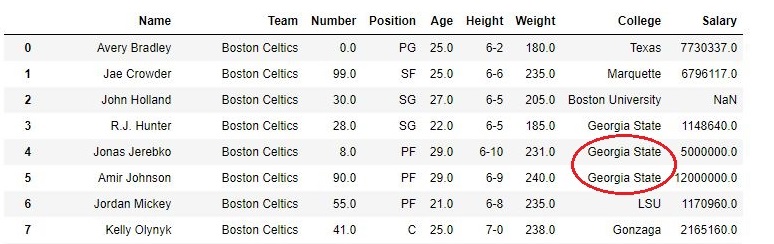
Ejemplo n.º 3: uso del límite
En este ejemplo, se establece un límite de 1 en el método fillna() para verificar si la función deja de reemplazar después de un reemplazo exitoso del valor de NaN o no.
# importing pandas module
import pandas as pd
# making data frame from csv file
nba = pd.read_csv("nba.csv")
# replacing na values in college with No college
nba["College"].fillna( method ='ffill', limit = 1, inplace = True)
nba
Salida:
como se muestra en la salida, la columna de la universidad de la cuarta fila se reemplazó, pero la quinta no, ya que el límite se estableció en 1.
Publicación traducida automáticamente
Artículo escrito por Kartikaybhutani y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA