En Machine Learning, el modelo requiere un conjunto de datos para operar, es decir, para entrenar y probar. Pero los datos no vienen completamente preparados y listos para usar. Hay discrepancias como valores «Nan»/»Nulo»/»NA» en muchas filas y columnas. A veces, el conjunto de datos también contiene algunas de las filas y columnas que ni siquiera son necesarias en la operación de nuestro modelo. En tales condiciones, requiere una limpieza y modificación adecuadas del conjunto de datos para que sea una entrada eficiente para nuestro modelo. Logramos eso practicando » Disputas de datos » antes de ingresar datos al modelo.
Ok, vamos a sumergirnos en la parte de programación. Nuestro primer objetivo es crear un marco de datos de Pandas en Python, como sabrá, pandas es una de las bibliotecas de Python más utilizadas.
Ejemplo:
Python3
# importing the pandas library import pandas as pd # creating a dataframe object student_register = pd.DataFrame() # assigning values to the # rows and columns of the # dataframe student_register['Name'] = ['Abhijit', 'Smriti', 'Akash', 'Roshni'] student_register['Age'] = [20, 19, 20, 14] student_register['Student'] = [False, True, True, False] student_register
Producción:
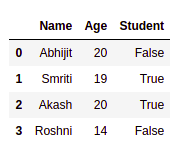
Como puede ver, el objeto del marco de datos tiene cuatro filas [0, 1, 2, 3] y tres columnas [“Nombre”, “Edad”, “Estudiante”] respectivamente. La columna que contiene los valores de índice, es decir, [0, 1, 2, 3] se conoce como la columna de índice , que es una parte predeterminada en el datagrama de pandas. También podemos cambiar eso según nuestro requisito porque Python es poderoso.
A continuación, por alguna razón, queremos agregar un nuevo estudiante en el datagrama, es decir, desea agregar una nueva fila a su marco de datos existente, eso se puede lograr con el siguiente fragmento de código.
Un concepto importante es que el objeto de «marco de datos» de Python consiste en filas que, en cambio, son objetos de «serie», que se apilan para formar una tabla. Por lo tanto, agregar una nueva fila significa crear un nuevo objeto de serie y agregarlo al marco de datos.
Ejemplo:
Python3
# creating a new pandas # series object new_person = pd.Series(['Mansi', 19, True], index = ['Name', 'Age', 'Student']) # using the .append() function # to add that row to the dataframe student_register.append(new_person, ignore_index = True)
Producción:
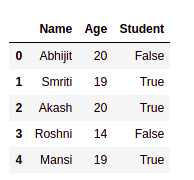
Antes de procesar y discutir los datos, necesita obtener una descripción general total de los mismos, que incluye conclusiones estadísticas como la desviación estándar (std), la media y sus distribuciones de cuartiles . Además, necesita saber la información exacta de cada columna, es decir, qué tipo de valor almacena y cuántos de ellos son únicos. Hay tres funciones de soporte, .shape, .info() y .describe(), que generan la forma de la tabla, información sobre filas y columnas e información estadística del marco de datos (solo columna numérica) respectivamente.
Ejemplo:
Python3
# for showing the dimension
# of the dataframe
print('Shape')
print(student_register.shape)
# showing info about the data
print("\n\nInfo\n")
student_register.info()
# for showing the statistical
# info of the dataframe
print("\n\nDescribe")
student_register.describe()
Producción:
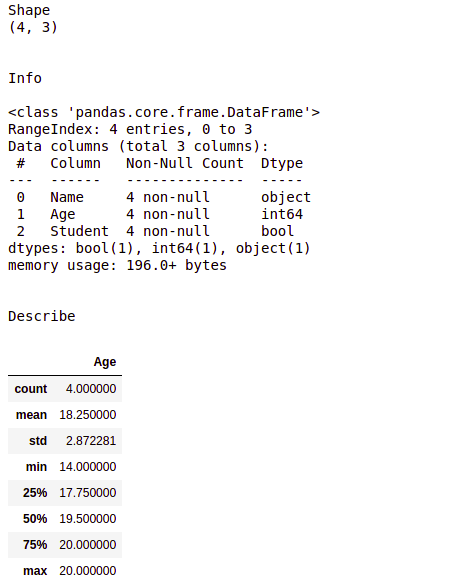
En el ejemplo anterior, la función .shape da una salida (4, 3) ya que ese es el tamaño del marco de datos creado.
La descripción de la salida proporcionada por el método .info() es la siguiente:
- “RangeIndex” describe la columna de índice, es decir, [0, 1, 2, 3] en nuestro datagrama. Cuál es el número de filas en nuestro marco de datos.
- Como sugiere el nombre, «Columnas de datos» proporciona el número total de columnas como salida.
- «Nombre», «Edad», «Estudiante» son los nombres de las columnas en nuestros datos, «no nulo» nos dice que en la columna correspondiente, no existe ningún valor NA/Nan/Ninguno. «objeto», «int64» y «bool» son los tipos de datos que tiene cada columna.
- «dtype» le brinda una descripción general de cuántos tipos de datos están presentes en el datagrama, lo que en términos simplifica el proceso de limpieza de datos.
Además, en los modelos de aprendizaje automático de alta gama, el «uso de la memoria» es un término importante, no podemos pasarlo por alto.
La descripción de la salida proporcionada por el método .describe() es la siguiente:
- count es el número de filas en el marco de datos.
- mean es el valor medio de todas las entradas en la columna «Edad».
- std es la desviación estándar de la columna correspondiente.
- min y max son la entrada mínima y máxima en la columna respectivamente.
- El 25 %, el 50 % y el 75 % son el primer cuartil , el segundo cuartil (mediana) y el tercer cuartil respectivamente, lo que nos brinda información importante sobre la distribución del conjunto de datos y simplifica la aplicación de un modelo de aprendizaje automático.
Publicación traducida automáticamente
Artículo escrito por AbhijitTripathy y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA