Veamos cómo agregar datos a un Pandas DataFrame vacío.
Crear el marco de datos y asignarle las columnas
# importing the module import pandas as pd # creating the DataFrame of int and float a = [[1, 1.2], [2, 1.4], [3, 1.5], [4, 1.8]] t = pd.DataFrame(a, columns =["A", "B"]) # displaying the DataFrame print(t) print(t.dtypes)
Producción :

Al agregar los valores flotantes a la columna de tipo de datos con valor int, la columna del marco de datos resultante se convierte en flotante para acomodar el valor flotante
Si usamos el argumento ignore_index = True => que los valores del índice permanecerán continuos en lugar de comenzar de nuevo desde 0, por defecto su valor esFalse
# Appending a Data Frame of float and int s = pd.DataFrame([[1.3, 9]], columns = ["A", "B"]) display(s) # makes index continuous t = t.append(s, ignore_index = True) display(t) # Resultant data frame is of type float and float display(t.dtypes)
Producción :

Cuando agregamos los datos de formato booleano en el marco de datos que ya era del tipo de columnas flotantes, cambiará los valores en consecuencia para acomodar los valores booleanos en el dominio de tipo de datos flotantes únicamente.
# Appending a Data Frame of bool and bool u = pd.DataFrame([[True, False]], columns =["A", "B"]) display(u) display(u.dtypes) t = t.append(u) display(t) display(t.dtypes) # type casted into float and float
Producción :
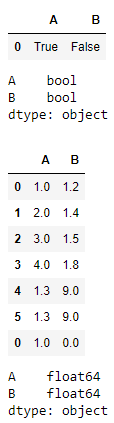
Al agregar los datos de diferentes tipos de datos al marco de datos formado previamente, el tipo de columnas del marco de datos resultante siempre será del tipo de datos de espectro más amplio.
# Appending a Data Frame of object and object x = pd.DataFrame([["1.3", "9.2"]], columns = ["A", "B"]) display(x) display(x.dtypes) t = t.append(x) display(t) display(t.dtypes)
Producción :

Si nuestro objetivo es crear un marco de datos a través de un bucle for, entonces la forma más eficiente de hacerlo es la siguiente:
# Creating a DataFrame using a for loop in efficient manner y = pd.concat([pd.DataFrame([[i, i * 10]], columns = ["A", "B"]) for i in range(7, 10)], ignore_index = True) # makes index continuous t = t.append(y, ignore_index = True) display(t) display(t.dtypes)
Producción

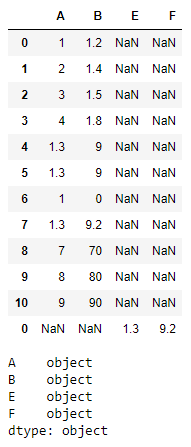
Si intentamos agregar una columna diferente a la que ya está en el marco de datos, los resultados son los siguientes:
# Appending Different Columns z = pd.DataFrame([["1.3", "9.2"]], columns = ["E", "F"]) t = t.append(z) print(t) print(t.dtypes) print()
Producción :
Publicación traducida automáticamente
Artículo escrito por parshavnahta97 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA