En este artículo, veremos cómo agregar dos columnas al marco de datos Pyspark existente usando WithColumns.
WithColumns se usa para cambiar el valor, convertir el tipo de datos de una columna existente, crear una nueva columna y mucho más.
Sintaxis: df.withColumn(colName, col)
Devuelve: una nueva :class:`DataFrame` agregando una columna o reemplazando la columna existente que tiene el mismo nombre.
Ejemplo 1: crear un marco de datos y luego agregar dos columnas.
Aquí vamos a crear un marco de datos a partir de una lista del conjunto de datos dado.
Python3
# Create a spark session
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('SparkExamples').getOrCreate()
# Create a spark dataframe
columns = ["Name", "Course_Name",
"Months",
"Course_Fees", "Discount",
"Start_Date", "Payment_Done"]
data = [
("Amit Pathak", "Python", 3, 10000, 1000,
"02-07-2021", True),
("Shikhar Mishra", "Soft skills", 2,
8000, 800, "07-10-2021", False),
("Shivani Suvarna", "Accounting", 6,
15000, 1500, "20-08-2021", True),
("Pooja Jain", "Data Science", 12,
60000, 900, "02-12-2021", False),
]
df = spark.createDataFrame(data).toDF(*columns)
# View the dataframe
df.show()
Producción:

Ahora agregue las columnas:
Aquí, creamos dos columnas basadas en las columnas existentes.
Python3
new_df = df.withColumn('After_discount',
df.Course_Fees - df.Discount).withColumn('Before_discount',
df.Course_Fees)
new_df.show()
Producción:

Ejemplo 2: crear un marco de datos desde csv y luego agregar las columnas.
Aquí usaremos el archivo cricket_data_set_odi.csv como un conjunto de datos y crearemos un marco de datos a partir de este archivo.
Creando Dataframe para demostración:
Python3
# import pandas to read json file
import pandas as pd
# importing module
import pyspark
# importing sparksession from pyspark.sql
# module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# create Dataframe
df = spark.read.option("header",True).csv("Cricket_data_set_odi.csv")
# Display Schema
df.printSchema()
# Show Dataframe
df.show()
Producción:
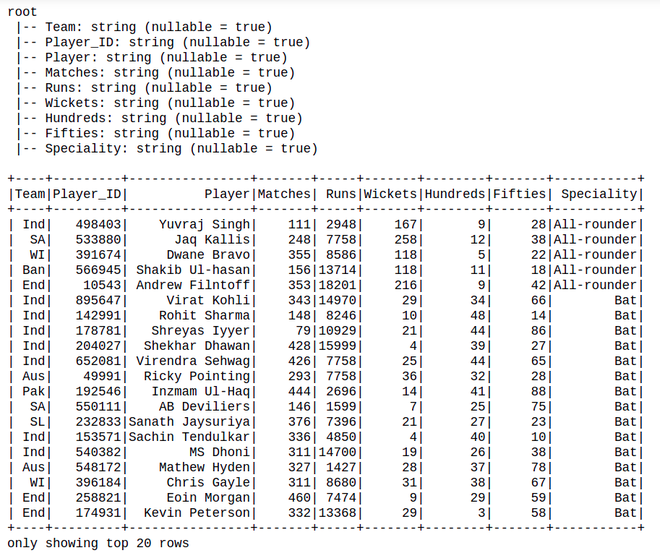
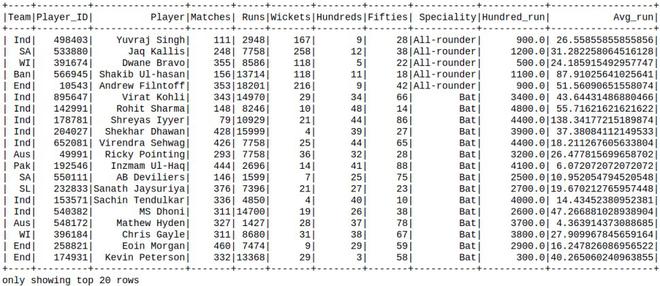
Luego, agregando las columnas en un marco de datos existente:
Python3
new_df = df.withColumn( 'Hundred_run', df.Hundreds*100).withColumn( 'Avg_run', df.Runs / df.Matches) new_df.show()
Producción:
Publicación traducida automáticamente
Artículo escrito por kumar_satyam y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA