En este artículo, aprendamos cómo agregar una nueva variable a pandas DataFrame usando la función de asignación() y corchetes.
Pandas es un paquete de Python que ofrece varias estructuras de datos y operaciones para manipular datos numéricos y series temporales. Es principalmente popular para importar y analizar datos mucho más fácilmente. Mientras que Pandas DataFrame es una estructura de datos tabulares de tamaño mutable bidimensional potencialmente heterogénea con ejes etiquetados (filas y columnas). Un marco de datos es una estructura de datos bidimensional en la que los datos se organizan en filas y columnas en un formato tabular. Los datos, las filas y las columnas son los tres componentes principales de un DataFrame de Pandas. aquí veremos dos métodos diferentes para agregar nuevas variables a nuestro marco de datos de pandas.
Método 1: Usar el método pandas.DataFrame.assign()
Este método se usa para crear nuevas columnas para un DataFrame. Devuelve un nuevo objeto que contiene todas las columnas originales, así como las nuevas. Si hay columnas existentes, se sobrescribirán si se reasignan.
Sintaxis: DataFrame.assign(**kwargs)
- **kwargsdict of {str: callable or Series}: las palabras clave se utilizan para nombrar las columnas. Si se puede llamar a los valores, se calculan y asignan a las nuevas columnas en el DataFrame. El invocable no debe modificar el DataFrame de entrada. Si los valores no se pueden llamar (por ejemplo, si son una serie, un escalar o una array), se asignan fácilmente.
Devoluciones: se devuelve un nuevo DataFrame con las nuevas columnas, así como con todas las columnas existentes.
Ejemplo
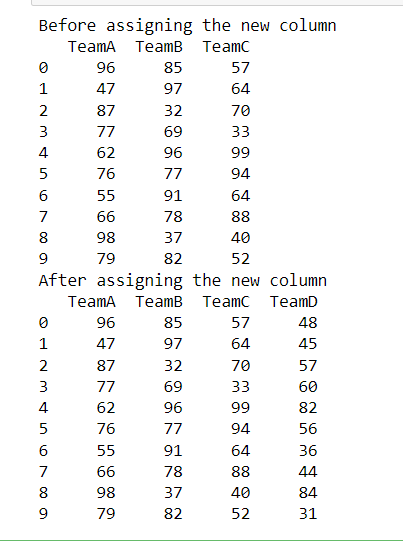
En este ejemplo, importamos los paquetes de NumPy y panda, configuramos la semilla para que se generen los mismos datos aleatorios cada vez. Se genera un conjunto de datos con 10 puntajes de equipo que van de 30 a 100 para tres equipos. El método de asignación() se usa para crear otra columna en el marco de datos, proporcionamos un nombre de palabra clave que será el nombre de la columna a la que le asignaremos datos. Después de asignar datos, se crea un nuevo marco de datos con una nueva columna además de las columnas existentes.
Python3
# import packages
import numpy as np
import pandas as pd
# setting a seed
np.random.seed(123)
# creating a dataframe
df = pd.DataFrame({'TeamA': np.random.randint(30, 100, 10),
'TeamB': np.random.randint(30, 100, 10),
'TeamC': np.random.randint(30, 100, 10)})
print('Before assigning the new column')
print(df)
# using assign() method to add a new column
scores = np.random.randint(30, 100, 10)
df2 = df.assign(TeamD=scores)
print('After assigning the new column')
print(df2)
Producción:
Método 2: usar [] para agregar una nueva columna
En este ejemplo, en lugar de usar el método de asignación(), usamos corchetes ([]) para crear una nueva variable o columna para un marco de datos existente. La sintaxis es así:
dataframe_name['column_name'] = data column_name is the name of the new column to be added in our dataframe.
Ejemplo
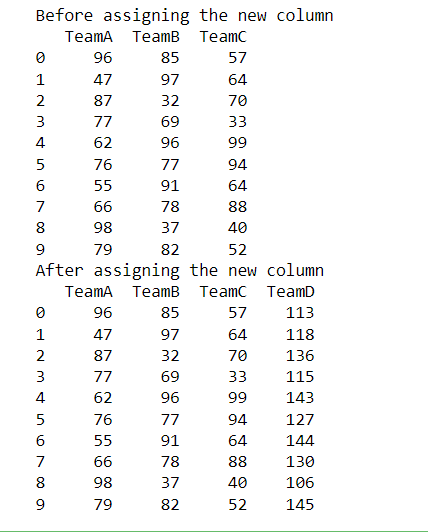
obtenemos el mismo resultado que cuando usamos el método de asignación(). En este ejemplo, se crea una nueva columna llamada TeamD , que muestra las puntuaciones de las personas en TeamD. Los datos aleatorios se crean y asignan al Dataframe a la nueva columna.
Python3
# import packages
import numpy as np
import pandas as pd
# setting a seed
np.random.seed(123)
# creating a dataframe
df = pd.DataFrame({'TeamA': np.random.randint(30, 100, 10),
'TeamB': np.random.randint(30, 100, 10),
'TeamC': np.random.randint(30, 100, 10)})
print('Before assigning the new column')
print(df)
# using [] to add a new column
scores = np.random.randint(100, 150, 10)
df['TeamD'] = scores
print('After assigning the new column')
print(df)
Producción:
Publicación traducida automáticamente
Artículo escrito por isitapol2002 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA