En este artículo, vamos a ver cómo agregar datos diarios durante un período de intervalos de meses y años en el marco de datos en el lenguaje de programación R.
Método 1: Usar el método de agregado()
Base R contiene una gran cantidad de métodos para realizar operaciones en el marco de datos. El método seq() en R se usa para generar secuencias regulares a partir de un valor predefinido.
Sintaxis: seq(from, to, by, length.out)
Argumentos:
- from – El valor desde donde comienza la secuencia. El método as.Date() se usa aquí para generar una secuencia de fechas hasta que se alcanza la longitud de la secuencia.
- to – El valor donde terminar la secuencia.
- by – El parámetro para incrementar la secuencia. Aquí se utiliza “día” como parámetro, para generar fechas sucesivas en orden.
- length.out: la longitud total de la secuencia.
Luego, el marco de datos se forma usando una muestra de esta secuencia de fechas generada como columna 1. El valor se genera usando el método rnorm() para producir números aleatorios de punto flotante.
A continuación, se utiliza el método strftime() para convertir un objeto de tiempo en una string de caracteres. El formato se puede especificar para extraer diferentes componentes del objeto de fecha.
Sintaxis: strftime (fecha, formato)
Argumentos:
- fecha: el objeto que se va a convertir
- format – Usamos %m para extraer el mes y %Y para extraer el año en formato AAAA.
Para agregar los datos, se utiliza el método agregado, que se utiliza para calcular las estadísticas de resumen de cada uno de los grupos.
Sintaxis: agregado (fórmula, datos, FUN)
Argumentos:
- fórmula: una fórmula, como y ~ x
- datos: el marco de datos sobre el que aplicar la función
- FUN: la función que se aplicará al marco de datos. Aquí, la función aplicada es sum para realizar la agregación o sumatoria sobre los valores pertenecientes a un mismo grupo.
Código:
R
set.seed(99923)
# creating dataframe
# specifying number of rows
len <- 100
# creating sequences of dates
var_seq <- seq(as.Date("2021/05/01"),
by = "day",
length.out = len)
# creating columns for dataframe
data_frame <- data.frame(col1 = sample( var_seq,
100, replace = TRUE),
col2 = round(rnorm(10, 5, 2), 2))
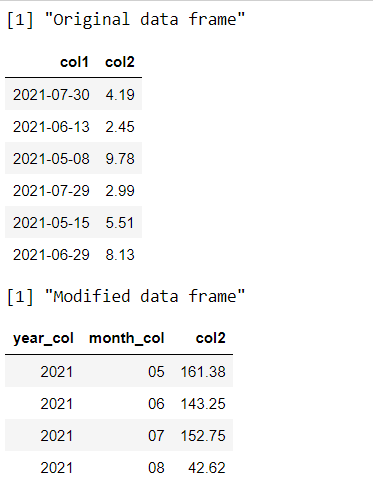
print("Original dataframe")
head(data_frame)
# creating new year column for dataframe
data_frame$year_col <- strftime(data_frame$col1, "%Y")
# creating new month column for dataframe
data_frame$month_col <- strftime(data_frame$col1, "%m")
# aggregating the daily data
data_frame_mod <- aggregate(col2 ~ year_col + month_col,
data_frame,
FUN = sum)
print("Modified dataframe")
head(data_frame_mod)
Producción:
Método 2: Usar el paquete lubridate y dplyr
El paquete Lubridate en R se usa para proporcionar mecanismos de trabajo más fáciles con los objetos de fecha y hora. Se puede cargar e instalar en el espacio de trabajo usando el siguiente comando:
install.packages("lubridate")
El método floor_date() en R usa un objeto de fecha y hora, puede ser una sola entidad o vector de objetos de fecha y hora, y luego lo redondea al valor entero más cercano en la unidad de tiempo especificada.
floor_date(x , unit = months)
El paquete dplyr se utiliza para realizar manipulaciones de datos y estadísticas. Se puede cargar e instalar en el espacio de trabajo usando el siguiente comando:
install.packages("dplyr")
El marco de datos se modifica utilizando el operador de tubería sobre una secuencia de operaciones y métodos. El método group_by() se utiliza para agrupar los datos según los valores contenidos en las columnas especificadas.
group_by(col1,..)
Luego, se realiza una estadística de resumen utilizando el método resume() que realiza una suma sobre los valores contenidos en la tercera columna. Luego, el resultado se manipula en un marco de datos utilizando el método as.data.frame().
Código:
R
library("dplyr")
library("lubridate")
set.seed(99923)
# creating dataframe
# specifying number of rows
len <- 100
# creating sequences of dates
var_seq <- seq(as.Date("2021/05/01"),
by = "day",
length.out = len)
# creating columns for dataframe
data_frame <- data.frame(col1 = sample( var_seq,
100, replace = TRUE),
col2 = round(rnorm(10, 5, 2), 2))
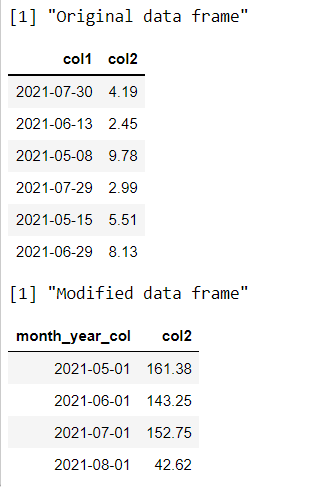
print("Original dataframe")
head(data_frame)
# creating new month column for dataframe
data_frame$month_year_col <- floor_date(data_frame$col1,
"month")
# aggregating the daily data
data_frame_mod <- data_frame %>%
group_by(month_year_col) %>%
dplyr::summarize(col2 = sum(col2)) %>%
as.data.frame()
print("Modified dataframe")
head(data_frame_mod)
Producción:
Publicación traducida automáticamente
Artículo escrito por yashchuahan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA