Pandas es la biblioteca de Python más popular que se utiliza para el análisis de datos. Proporciona un rendimiento altamente optimizado con código fuente back-end escrito exclusivamente en C o Python.
Veamos cómo agrupar filas en Pandas Dataframe con la ayuda de varios ejemplos.
Ejemplo 1:
Para agrupar filas en Pandas, comenzaremos con la creación de un marco de datos de pandas primero.
# importing Pandas
import pandas as pd
# example dataframe
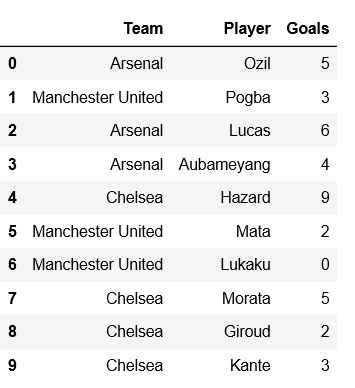
example = {'Team':['Arsenal', 'Manchester United', 'Arsenal',
'Arsenal', 'Chelsea', 'Manchester United',
'Manchester United', 'Chelsea', 'Chelsea', 'Chelsea'],
'Player':['Ozil', 'Pogba', 'Lucas', 'Aubameyang',
'Hazard', 'Mata', 'Lukaku', 'Morata',
'Giroud', 'Kante'],
'Goals':[5, 3, 6, 4, 9, 2, 0, 5, 2, 3] }
df = pd.DataFrame(example)
print(df)
Ahora, crear un objeto de agrupación, significa un objeto que representa esa agrupación en particular.
total_goals = df['Goals'].groupby(df['Team']) # printing the means value print(total_goals.mean())
Producción: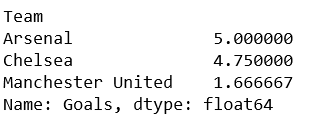
Ejemplo 2:
import pandas as pd
# example dataframe
example = {'Team':['Australia', 'England', 'South Africa',
'Australia', 'England', 'India', 'India',
'South Africa', 'England', 'India'],
'Player':['Ricky Ponting', 'Joe Root', 'Hashim Amla',
'David Warner', 'Jos Buttler', 'Virat Kohli',
'Rohit Sharma', 'David Miller', 'Eoin Morgan',
'Dinesh Karthik'],
'Runs':[345, 336, 689, 490, 989, 672, 560, 455, 342, 376],
'Salary':[34500, 33600, 68900, 49000, 98899,
67562, 56760, 45675, 34542, 31176] }
df = pd.DataFrame(example)
total_salary = df['Salary'].groupby(df['Team'])
# printing the means value
print(total_salary.mean())
Producción:
Publicación traducida automáticamente
Artículo escrito por schrodinger_19 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA