En este artículo, agruparemos y filtraremos los datos en PySpark usando Python.
Vamos a crear el marco de datos para la demostración:
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.show()
Producción:
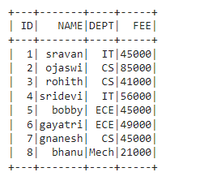
En PySpark, groupBy() se usa para recopilar datos idénticos en grupos en PySpark DataFrame y realizar funciones agregadas en los datos agrupados. Tenemos que usar cualquiera de las funciones con groupby mientras usamos el método
Sintaxis : dataframe.groupBy(‘column_name_group’).aggregate_operation(‘column_name’)
Filtrar los datos significa eliminar algunos datos según la condición. En PySpark podemos filtrar usando la función filter() y where()
Método 1: Usar filtro()
Esto se usa para filtrar el marco de datos según la condición y devuelve el marco de datos resultante
Sintaxis : filter(col(‘column_name’) condition )
filtrar con groupby():
dataframe.groupBy(‘column_name_group’).agg(aggregate_function(‘column_name’).alias(“new_column_name”).filter(col(‘new_column_name’) condition )
dónde,
- dataframe es el dataframe de entrada
- column_name_group es la columna que se agrupará
- column_name es la columna que se agrega con operaciones agregadas
- La función agregada se encuentra entre las funciones: sum(),min(),max(),count(),avg()
- new_column_name es la columna que se dará de la columna anterior
- col es la función para especificar la columna en el filtro
- la condición es obtener los datos del marco de datos usando operadores relacionales
Ejemplo 1: filtre datos obteniendo FEE mayor o igual a 56700 usando sum()
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum()
# to get FEE greater than 56700
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).filter(
col('Total Fee') >= 56700).show()
Producción:
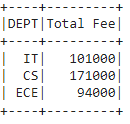
Ejemplo 2: Filtro con múltiples condiciones
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum()
# to get FEE greater than or equal to
# 56700 and less than or equal to 100000
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).filter(
col('Total Fee') >= 56700).filter(
col('Total Fee') <= 100000).show()
Producción:
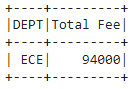
Método 2: Usando where()
Esto se usa para seleccionar el marco de datos en función de la condición y devuelve el marco de datos resultante
Sintaxis : where(col(‘nombre_columna’) condición )
donde con groupby():
dataframe.groupBy(‘column_name_group’).agg(aggregate_function(‘column_name’).alias(“new_column_name”).where(col(‘new_column_name’) condition )
dónde,
- dataframe es el dataframe de entrada
- column_name_group es la columna que se agrupará
- column_name es la columna que se agrega con operaciones agregadas
- La función agregada se encuentra entre las funciones: sum(),min(),max(),count(),avg()
- new_column_name es la columna que se dará de la columna anterior
- col es la función para especificar la columna en la que
- la condición es obtener los datos del marco de datos usando operadores relacionales
Ejemplo 1: filtre datos obteniendo FEE mayor o igual a 56700 usando sum()
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum() to get
# FEE greater than or equal to 56700
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).where(
col('Total Fee') >= 56700).show()
Producción:
Ejemplo 2: Filtro con múltiples condiciones
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import col
from pyspark.sql.functions import col, sum
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# Groupby with DEPT with sum() to get
# FEE greater than or equal to 56700
# and less than or equal to 100000
dataframe.groupBy('DEPT').agg(sum(
'FEE').alias("Total Fee")).where(
col('Total Fee') >= 56700).where(
col('Total Fee') <= 100000).show()
Producción:
Método 3: Uso de la función de ventana
La función de ventana se utiliza para particionar las columnas en el marco de datos
Sintaxis : Window.partitionBy(‘column_name_group’)
donde, column_name_group es la columna que contiene múltiples valores para la partición
Podemos particionar la columna de datos que contiene valores de grupo y luego usar las funciones agregadas como min(), max, etc. para obtener los datos. De esta forma, vamos a filtrar los datos del PySpark DataFrame con la cláusula where.
Sintaxis : dataframe.withColumn(‘nueva columna’, functions.max(‘column_name’).over(Window.partitionBy(‘column_name_group’))).where(functions.col(‘column_name’) == functions.col(‘ nombre_nueva_columna’))
dónde,
- dataframe es el dataframe de entrada
- column_name_group es la columna que se dividirá
- column_name es para obtener los valores con la columna agrupada
- new_column_name es la nueva columna filtrada
Ejemplo: programa PySpark para filtrar solo el máximo de filas del marco de datos de todos los departamentos
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions as f
# import window module
from pyspark.sql import Window
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.withColumn('FEE max', f.max('FEE').over(
Window.partitionBy('DEPT'))).where(
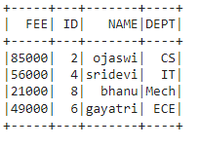
f.col('FEE') == f.col('FEE max')).show()
Producción:
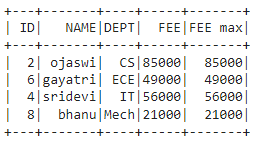
Método 4: Uso de unión
Podemos filtrar los datos con operaciones agregadas utilizando la combinación semi izquierda. Esta combinación devolverá los datos coincidentes izquierdos de dataframe1 con la operación agregada.
Sintaxis: dataframe.join(dataframe.groupBy(‘column_name_group’).agg(f.max(‘column_name’).alias(‘new_column_name’)),on=’FEE’,how=’leftsemi’)
Ejemplo: Filtrar datos con una tarifa máxima de todos los departamentos
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
#import functions
from pyspark.sql import functions as f
# import window module
from pyspark.sql import Window
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [["1", "sravan", "IT", 45000],
["2", "ojaswi", "CS", 85000],
["3", "rohith", "CS", 41000],
["4", "sridevi", "IT", 56000],
["5", "bobby", "ECE", 45000],
["6", "gayatri", "ECE", 49000],
["7", "gnanesh", "CS", 45000],
["8", "bhanu", "Mech", 21000]
]
# specify column names
columns = ['ID', 'NAME', 'DEPT', 'FEE']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.join(dataframe.groupBy('DEPT').agg(
f.max('FEE').alias('FEE')), on='FEE',
how='leftsemi').show()
Producción:
Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA