En este artículo, discutiremos cómo ajustar una curva a un marco de datos en el lenguaje de programación R.
El ajuste de curvas es una de las funciones básicas del análisis estadístico. Nos ayuda a determinar las tendencias y los datos y nos ayuda a predecir datos desconocidos en función de un modelo/función de regresión.
Visualización de marco de datos:
Para ajustar una curva a algún marco de datos en el lenguaje R, primero visualizamos los datos con la ayuda de un gráfico de dispersión básico. En el lenguaje R, podemos crear un diagrama de dispersión básico usando la función plot().
Sintaxis:
plot( df$x, df$y)
dónde,
- df: determina el marco de datos a utilizar.
- x e y: determina las variables del eje.
Ejemplo:
R
# create sample data sample_data <- data.frame(x=1:10, y=c(25, 22, 13, 10, 5, 9, 12, 16, 34, 44)) #create a basic scatterplot plot(sample_data$x, sample_data$y)
Producción:
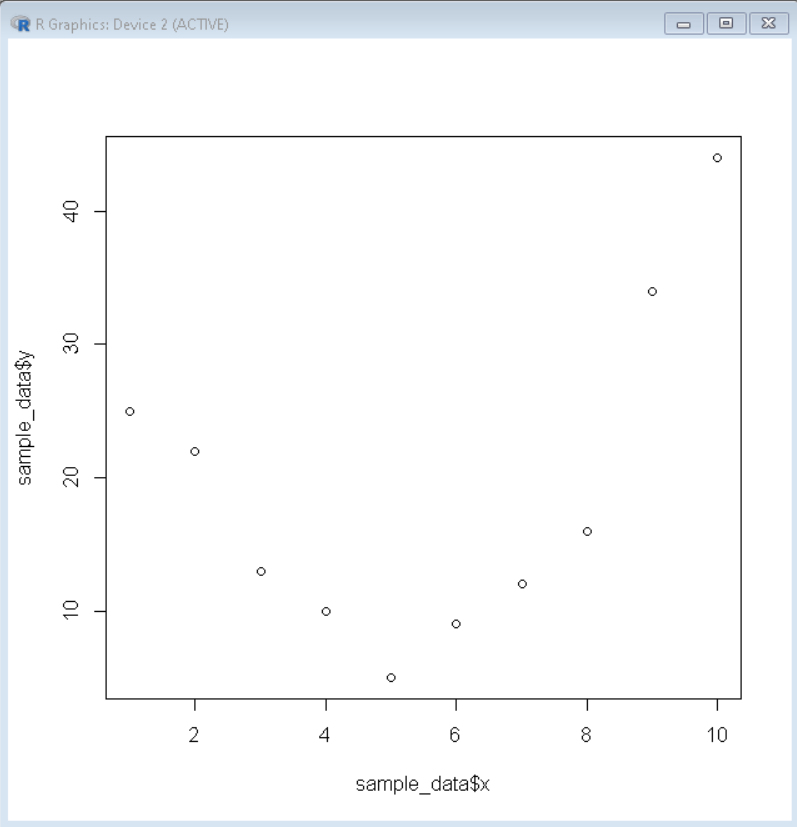
Cree varias curvas para ajustarse a los datos
Luego, creamos modelos de regresión lineal en el grado requerido y los representamos en la parte superior del gráfico de dispersión para ver cuál se ajusta mejor a los datos. Usamos la función lm() para crear un modelo lineal. Y luego use la función lines() para trazar un diagrama de líneas sobre el diagrama de dispersión usando estos modelos lineales.
Sintaxis:
lm( function, data)
dónde,
- función: determina la función polinómica de ajuste.
- datos: determina el marco de datos sobre el que se va a ajustar la función.
Ejemplo:
R
# create sample data sample_data <- data.frame(x=1:10, y=c(25, 22, 13, 10, 5, 9, 12, 16, 34, 44)) # fit polynomial regression models up to degree 5 linear_model1 <- lm(y~x, data=sample_data) linear_model2 <- lm(y~poly(x,2,raw=TRUE), data=sample_data) linear_model3 <- lm(y~poly(x,3,raw=TRUE), data=sample_data) linear_model4 <- lm(y~poly(x,4,raw=TRUE), data=sample_data) linear_model5 <- lm(y~poly(x,5,raw=TRUE), data=sample_data) # create a basic scatterplot plot(sample_data$x, sample_data$y) # define x-axis values x_axis <- seq(1, 10, length=10) # add curve of each model to plot lines(x_axis, predict(linear_model1, data.frame(x=x_axis)), col='green') lines(x_axis, predict(linear_model2, data.frame(x=x_axis)), col='red') lines(x_axis, predict(linear_model3, data.frame(x=x_axis)), col='purple') lines(x_axis, predict(linear_model4, data.frame(x=x_axis)), col='blue') lines(x_axis, predict(linear_model5, data.frame(x=x_axis)), col='orange')
Producción:
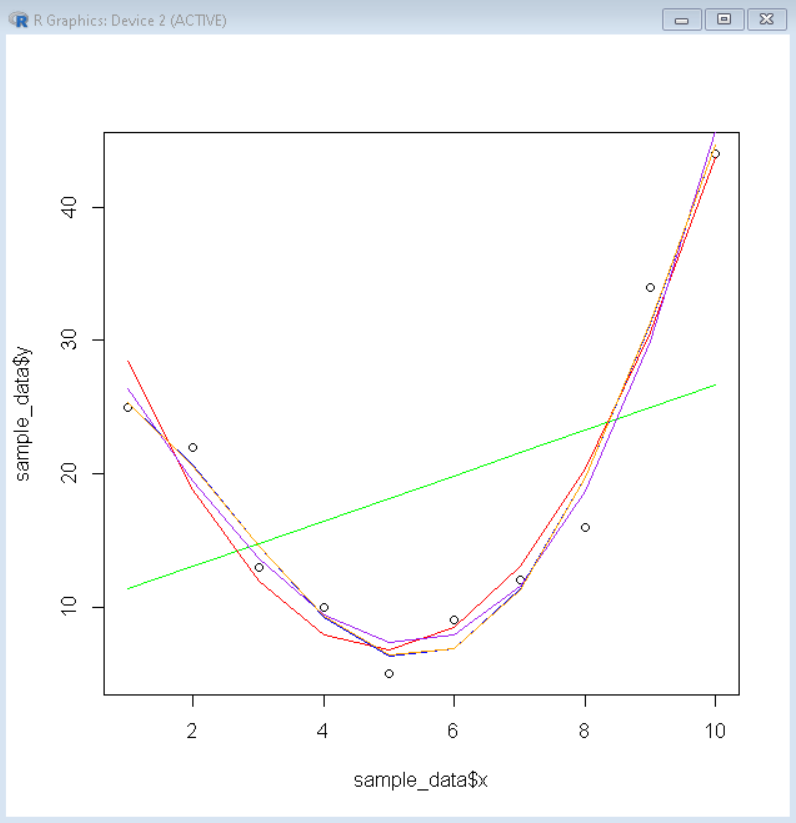
Curva de mejor ajuste con valor r cuadrado ajustado
Ahora, dado que no podemos determinar el modelo de mejor ajuste solo por su representación visual, tenemos una variable de resumen r.squared que nos ayuda a determinar el modelo de mejor ajuste. La r cuadrada ajustada es el porcentaje de la varianza de Y intacta después de restar el error del modelo. Cuanto mayor sea el valor de R Squared, mejor será el modelo para ese marco de datos. Para obtener el valor de r cuadrado ajustado del modelo lineal, usamos la función summary() que contiene el valor de r cuadrado ajustado como variable adj.r.squared.
Sintaxis:
summary( linear_model )$adj.r.squared
dónde,
- linear_model: determina el modelo lineal cuyo resumen se va a extraer.
Ejemplo:
R
# create sample data sample_data <- data.frame(x=1:10, y=c(25, 22, 13, 10, 5, 9, 12, 16, 34, 44)) # fit polynomial regression models up to degree 5 linear_model1 <- lm(y~x, data=sample_data) linear_model2 <- lm(y~poly(x,2,raw=TRUE), data=sample_data) linear_model3 <- lm(y~poly(x,3,raw=TRUE), data=sample_data) linear_model4 <- lm(y~poly(x,4,raw=TRUE), data=sample_data) linear_model5 <- lm(y~poly(x,5,raw=TRUE), data=sample_data) # calculated adjusted R-squared of each model summary(linear_model1)$adj.r.squared summary(linear_model2)$adj.r.squared summary(linear_model3)$adj.r.squared summary(linear_model4)$adj.r.squared summary(linear_model5)$adj.r.squared
Producción:
[1] 0.07066085 [2] 0.9406243 [3] 0.9527703 [4] 0.955868 [5] 0.9448878
Visualice la curva de mejor ajuste con el marco de datos:
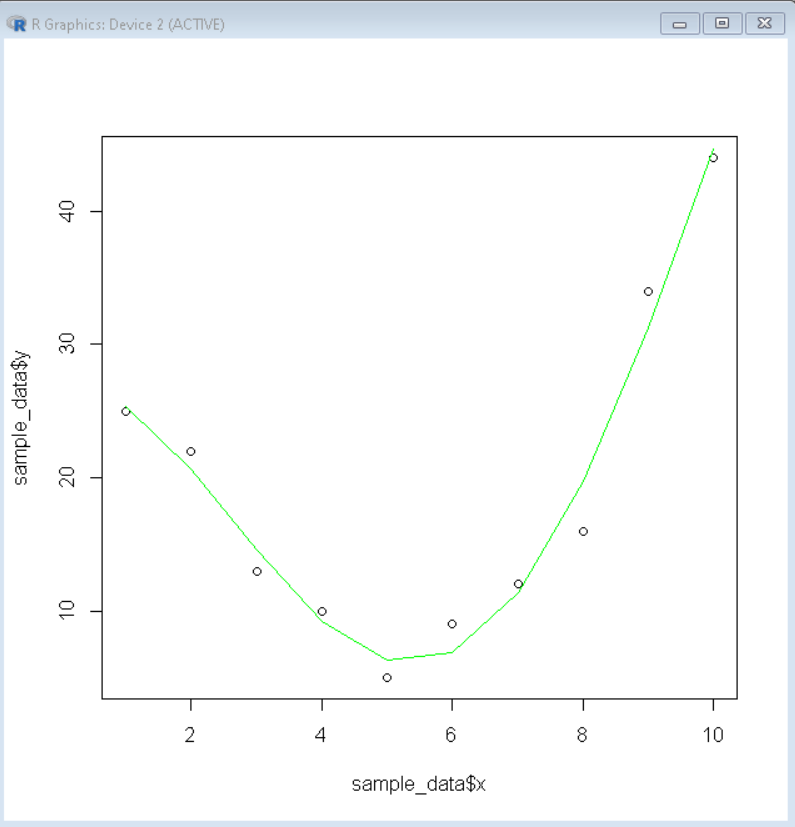
Ahora, a partir del resumen anterior, sabemos que el modelo lineal de cuarto grado se ajusta mejor a la curva con un valor de r cuadrado ajustado de 0,955868. Entonces, visualizaremos el modelo lineal de cuarto grado con el diagrama de dispersión y esa es la mejor curva de ajuste para el marco de datos.
Ejemplo:
R
# create sample data sample_data <- data.frame(x=1:10, y=c(25, 22, 13, 10, 5, 9, 12, 16, 34, 44)) # Create best linear model best_model <- lm(y~poly(x,4,raw=TRUE), data=sample_data) # create a basic scatterplot plot(sample_data$x, sample_data$y) # define x-axis values x_axis <- seq(1, 10, length=10) # plot best model lines(x_axis, predict(best_model, data.frame(x=x_axis)), col='green')
Producción:
Publicación traducida automáticamente
Artículo escrito por mishrapriyank17 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA