Ya hemos discutido la variación heurística de carácter malo del algoritmo de Boyer Moore. En este artículo discutiremos la heurística Good Suffix para la búsqueda de patrones. Al igual que la heurística de carácter incorrecto, se genera una tabla de preprocesamiento para la heurística de sufijo correcto.
Buen sufijo heurístico
Sea t una substring de texto T que coincide con la substring del patrón P . Ahora cambiamos el patrón hasta que:
1) Otra aparición de t en P coincida con t en T.
2) Un prefijo de P, que coincide con el sufijo de t
3) P se mueve más allá de t
Caso 1: otra ocurrencia de t en P emparejada con t en T
El patrón P podría contener algunas ocurrencias más de t . En tal caso, intentaremos cambiar el patrón para alinear esa ocurrencia con t en el texto T. Por ejemplo-
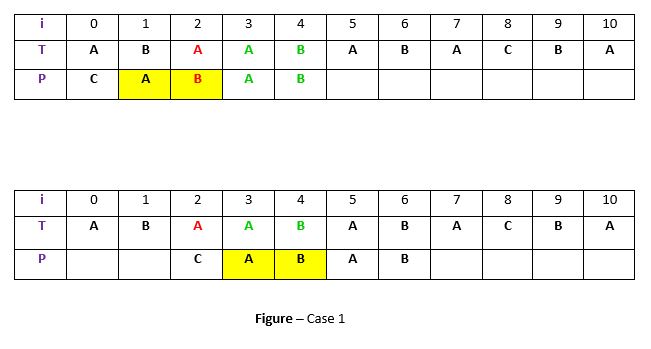
Explicación: En el ejemplo anterior, tenemos una substring t del texto T que coincide con el patrón P (en verde) antes de la discrepancia en el índice 2. Ahora buscaremos la ocurrencia de t («AB») en P. Hemos encontrado un ocurrencia que comienza en la posición 1 (en fondo amarillo), por lo que cambiaremos el patrón a la derecha 2 veces para alinear t en P con t en T. Esta es una regla débil del Boyer Moore original y no muy efectiva, discutiremos una regla de sufijo bueno fuerte dentro de poco.
Caso 2: Un prefijo de P, que coincide con el sufijo de t en T
No siempre es probable que encontremos la ocurrencia de t en P. A veces no ocurre nada, en tales casos, a veces podemos buscar algún sufijo de t coincidiendo con algún prefijo de P e intente alinearlos cambiando P. Por ejemplo:
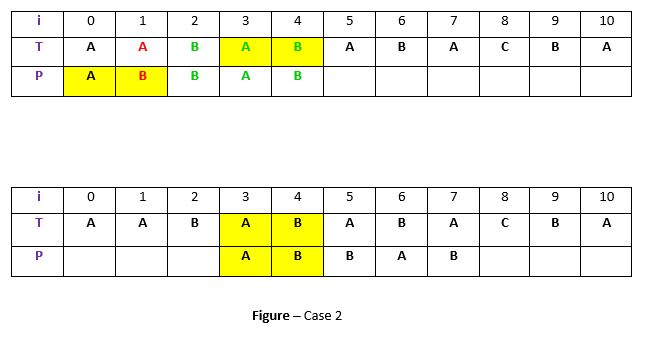
Explicación: En el ejemplo anterior, tenemos t («BAB») emparejada con P (en verde) en el índice 2-4 antes de la falta de coincidencia. Pero debido a que no existe ninguna aparición de t en P, buscaremos algún prefijo de P que coincida con algún sufijo de t. Hemos encontrado el prefijo «AB» (en el fondo amarillo) que comienza en el índice 0 que no coincide con la t completa sino con el sufijo de t «AB» que comienza en el índice 3. Así que ahora cambiaremos el patrón 3 veces para alinear el prefijo con el sufijo .
Caso 3: P se mueve más allá de t
Si los dos casos anteriores no se cumplen, cambiaremos el patrón más allá de t. Por ejemplo –
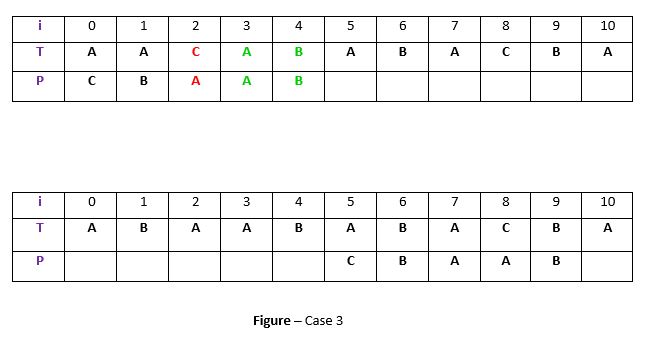
Explicación: Si el ejemplo anterior, no existe ninguna ocurrencia de t («AB») en P y tampoco hay un prefijo en P que coincida con el sufijo de t. Entonces, en ese caso, nunca podremos encontrar una coincidencia perfecta antes del índice 4, por lo que desplazaremos la P más allá del empate. al índice 5.
Sufijo fuerte bueno heurístico
Supongamos que la substring q = P[i a n] coincidió con t en T y c = P[i-1] es el carácter que no coincide. Ahora, a diferencia del caso 1, buscaremos t en P, que no está precedido por el carácter c . La ocurrencia más cercana se alinea con t en T cambiando el patrón P. Por ejemplo:
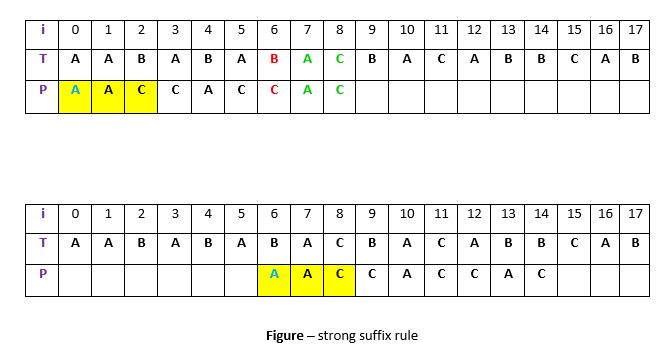
Explicación: En el ejemplo anterior, q = P[7 a 8] coincidió con t en T. El carácter c que no coincide es “C” en la posición P[6]. Ahora, si comenzamos a buscar t en P, obtendremos la primera ocurrencia de t comenzando en la posición 4. Pero esta ocurrencia está precedida por «C», que es igual a c, por lo que omitiremos esto y continuaremos buscando. En la posición 1 tenemos otra ocurrencia de t (en el fondo amarillo). Esta ocurrencia está precedida por «A» (en azul) que no es equivalente a c. Entonces cambiaremos el patrón P 6 veces para alinear esta ocurrencia con t en T. Estamos haciendo esto porque ya sabemos que el carácter c = «C» causa la falta de coincidencia. Entonces, cualquier ocurrencia de t precedida por c nuevamente causará una falta de coincidencia cuando se alinee con t, por eso es mejor omitir esto.
Preprocesamiento para Good sufijo heurístico
Como parte del preprocesamiento, se crea un cambio de array. Cada cambio de entrada[i] contiene el patrón de distancia que cambiará si se produce una discrepancia en la posición i-1 . Es decir, el sufijo del patrón que comienza en la posición i coincide y se produce una falta de coincidencia en la posición i-1 . El preprocesamiento se realiza por separado para el sufijo bueno fuerte y el caso 2 discutido anteriormente.
1) Preprocesamiento para el sufijo Strong Good
Antes de discutir el preprocesamiento, analicemos primero la idea de borde. Un borde es una substring que es a la vez un sufijo y un prefijo adecuados. Por ejemplo, en la string «ccacc» , «c» es un borde, «cc» es un borde porque aparece en ambos extremos de la string, pero «cca» no es un borde.
Como parte del preprocesamiento, se calcula una array bpos (posición del borde). Cada entrada bpos[i] contiene el índice inicial del borde para el sufijo que comienza en el índice i en el patrón dado P.
El sufijo φ que comienza en la posición m no tiene borde, por lo que bpos[m] se establece en m+1 donde m es la longitud del patrón
La posición de cambio se obtiene por los bordes que no se pueden extender hacia la izquierda. El siguiente es el código para el preprocesamiento:
void preprocess_strong_suffix(int *shift, int *bpos,
char *pat, int m)
{
int i = m, j = m+1;
bpos[i] = j;
while(i > 0)
{
while(j <= m && pat[i-1] != pat[j-1])
{
if (shift[j] == 0)
shift[j] = j-i;
j = bpos[j];
}
i--; j--;
bpos[i] = j;
}
}
Explicación: Considere el patrón P = “ABBABAB”, m = 7 .
- El borde más ancho del sufijo «AB» que comienza en la posición i = 5 es φ (nada) que comienza en la posición 7, por lo que bpos[5] = 7.
- En la posición i = 2 el sufijo es “BABAB”. El borde más ancho de este sufijo es «BAB» a partir de la posición 4, por lo que j = bpos[2] = 4.
Podemos entender bpos[i] = j usando el siguiente ejemplo:

Si el carácter # ¿Cuál está en la posición i-1 es equivalente al carácter ? en la posición j-1 , sabemos que borde será ? + borde del sufijo en la posición i que comienza en la posición j , lo que equivale a decir que el borde del sufijo en i-1 comienza en j-1 o bpos[ i-1 ] = j-1 o en el código –
i--; j--; bpos[ i ] = j
¿Pero si el carácter # en la posición i-1 no coincide con el carácter ? en la posición j-1 luego continuamos nuestra búsqueda hacia la derecha. Ahora sabemos que –
- El ancho del borde será más pequeño que el borde que comienza en la posición j , es decir. menor que x…φ
- El borde debe comenzar con # y terminar con φ o puede estar vacío (no existe ningún borde).
Con los dos hechos anteriores, continuaremos nuestra búsqueda en la substring x…φ desde la posición j hasta la m . El siguiente borde debe estar en j = bpos[j] . Después de actualizar j , comparamos nuevamente el carácter en la posición j-1 (?) con # y si son iguales, obtuvimos nuestro borde; de lo contrario, continuamos nuestra búsqueda hacia la derecha hasta j>m . Este proceso se muestra por código –
while(j <= m && pat[i-1] != pat[j-1])
{
j = bpos[j];
}
i--; j--;
bpos[i]=j;
En el código anterior, observe estas condiciones:
pat[i-1] != pat[j-1]
Esta es la condición que discutimos en el caso 2. Cuando el carácter que precede a la aparición de t en el patrón P es diferente del carácter no coincidente en P, dejamos de omitir las apariciones y cambiamos el patrón. Así que aquí P[i] == P[j] pero P[i-1] != p[j-1] así que cambiamos el patrón de i a j . Entonces shift[j] = ji es el registrador de j . Por lo tanto, cada vez que ocurra un desajuste en la posición j , cambiaremos las posiciones de cambio de patrón [j+1] a la derecha.
En el código anterior, la siguiente condición es muy importante:
if (shift[j] == 0 )
Esta condición impide la modificación del valor shift[j] del sufijo que tiene el mismo borde. Por ejemplo, considere el patrón P = “addbddcdd” , cuando calculamos bpos[i-1] para i = 4, entonces j = 7 en este caso. finalmente estableceremos el valor de shift[7] = 3. Ahora, si calculamos bpos[i-1] para i = 1, entonces j = 7 y estableceremos el valor shift[7] = 6 nuevamente si no hay prueba shift[ j ] == 0. Esto significa que si tenemos una discrepancia en la posición 6, cambiaremos el patrón P 3 posiciones a la derecha, no 6 posiciones.
2) Preprocesamiento para el Caso 2
En el preprocesamiento para el caso 2, para cada sufijo se determina el borde más ancho de todo el patrón que está contenido en ese sufijo.
La posición inicial del borde más ancho del patrón se almacena en bpos[0].
En el siguiente algoritmo de preprocesamiento, este valor bpos[0] se almacena inicialmente en todas las entradas libres de cambio de array. Pero cuando el sufijo del patrón se vuelve más corto que bpos[0], el algoritmo continúa con el siguiente borde más ancho del patrón, es decir, con bpos[j].
A continuación se muestra la implementación del algoritmo de búsqueda:
C++
/* C program for Boyer Moore Algorithm with
Good Suffix heuristic to find pattern in
given text string */
#include <stdio.h>
#include <string.h>
// preprocessing for strong good suffix rule
void preprocess_strong_suffix(int *shift, int *bpos,
char *pat, int m)
{
// m is the length of pattern
int i=m, j=m+1;
bpos[i]=j;
while(i>0)
{
/*if character at position i-1 is not equivalent to
character at j-1, then continue searching to right
of the pattern for border */
while(j<=m && pat[i-1] != pat[j-1])
{
/* the character preceding the occurrence of t in
pattern P is different than the mismatching character in P,
we stop skipping the occurrences and shift the pattern
from i to j */
if (shift[j]==0)
shift[j] = j-i;
//Update the position of next border
j = bpos[j];
}
/* p[i-1] matched with p[j-1], border is found.
store the beginning position of border */
i--;j--;
bpos[i] = j;
}
}
//Preprocessing for case 2
void preprocess_case2(int *shift, int *bpos,
char *pat, int m)
{
int i, j;
j = bpos[0];
for(i=0; i<=m; i++)
{
/* set the border position of the first character of the pattern
to all indices in array shift having shift[i] = 0 */
if(shift[i]==0)
shift[i] = j;
/* suffix becomes shorter than bpos[0], use the position of
next widest border as value of j */
if (i==j)
j = bpos[j];
}
}
/*Search for a pattern in given text using
Boyer Moore algorithm with Good suffix rule */
void search(char *text, char *pat)
{
// s is shift of the pattern with respect to text
int s=0, j;
int m = strlen(pat);
int n = strlen(text);
int bpos[m+1], shift[m+1];
//initialize all occurrence of shift to 0
for(int i=0;i<m+1;i++) shift[i]=0;
//do preprocessing
preprocess_strong_suffix(shift, bpos, pat, m);
preprocess_case2(shift, bpos, pat, m);
while(s <= n-m)
{
j = m-1;
/* Keep reducing index j of pattern while characters of
pattern and text are matching at this shift s*/
while(j >= 0 && pat[j] == text[s+j])
j--;
/* If the pattern is present at the current shift, then index j
will become -1 after the above loop */
if (j<0)
{
printf("pattern occurs at shift = %d\n", s);
s += shift[0];
}
else
/*pat[i] != pat[s+j] so shift the pattern
shift[j+1] times */
s += shift[j+1];
}
}
//Driver
int main()
{
char text[] = "ABAAAABAACD";
char pat[] = "ABA";
search(text, pat);
return 0;
}
Java
/* Java program for Boyer Moore Algorithm with
Good Suffix heuristic to find pattern in
given text string */
class GFG
{
// preprocessing for strong good suffix rule
static void preprocess_strong_suffix(int []shift, int []bpos,
char []pat, int m)
{
// m is the length of pattern
int i = m, j = m + 1;
bpos[i] = j;
while(i > 0)
{
/*if character at position i-1 is not
equivalent to character at j-1, then
continue searching to right of the
pattern for border */
while(j <= m && pat[i - 1] != pat[j - 1])
{
/* the character preceding the occurrence of t
in pattern P is different than the mismatching
character in P, we stop skipping the occurrences
and shift the pattern from i to j */
if (shift[j] == 0)
shift[j] = j - i;
//Update the position of next border
j = bpos[j];
}
/* p[i-1] matched with p[j-1], border is found.
store the beginning position of border */
i--; j--;
bpos[i] = j;
}
}
//Preprocessing for case 2
static void preprocess_case2(int []shift, int []bpos,
char []pat, int m)
{
int i, j;
j = bpos[0];
for(i = 0; i <= m; i++)
{
/* set the border position of the first character
of the pattern to all indices in array shift
having shift[i] = 0 */
if(shift[i] == 0)
shift[i] = j;
/* suffix becomes shorter than bpos[0],
use the position of next widest border
as value of j */
if (i == j)
j = bpos[j];
}
}
/*Search for a pattern in given text using
Boyer Moore algorithm with Good suffix rule */
static void search(char []text, char []pat)
{
// s is shift of the pattern
// with respect to text
int s = 0, j;
int m = pat.length;
int n = text.length;
int []bpos = new int[m + 1];
int []shift = new int[m + 1];
//initialize all occurrence of shift to 0
for(int i = 0; i < m + 1; i++)
shift[i] = 0;
//do preprocessing
preprocess_strong_suffix(shift, bpos, pat, m);
preprocess_case2(shift, bpos, pat, m);
while(s <= n - m)
{
j = m - 1;
/* Keep reducing index j of pattern while
characters of pattern and text are matching
at this shift s*/
while(j >= 0 && pat[j] == text[s+j])
j--;
/* If the pattern is present at the current shift,
then index j will become -1 after the above loop */
if (j < 0)
{
System.out.printf("pattern occurs at shift = %d\n", s);
s += shift[0];
}
else
/*pat[i] != pat[s+j] so shift the pattern
shift[j+1] times */
s += shift[j + 1];
}
}
// Driver Code
public static void main(String[] args)
{
char []text = "ABAAAABAACD".toCharArray();
char []pat = "ABA".toCharArray();
search(text, pat);
}
}
// This code is contributed by 29AjayKumar
Python3
# Python3 program for Boyer Moore Algorithm with
# Good Suffix heuristic to find pattern in
# given text string
# preprocessing for strong good suffix rule
def preprocess_strong_suffix(shift, bpos, pat, m):
# m is the length of pattern
i = m
j = m + 1
bpos[i] = j
while i > 0:
'''if character at position i-1 is
not equivalent to character at j-1,
then continue searching to right
of the pattern for border '''
while j <= m and pat[i - 1] != pat[j - 1]:
''' the character preceding the occurrence
of t in pattern P is different than the
mismatching character in P, we stop skipping
the occurrences and shift the pattern
from i to j '''
if shift[j] == 0:
shift[j] = j - i
# Update the position of next border
j = bpos[j]
''' p[i-1] matched with p[j-1], border is found.
store the beginning position of border '''
i -= 1
j -= 1
bpos[i] = j
# Preprocessing for case 2
def preprocess_case2(shift, bpos, pat, m):
j = bpos[0]
for i in range(m + 1):
''' set the border position of the first character
of the pattern to all indices in array shift
having shift[i] = 0 '''
if shift[i] == 0:
shift[i] = j
''' suffix becomes shorter than bpos[0],
use the position of next widest border
as value of j '''
if i == j:
j = bpos[j]
'''Search for a pattern in given text using
Boyer Moore algorithm with Good suffix rule '''
def search(text, pat):
# s is shift of the pattern with respect to text
s = 0
m = len(pat)
n = len(text)
bpos = [0] * (m + 1)
# initialize all occurrence of shift to 0
shift = [0] * (m + 1)
# do preprocessing
preprocess_strong_suffix(shift, bpos, pat, m)
preprocess_case2(shift, bpos, pat, m)
while s <= n - m:
j = m - 1
''' Keep reducing index j of pattern while characters of
pattern and text are matching at this shift s'''
while j >= 0 and pat[j] == text[s + j]:
j -= 1
''' If the pattern is present at the current shift,
then index j will become -1 after the above loop '''
if j < 0:
print("pattern occurs at shift = %d" % s)
s += shift[0]
else:
'''pat[i] != pat[s+j] so shift the pattern
shift[j+1] times '''
s += shift[j + 1]
# Driver Code
if __name__ == "__main__":
text = "ABAAAABAACD"
pat = "ABA"
search(text, pat)
# This code is contributed by
# sanjeev2552
C#
/* C# program for Boyer Moore Algorithm with
Good Suffix heuristic to find pattern in
given text string */
using System;
class GFG
{
// preprocessing for strong good suffix rule
static void preprocess_strong_suffix(int []shift,
int []bpos,
char []pat, int m)
{
// m is the length of pattern
int i = m, j = m + 1;
bpos[i] = j;
while(i > 0)
{
/*if character at position i-1 is not
equivalent to character at j-1, then
continue searching to right of the
pattern for border */
while(j <= m && pat[i - 1] != pat[j - 1])
{
/* the character preceding the occurrence of t
in pattern P is different than the mismatching
character in P, we stop skipping the occurrences
and shift the pattern from i to j */
if (shift[j] == 0)
shift[j] = j - i;
//Update the position of next border
j = bpos[j];
}
/* p[i-1] matched with p[j-1], border is found.
store the beginning position of border */
i--; j--;
bpos[i] = j;
}
}
//Preprocessing for case 2
static void preprocess_case2(int []shift, int []bpos,
char []pat, int m)
{
int i, j;
j = bpos[0];
for(i = 0; i <= m; i++)
{
/* set the border position of the first character
of the pattern to all indices in array shift
having shift[i] = 0 */
if(shift[i] == 0)
shift[i] = j;
/* suffix becomes shorter than bpos[0],
use the position of next widest border
as value of j */
if (i == j)
j = bpos[j];
}
}
/*Search for a pattern in given text using
Boyer Moore algorithm with Good suffix rule */
static void search(char []text, char []pat)
{
// s is shift of the pattern
// with respect to text
int s = 0, j;
int m = pat.Length;
int n = text.Length;
int []bpos = new int[m + 1];
int []shift = new int[m + 1];
// initialize all occurrence of shift to 0
for(int i = 0; i < m + 1; i++)
shift[i] = 0;
// do preprocessing
preprocess_strong_suffix(shift, bpos, pat, m);
preprocess_case2(shift, bpos, pat, m);
while(s <= n - m)
{
j = m - 1;
/* Keep reducing index j of pattern while
characters of pattern and text are matching
at this shift s*/
while(j >= 0 && pat[j] == text[s + j])
j--;
/* If the pattern is present at the current shift,
then index j will become -1 after the above loop */
if (j < 0)
{
Console.Write("pattern occurs at shift = {0}\n", s);
s += shift[0];
}
else
/*pat[i] != pat[s+j] so shift the pattern
shift[j+1] times */
s += shift[j + 1];
}
}
// Driver Code
public static void Main(String[] args)
{
char []text = "ABAAAABAACD".ToCharArray();
char []pat = "ABA".ToCharArray();
search(text, pat);
}
}
// This code is contributed by PrinciRaj1992
Producción:
pattern occurs at shift = 0 pattern occurs at shift = 5
Referencias
Este artículo es una contribución de Atul Kumar . Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo usando contribuya.geeksforgeeks.org o envíe su artículo por correo a contribuya@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA