Una simulación de eventos discretos modela la operación de un sistema como una serie de eventos en el tiempo. Cada evento ocurre en un instante particular en el tiempo y entre estas instancias se supone que el sistema no cambia.
El algoritmo de pasos de secuencia se implementa en un sistema de simulación de eventos discretos para maximizar la utilización de recursos. Permite el desarrollo de modelos de simulación basados en recursos para programar proyectos repetitivos con duración de actividad probabilística mientras se mantiene la utilización continua de recursos.
Para decirlo en palabras más simples, supongamos la construcción de un edificio de varios pisos. En cada piso se debe hacer el mismo trabajo, por ejemplo, considere pintar el piso 10, para estas paredes de los pisos 10 se deben construir y el equipo de pintura debe haber pintado el piso 9. Ahora, si por alguna razón el equipo terminó de pintar el piso 9 pero las paredes del piso 10 aún no están completamente construidas, entonces el equipo se quedaría inactivo y se le pagaría por esos días sin hacer nada. Aquí es donde entra el algoritmo.
El algoritmo funciona en la programación de proyectos repetitivos, donde la duración de la actividad en cada unidad puede variar debido a la productividad de los recursos o las diferencias en la cantidad de trabajo entre las unidades, de modo que las cuadrillas puedan trabajar continuamente sin interrupción. El algoritmo de pasos de secuencia es el primero en abordar el problema de programar proyectos repetitivos probabilísticos para eliminar el tiempo de inactividad de la tripulación.
El algoritmo se puede adaptar fácilmente a diferentes software de simulación basados en recursos agregando dos bucles anidados: un bucle de replicación interno y un bucle de paso de secuencia externo.
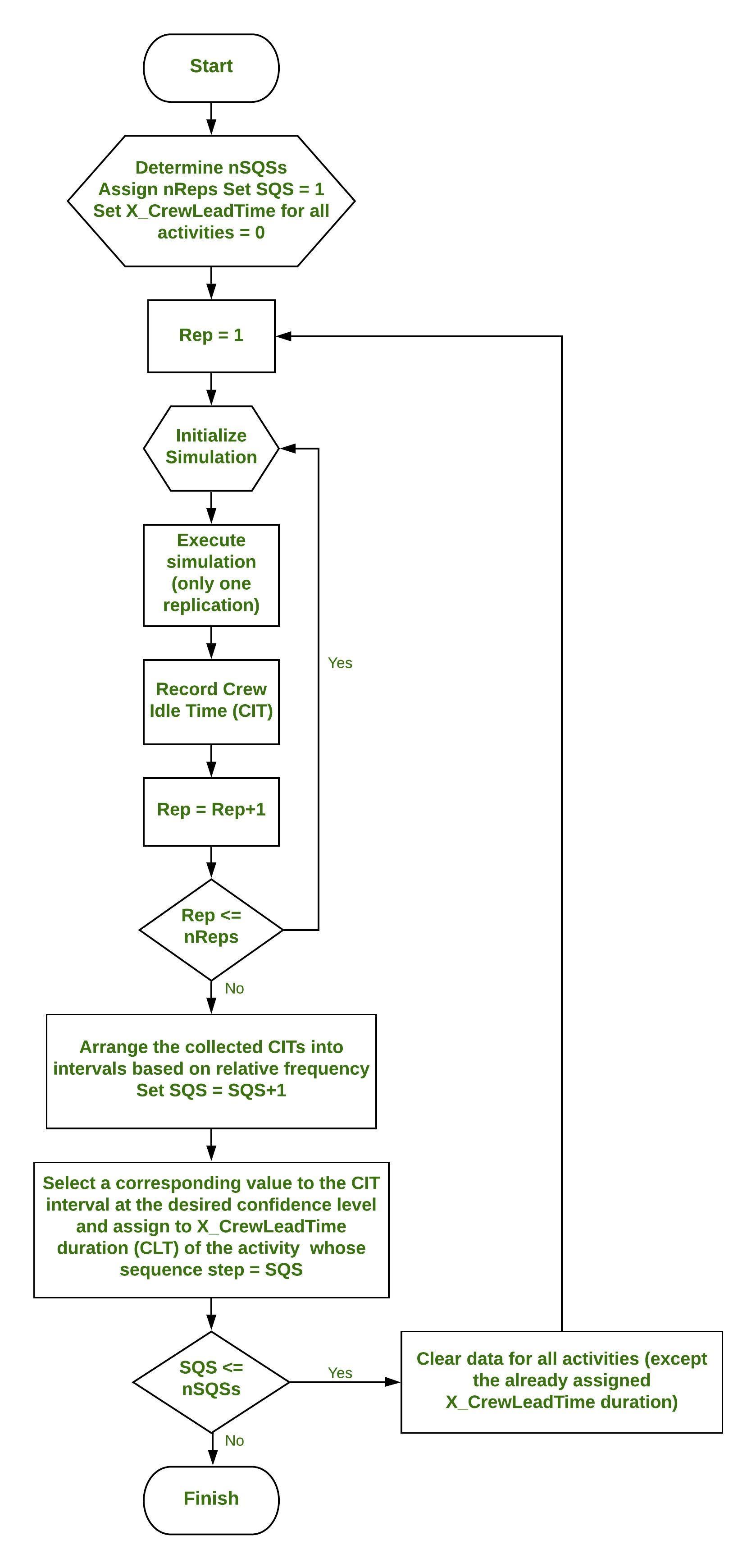
Hay tres pasos generales:
- El primer paso es simular la red y el tiempo de recopilación (CIT) durante el cual el equipo está inactivo en cada réplica del proyecto. Después de realizar una serie de replicaciones, las muestras de CIT se organizan en intervalos similares a histogramas en función de la frecuencia relativa.
- En el segundo paso, decidimos una cierta probabilidad acumulativa para CIT que calculamos en el primer paso y asignamos el valor de tiempo correspondiente a la duración de X_CrewLeadTime , que inicialmente fue 0 para todas las actividades.
- En el tercer paso, restablecemos el modelo de simulación y borramos todas las estadísticas CIT recopiladas previamente para todas las actividades. Usando duraciones X_CrewLeadTime (CLT) ya asignadas para todas las actividades en pasos de secuencia anteriores, pasamos al siguiente paso de secuencia y repetimos el primer y segundo paso del algoritmo hasta llegar al último paso de secuencia.
Diagrama de flujo –
Publicación traducida automáticamente
Artículo escrito por jnikita356 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA