Requisito previo: clasificación de analizadores de arriba hacia abajo El análisis
predictivo es una forma especial de análisis descendente recursivo, donde no se requiere retroceso, por lo que puede predecir qué productos usar para reemplazar la string de entrada. El análisis sintáctico predictivo no recursivo o basado en tablas también se conoce como analizador LL(1). Este analizador sigue la derivación más a la izquierda (LMD).
LL(1): here, first L is for Left to Right scanning of inputs, the second L is for left most derivation procedure, 1 = Number of Look Ahead Symbols
El principal problema durante el análisis predictivo es el de determinar la producción que se aplicará a un no terminal.
Este analizador no recursivo busca qué producto se aplicará en una tabla de análisis. Un analizador LL(1) tiene los siguientes componentes:
(1) buffer: an input buffer which contains the string to be passed
(2) stack: a pushdown stack which contains a sequence of grammar symbols
(3) A parsing table: a 2d array M[A, a]
where
A->non-terminal, a->terminal or $
(4) output stream:
end of the stack and an end of the input symbols are both denoted with $
Algoritmo para el análisis predictivo no recursivo:
el concepto principal -> Con la ayuda de los conjuntos FIRST() y FOLLOW() , este análisis se puede realizar utilizando solo una pila que evita las llamadas recursivas.
Para cada regla, A->x en la gramática G:
- Para cada terminal ‘a’ contenida en FIRST(A), agregue A->x a M[A, a] en la tabla de análisis si x deriva ‘a’ como el primer símbolo.
- Si FIRST(A) contiene producción nula para cada terminal ‘b’ en FOLLOW(A) , agregue esta producción (A->null) a M[A, b] en la tabla de análisis.
El procedimiento:
- Al principio, la pila pushdown contiene el símbolo de inicio de la gramática G.
- En cada paso, se extrae un símbolo X de la pila:
si X es un terminal, entonces se compara con la búsqueda anticipada y la búsqueda anticipada avanza un paso;
si X es un símbolo no terminal, entonces se usa la búsqueda anticipada y una tabla de análisis (implementando los PRIMEROS conjuntos ) se elige una producción y su lado derecho se coloca en la pila.
- Este proceso se repite hasta que la pila y la string de entrada se vuelven nulas (vacías).
Algoritmo de análisis basado en tablas:
Entrada: una string w y una tabla de análisis sintáctico M para G.
tos top of the stack
Stack[tos++] <-$
Stack[tos++] <-Start Symbol
token <-next_token()
X <-Stack[tos]
repeat
if X is a terminal or $ then
if X = token then
pop X
token is next of token()
else error()
else /* X is a non-terminal */
if M[x, token] = X -> y1y2...yk then
pop x
push else error()
X Stack[tos]
until X = $
else error()
X Stack[tos]
until X = $
// Diagrama del modelo de analizador no recursivo:
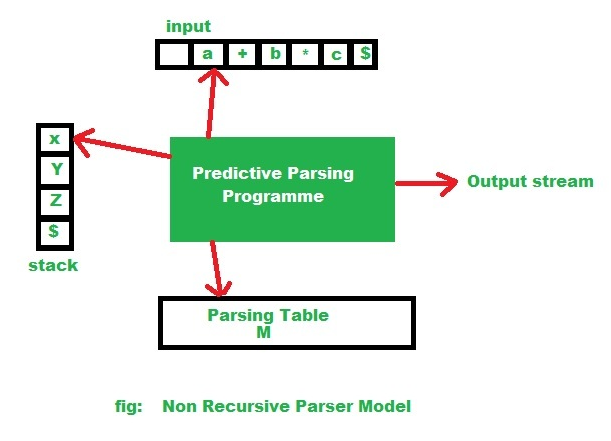
Entonces, de acuerdo con el diagrama dado, el algoritmo de análisis no recursivo.
Entrada: una string de entrada ‘w’ y una tabla de análisis (‘M’) para la gramática G.
Salida: si w está en L(G), un LMD de w; de lo contrario, una indicación de error.
Set input pointer to point to the first symbol of the string $;
repeat
let X be the symbol pointed by the stack pointer,
and a is the symbol pointed to by input pointer;
if X is a terminal or $ then
if X=a then
pop X from the stack and increment the input pointer;
else error()
end if
else /*if X is a non terminal */
if ![M[X, a]= x->y1 y2 ...yk](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-a1b179b8098043f960996344c8053ba9_l3.png "Rendered by QuickLaTeX.com") then
begin
pop X from the stack;
push
then
begin
pop X from the stack;
push  onto the stack, with Y1 on top;
output the production
onto the stack, with Y1 on top;
output the production end
else error()
end if
end if
until X=$ /* stack is empty */
end
else error()
end if
end if
until X=$ /* stack is empty */
Ejemplo: considere la siguiente gramática LL(1):
S -> A S -> ( S * A) A -> id
Ahora analicemos la entrada dada:
( id * id )
La tabla de análisis:
- fila-> para todos y cada uno de los símbolos no terminales,
- columna-> para todos y cada uno de los terminales (incluido el terminal especial).
Cada celda de esta tabla contendrá como máximo una regla de la gramática dada:
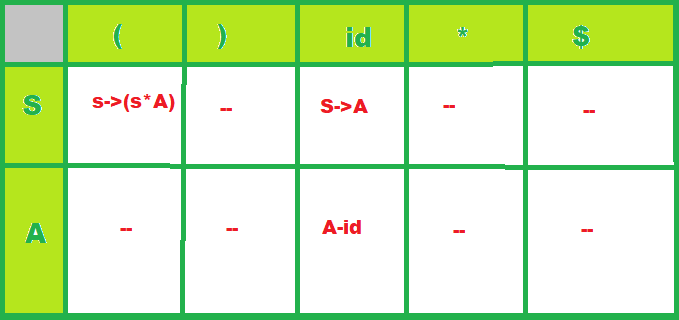
Ahora veamos usando el algoritmo, cómo el analizador usa esta tabla de análisis para procesar la entrada dada.
Procedimiento:
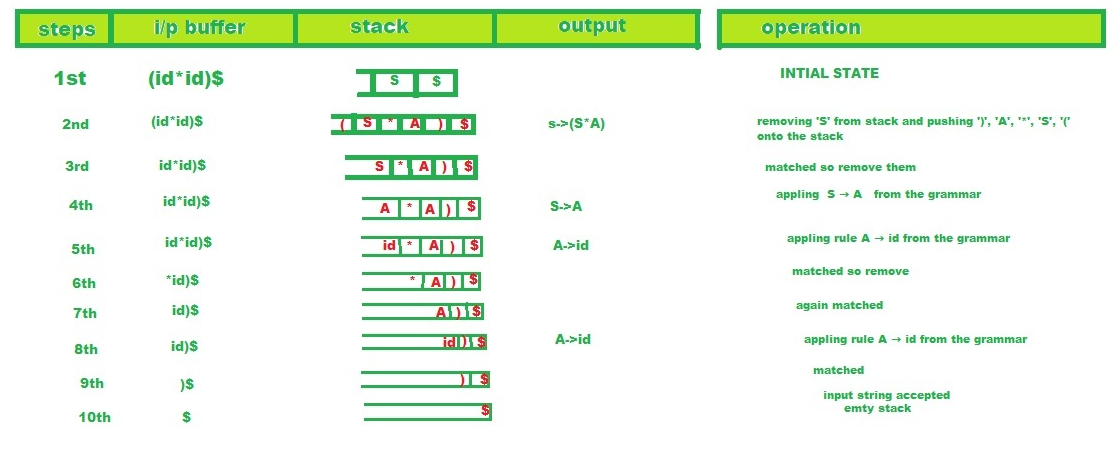
El analizador finaliza porque solo queda ‘$’ tanto en su pila como en su flujo de entrada. En este caso, el analizador informa que ha aceptado la string de entrada y escribe la siguiente lista de reglas en el flujo de salida:
S -> ( S * A), S -> A, A -> id, A -> id
De hecho, esta es una lista de reglas para un LMD de la string de entrada, que es:
S -> ( S * A ) -> ( A * A ) -> ( id * A ) -> ( id * id )
Publicación traducida automáticamente
Artículo escrito por PinakiBanerjee0 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA