Los sistemas operativos realizan la programación del disco para programar las requests de E/S que llegan al disco. La programación de discos también se conoce como programación de E/S.
La programación del disco es importante porque:
- Múltiples requests de E/S pueden llegar por diferentes procesos y el controlador de disco solo puede atender una solicitud de E/S a la vez. Por lo tanto, otras requests de E/S deben esperar en la cola de espera y deben programarse.
- Dos o más requests pueden estar lejos una de la otra, lo que puede resultar en un mayor movimiento del brazo del disco.
- Los discos duros son una de las partes más lentas del sistema informático y, por lo tanto, es necesario acceder a ellos de manera eficiente.
Hay muchos algoritmos de programación de disco, pero antes de discutirlos, echemos un vistazo rápido a algunos de los términos importantes:
- Tiempo de búsqueda : el tiempo de búsqueda es el tiempo necesario para ubicar el brazo del disco en una pista específica donde se leerán o escribirán los datos. Por lo tanto, el algoritmo de programación de disco que proporciona un tiempo de búsqueda promedio mínimo es mejor.
- Latencia de rotación: La latencia de rotación es el tiempo que tarda el sector deseado del disco en girar a una posición que le permita acceder a los cabezales de lectura/escritura. Por lo tanto, el algoritmo de programación del disco que proporciona una latencia de rotación mínima es mejor.
- Tiempo de transferencia: el tiempo de transferencia es el tiempo para transferir los datos. Depende de la velocidad de rotación del disco y del número de bytes a transferir.
- Tiempo de acceso al disco: El tiempo de acceso al disco es:
Disk Access Time = Seek Time +
Rotational Latency +
Transfer Time
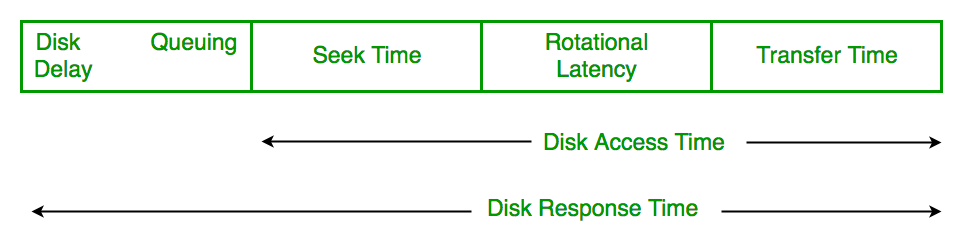
- Tiempo de respuesta del disco: el tiempo de respuesta es el promedio de tiempo que una solicitud tarda en esperar para realizar su operación de E/S. El tiempo de respuesta promedio es el tiempo de respuesta de todas las requests. El tiempo de respuesta de variación es una medida de cómo se atienden las requests individuales con respecto al tiempo de respuesta promedio. Por lo tanto, el algoritmo de programación de disco que proporciona un tiempo de respuesta de varianza mínima es mejor.
Algoritmos de programación de disco
- FCFS: FCFS es el más simple de todos los algoritmos de programación de disco. En FCFS, las requests se abordan en el orden en que llegan a la cola del disco. Comprendamos esto con la ayuda de un ejemplo.
Ejemplo:
- Supongamos que el orden de solicitud es- (82,170,43,140,24,16,190)
y la posición actual del cabezal de lectura/escritura es: 50
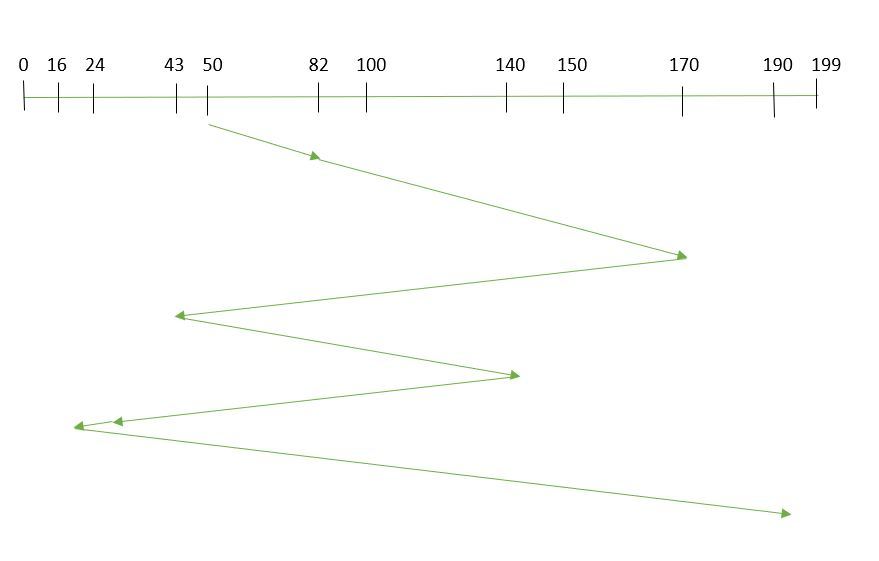
- Entonces, tiempo total de búsqueda:
=(82-50)+(170-82)+(170-43)+(140-43)+(140-24)+(24-16)+(190-16)
=642
ventajas:
- Cada solicitud tiene una oportunidad justa
- Sin aplazamiento indefinido
Desventajas:
- No intenta optimizar el tiempo de búsqueda.
- Puede que no brinde el mejor servicio posible
- SSTF: en SSTF (tiempo de búsqueda más corto primero), las requests que tienen el tiempo de búsqueda más corto se ejecutan primero. Por lo tanto, el tiempo de búsqueda de cada solicitud se calcula de antemano en la cola y luego se programan de acuerdo con su tiempo de búsqueda calculado. Como resultado, la solicitud cerca del brazo del disco se ejecutará primero. SSTF es ciertamente una mejora sobre FCFS, ya que reduce el tiempo de respuesta promedio y aumenta el rendimiento del sistema. Entendamos esto con la ayuda de un ejemplo.
Ejemplo:
- Supongamos que el orden de solicitud es- (82,170,43,140,24,16,190)
y la posición actual del cabezal de lectura/escritura es: 50
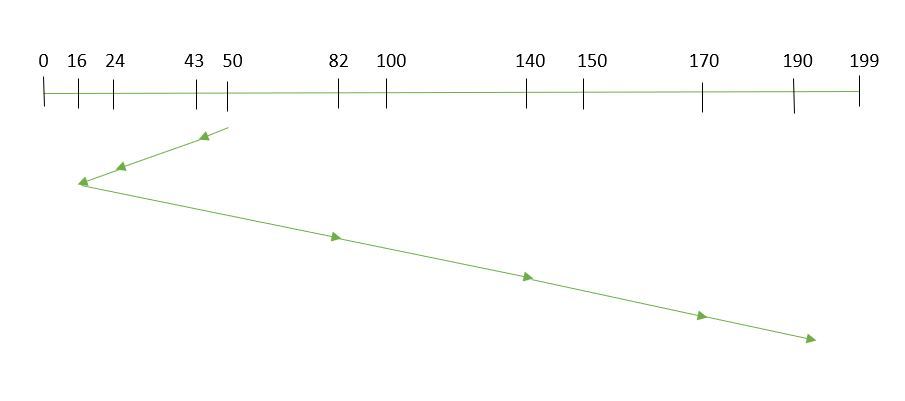
Entonces, tiempo total de búsqueda:
-
=(50-43)+(43-24)+(24-16)+(82-16)+(140-82)+(170-140)+(190-170)
=208
ventajas:
- Disminuye el tiempo de respuesta promedio
- Aumenta el rendimiento
Desventajas:
- Overhead para calcular el tiempo de búsqueda por adelantado
- Puede causar hambre para una solicitud si tiene un tiempo de búsqueda más alto en comparación con las requests entrantes
- Alta variación del tiempo de respuesta ya que SSTF favorece solo algunas requests
- SCAN: en el algoritmo SCAN, el brazo del disco se mueve en una dirección particular y atiende las requests que llegan en su camino y, después de llegar al final del disco, invierte su dirección y nuevamente atiende la solicitud que llega en su camino. Entonces, este algoritmo funciona como un ascensor y, por lo tanto, también se conoce como algoritmo de ascensor. Como resultado, las requests en el rango medio se atienden más y las que llegan detrás del brazo del disco tendrán que esperar.
Ejemplo:
- Supongamos que las requests a atender son-82,170,43,140,24,16,190. Y el brazo de lectura/escritura está en 50, y también se da que el brazo del disco debe moverse “hacia el valor mayor”.
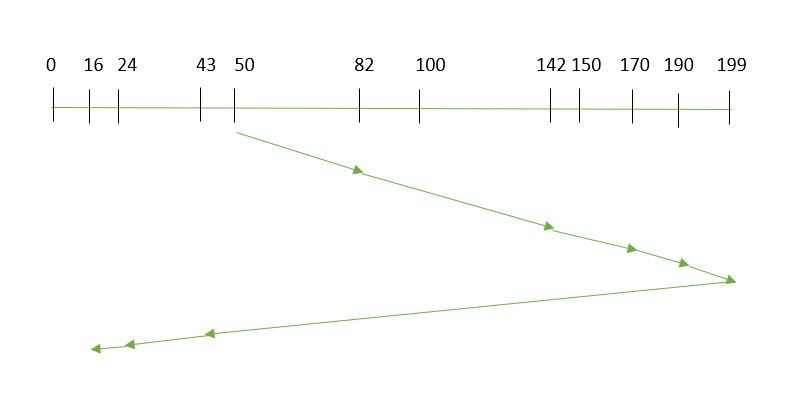
Por lo tanto, el tiempo de búsqueda se calcula como:
- =(199-50)+(199-16)
=332
ventajas:
- alto rendimiento
- Baja variación del tiempo de respuesta
- Tiempo promedio de respuesta
Desventajas:
- Largo tiempo de espera para requests de ubicaciones recién visitadas por brazo de disco
- CSCAN : en el algoritmo SCAN, el brazo del disco vuelve a escanear la ruta que se ha escaneado, después de invertir su dirección. Por lo tanto, es posible que haya demasiadas requests en espera en el otro extremo o que haya cero o pocas requests pendientes en el área escaneada.
Estas situaciones se evitan en el algoritmo CSCAN en el que el brazo del disco, en lugar de invertir su dirección, va al otro extremo del disco y comienza a atender las requests desde allí. Entonces, el brazo del disco se mueve de forma circular y este algoritmo también es similar al algoritmo SCAN y, por lo tanto, se conoce como C-SCAN (SCAN circular).
Ejemplo:
Supongamos que las requests a atender son-82,170,43,140,24,16,190. Y el brazo de lectura/escritura está en 50, y también se da que el brazo del disco debe moverse “hacia el valor mayor”.
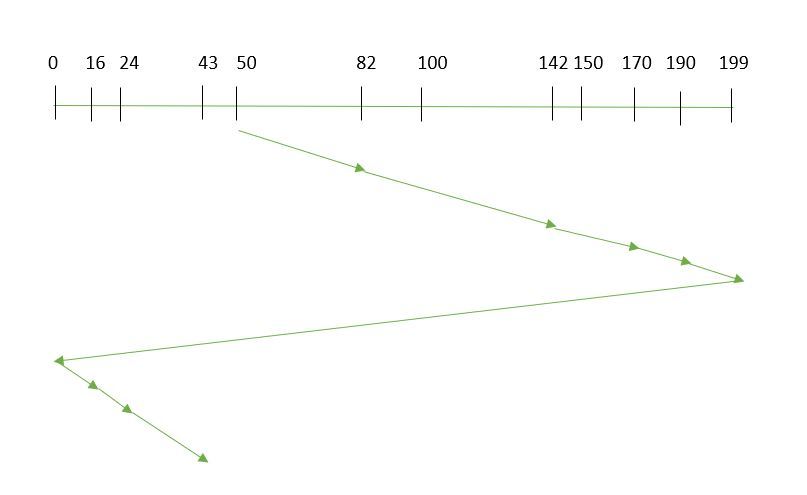
El tiempo de búsqueda se calcula como:
=(199-50)+(199-0)+(43-0)
=391
ventajas:
- Proporciona un tiempo de espera más uniforme en comparación con SCAN
- MIRAR: Es similar al algoritmo de programación de disco SCAN, excepto por la diferencia de que el brazo del disco, a pesar de ir al final del disco, va solo a la última solicitud para ser atendida frente al cabezal y luego invierte su dirección desde allí. solamente. Por lo tanto, evita el retraso adicional que se produjo debido a un recorrido innecesario hasta el final del disco.
Ejemplo:
- Supongamos que las requests a atender son-82,170,43,140,24,16,190. Y el brazo de lectura/escritura está en 50, y también se da que el brazo del disco debe moverse “hacia el valor mayor”.

Entonces, el tiempo de búsqueda se calcula como:
- =(190-50)+(190-16)
=314
- CLOOK: Como LOOK es similar al algoritmo SCAN, CLOOK es similar al algoritmo de programación de disco CSCAN. En CLOOK, el brazo del disco, a pesar de ir al final, va solo a la última solicitud a atender frente al cabezal y luego de allí va a la última solicitud del otro extremo. Por lo tanto, también evita el retraso adicional que se produjo debido a un recorrido innecesario hasta el final del disco.
Ejemplo:
- Supongamos que las requests a atender son-82,170,43,140,24,16,190. Y el brazo de lectura/escritura está en 50, y también se da que el brazo del disco debe moverse «hacia el valor mayor»

Entonces, el tiempo de búsqueda se calcula como:
-
=(190-50)+(190-16)+(43-16)
=341 - RSS : significa programación aleatoria y, al igual que su nombre, es naturaleza. Se utiliza en situaciones en las que la programación implica atributos aleatorios, como tiempo de procesamiento aleatorio, fechas de vencimiento aleatorias, pesos aleatorios y averías de máquinas estocásticas. Este algoritmo es perfecto. Es por eso que generalmente se usa para análisis y simulación.
- LIFO : en el algoritmo LIFO (Last In, First Out), los trabajos más nuevos se atienden antes que los existentes, es decir, en el orden de las requests que se atienden, el trabajo más nuevo o el último ingresado se atiende primero y luego el resto en el mismo orden.
Ventajas
- Maximiza la localidad y la utilización de recursos
- Puede parecer un poco injusto para otras requests y si siguen llegando nuevas requests, causará la inanición de las antiguas y existentes.
- ESCANEO N-PASO : también se conoce como algoritmo N-STEP LOOK. En este se crea un búfer para N requests. Todas las requests pertenecientes a un búfer serán atendidas de una sola vez. Además, una vez que el búfer está lleno, no se guardan nuevas requests en este búfer y se envían a otro. Ahora, cuando se atienden estas N requests, llega el momento de otras N requests principales y, de esta manera, todas las requests obtienen un servicio garantizado.
Ventajas
- Elimina completamente el hambre de requests.
- FSCAN : este algoritmo utiliza dos subcolas. Durante el escaneo, se atienden todas las requests en la primera cola y las nuevas requests entrantes se agregan a la segunda cola. Todas las requests nuevas se detienen hasta que se atienden las requests existentes en la primera cola.
Ventajas- FSCAN junto con N-Step-SCAN evita la «permanencia del brazo» (fenómenos en la programación de E/S en los que el algoritmo de programación continúa atendiendo las requests en el sector actual o cerca de él y, por lo tanto, evita cualquier búsqueda)
Cada algoritmo es único a su manera. El rendimiento general depende del número y tipo de requests.
Nota: La latencia de rotación promedio generalmente se toma como 1/2 (latencia de rotación).
Ejercicio
1) Suponga que un disco tiene 201 cilindros, numerados del 0 al 200. En algún momento, el brazo del disco está en el cilindro 100 y hay una cola de requests de acceso al disco para los cilindros 30, 85, 90, 100, 105, 110, 135 y 145. Si se utiliza primero el tiempo de búsqueda más corto (SSTF) para programar el acceso al disco, la solicitud del cilindro 90 se atiende después de atender ____________ número de requests. (GATE CS 2014
(A) 1
(B) 2
(C) 3
(D) 4
Vea esto para la solución.
2) Considere un sistema operativo capaz de cargar y ejecutar un solo proceso de usuario secuencial a la vez. El algoritmo de programación de cabezales de disco utilizado es First Come First Served (FCFS). Si FCFS se reemplaza por Shortest Seek Time First (SSTF), que según el proveedor ofrece un 50 % de mejores resultados de referencia, ¿cuál es la mejora esperada en el rendimiento de E/S de los programas de usuario? (GATE CS 2004)
(A) 50 %
(B) 40 %
(C) 25 %
(D) 0 %
Vea esto para la solución.
3) Suponga que se da la siguiente secuencia de solicitud de disco (números de pista) para un disco con 100 pistas: 45, 20, 90, 10, 50, 60, 80, 25, 70. Suponga que la posición inicial del cabezal R/W está en la pista 50. La distancia adicional que recorrerá el cabezal R/W cuando se use el algoritmo Shortest Seek Time First (SSTF) en comparación con el algoritmo SCAN (Elevator) (suponiendo que el algoritmo SCAN se mueva hacia 100 cuando comience la ejecución ) es _________ pistas
(A) 8
(B) 9
(C) 10
(D) 11
Vea esto para la solución.
4) Considere un disco típico que gira a 15000 revoluciones por minuto (RPM) y tiene una velocidad de transferencia de 50 × 10^6 bytes/seg. Si el tiempo de búsqueda promedio del disco es el doble del retraso de rotación promedio y el tiempo de transferencia del controlador es 10 veces el tiempo de transferencia del disco, el tiempo promedio (en milisegundos) para leer o escribir un sector de 512 bytes del disco es _____________
Ver esto para solución.
Este artículo es una contribución de Ankit Mittal . Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA