El analizador léxico escanea la entrada de izquierda a derecha, un carácter a la vez. Utiliza dos punteros begin ptr( bp ) y forward para realizar un seguimiento del puntero de la entrada escaneada.

Inicialmente, ambos punteros apuntan al primer carácter de la string de entrada, como se muestra a continuación.
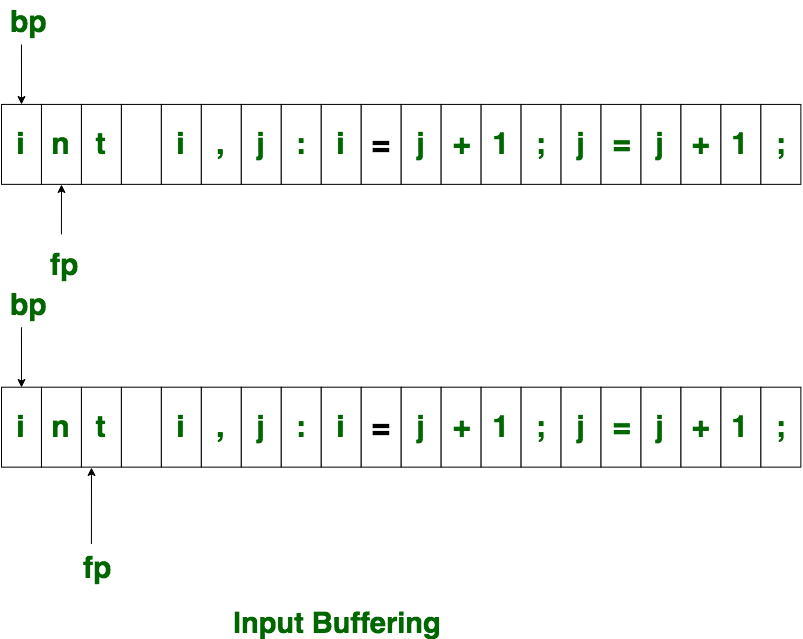
El ptr de avance avanza para buscar el final del lexema. Tan pronto como se encuentra el espacio en blanco, indica el final del lexema. En el ejemplo anterior, tan pronto como ptr (fp) encuentra un espacio en blanco, se identifica el lexema «int».
El fp se moverá hacia adelante en el espacio en blanco, cuando fp encuentra un espacio en blanco, lo ignora y avanza. luego, tanto el ptr de inicio (bp) como el ptr de avance (fp) se establecen en el siguiente token.
Por lo tanto, el carácter de entrada se lee desde el almacenamiento secundario, pero la lectura de este modo desde el almacenamiento secundario es costosa. por lo tanto, se utiliza la técnica de almacenamiento en búfer. Primero se lee un bloque de datos en un búfer y luego, en segundo lugar, mediante un analizador léxico. Hay dos métodos utilizados en este contexto: un esquema de búfer y un esquema de dos búfer. Estos se explican a continuación a continuación.
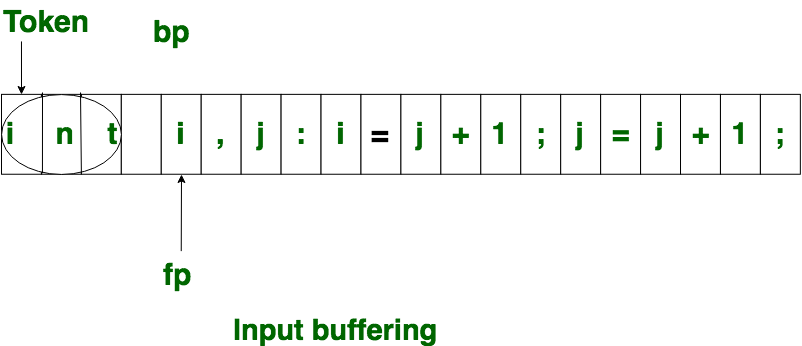
- Esquema de un búfer:
en este esquema, solo se usa un búfer para almacenar la string de entrada, pero el problema con este esquema es que si el lexema es muy largo, cruza el límite del búfer, para escanear el resto del lexema, el búfer debe rellenarse. , que hace que se sobrescriba el primero de lexema.
- Esquema de dos búferes:
para superar el problema del esquema de un búfer, en este método se utilizan dos búferes para almacenar la string de entrada. el primer búfer y el segundo búfer se exploran alternativamente. cuando se alcanza el final del búfer actual, se llena el otro búfer. el único problema con este método es que si la longitud del lexema es mayor que la longitud del búfer, entonces la entrada de escaneo no se puede escanear por completo.Inicialmente, tanto bp como fp apuntan al primer carácter del primer búfer. Entonces el fp se mueve hacia la derecha en busca del final del lexema. tan pronto como se reconoce el carácter en blanco, la string entre bp y fp se identifica como el token correspondiente. para identificar, el límite del primer búfer al final del carácter del búfer debe colocarse al final del primer búfer.
De manera similar, el final del segundo búfer también se reconoce por la marca de fin de búfer presente al final del segundo búfer. cuando fp encuentra el primer eof , entonces uno puede reconocer el final del primer búfer y, por lo tanto, se inicia el llenado del segundo búfer. de la misma manera cuando se obtiene el segundo eof entonces indica de segundo buffer. alternativamente, ambos búferes se pueden llenar hasta que se identifique el final del programa de entrada y el flujo de tokens. Este carácter eof introducido al final llama a Sentinel , que se utiliza para identificar el final del búfer.
