El análisis de componentes principales (PCA) en la programación R es un análisis de los componentes lineales de todos los atributos existentes. Los componentes principales son combinaciones lineales (transformación ortogonal) del predictor original en el conjunto de datos. Es una técnica útil para EDA (análisis exploratorio de datos) y le permite visualizar mejor las variaciones presentes en un conjunto de datos con muchas variables.
R – Análisis de Componentes Principales
El primer componente principal captura la variación máxima en el conjunto de datos. Determina la dirección de mayor variabilidad. El segundo componente principal captura la variación restante en los datos y no está correlacionado con PC1. La correlación entre PC1 y PC2 debe ser cero. Entonces, todos los componentes principales sucesivos siguen el mismo concepto. Capturan la varianza restante sin estar correlacionados con el componente principal anterior.
El conjunto de datos
El conjunto de datos mtcars (prueba de carretera de automóviles de tendencia del motor) comprende el consumo de combustible y 10 aspectos del diseño y el rendimiento del automóvil para 32 automóviles. Viene preinstalado con el paquete dplyr en R.
R
# Installing required package
install.packages("dplyr")
# Loading the package
library(dplyr)
# Importing excel file
str(mtcars)
Producción:
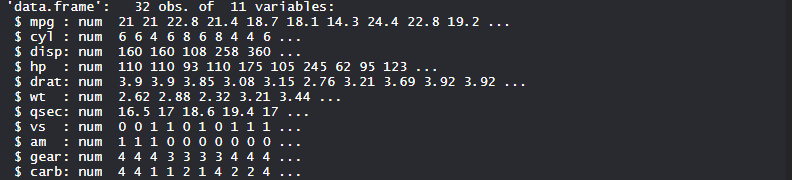
Análisis de componentes principales con lenguaje R usando un conjunto de datos
Realizamos un análisis de componentes principales en mtcars , que consta de 32 marcas de automóviles y 10 variables.
R
# Loading Data
data(mtcars)
# Apply PCA using prcomp function
# Need to scale / Normalize as
# PCA depends on distance measure
my_pca <- prcomp(mtcars, scale = TRUE,
center = TRUE, retx = T)
names(my_pca)
# Summary
summary(my_pca)
my_pca
# View the principal component loading
# my_pca$rotation[1:5, 1:4]
my_pca$rotation
# See the principal components
dim(my_pca$x)
my_pca$x
# Plotting the resultant principal components
# The parameter scale = 0 ensures that arrows
# are scaled to represent the loadings
biplot(my_pca, main = "Biplot", scale = 0)
# Compute standard deviation
my_pca$sdev
# Compute variance
my_pca.var <- my_pca$sdev ^ 2
my_pca.var
# Proportion of variance for a scree plot
propve <- my_pca.var / sum(my_pca.var)
propve
# Plot variance explained for each principal component
plot(propve, xlab = "principal component",
ylab = "Proportion of Variance Explained",
ylim = c(0, 1), type = "b",
main = "Scree Plot")
# Plot the cumulative proportion of variance explained
plot(cumsum(propve),
xlab = "Principal Component",
ylab = "Cumulative Proportion of Variance Explained",
ylim = c(0, 1), type = "b")
# Find Top n principal component
# which will atleast cover 90 % variance of dimension
which(cumsum(propve) >= 0.9)[1]
# Predict mpg using first 4 new Principal Components
# Add a training set with principal components
train.data <- data.frame(disp = mtcars$disp, my_pca$x[, 1:4])
# Running a Decision tree algporithm
## Installing and loading packages
install.packages("rpart")
install.packages("rpart.plot")
library(rpart)
library(rpart.plot)
rpart.model <- rpart(disp ~ .,
data = train.data, method = "anova")
rpart.plot(rpart.model)
Producción:
- Parcela bi
- Los componentes principales resultantes se trazan como Biplot . El valor de escala 0 representa que las flechas están escaladas representando las cargas.
- Varianza explicada para cada componente principal
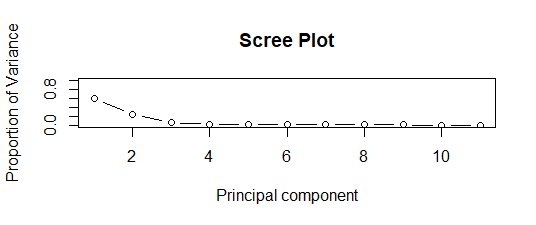
- Scree Plot representa la proporción de varianza y un componente principal. Por debajo de 2 componentes principales, hay una proporción máxima de varianza como se ve claramente en la gráfica.
- Proporción acumulada de la varianza
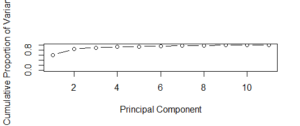
- Scree Plot representa la proporción acumulada de varianza y un componente principal. Por encima de 2 componentes principales, hay una proporción acumulada máxima de varianza como se ve claramente en la gráfica.
- Modelo de árbol de decisión
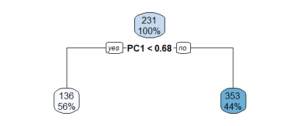
- El modelo de árbol de decisión se construyó para predecir la disp usando otras variables en el conjunto de datos y usando el método ANOVA. El gráfico del árbol de decisión se traza y muestra la información.