¿Qué es el análisis exploratorio de datos (EDA)?
EDA es un fenómeno bajo el análisis de datos utilizado para obtener una mejor comprensión de los aspectos de los datos como:
– características principales de los datos
– variables y relaciones que se mantienen entre ellas
– identificar qué variables son importantes para nuestro problema
Veremos varios métodos exploratorios de análisis de datos como :
- Estadística descriptiva, que es una forma de dar una breve descripción del conjunto de datos que estamos tratando, incluidas algunas medidas y características de la muestra.
- Agrupación de datos [Agrupación básica con agrupar por ]
- ANOVA, análisis de varianza, que es un método computacional para dividir las variaciones en un conjunto de observaciones en diferentes componentes.
- Correlación y métodos de correlación.
El conjunto de datos que usaremos es un conjunto de datos de votación infantil, que puede importar en python como:
Python3
import pandas as pd
Df = pd.read_csv("https://vincentarelbundock.github.io / Rdatasets / csv / car / Child.csv")
Estadísticas descriptivas
Las estadísticas descriptivas son una forma útil de comprender las características de sus datos y obtener un resumen rápido de los mismos. Pandas en python proporciona un método interesante describe() . La función de descripción aplica cálculos estadísticos básicos en el conjunto de datos, como valores extremos, conteo de puntos de datos, desviación estándar, etc. Cualquier valor faltante o valor de NaN se omite automáticamente. La función describe() da una buena imagen de la distribución de datos.
Python3
DF.describe()
Aquí está el resultado que obtendrá al ejecutar el código anterior:
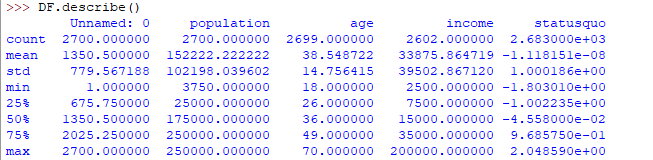
Otro método útil es value_counts(), que puede obtener el recuento de cada categoría en una serie de valores atribuidos categóricamente. Por ejemplo, suponga que está tratando con un conjunto de datos de clientes que se dividen en categorías jóvenes, medianas y mayores bajo el nombre de columna edad y su marco de datos es «DF». Puede ejecutar esta declaración para saber cuántas personas se encuentran en las respectivas categorías. En nuestro ejemplo de conjunto de datos, se puede utilizar la columna de educación
Python3
DF["education"].value_counts()
La salida del código anterior será:
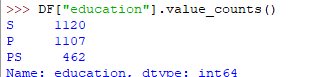
Una herramienta más útil es boxplot que puede usar a través del módulo matplotlib. Boxplot es una representación gráfica de la distribución de datos que muestra los valores extremos, la mediana y los cuartiles. Podemos averiguar fácilmente los valores atípicos mediante el uso de diagramas de caja. Ahora considere el conjunto de datos con el que hemos estado tratando nuevamente y dibujemos un diagrama de caja en la población de atributos
Python3
import pandas as pd
import matplotlib.pyplot as plt
DF = pd.read_csv("https://raw.githubusercontent.com / fivethirtyeight / data / master / airline-safety / airline-safety.csv")
y = list(DF.population)
plt.boxplot(y)
plt.show()
El gráfico de salida se vería así con la detección de valores atípicos:
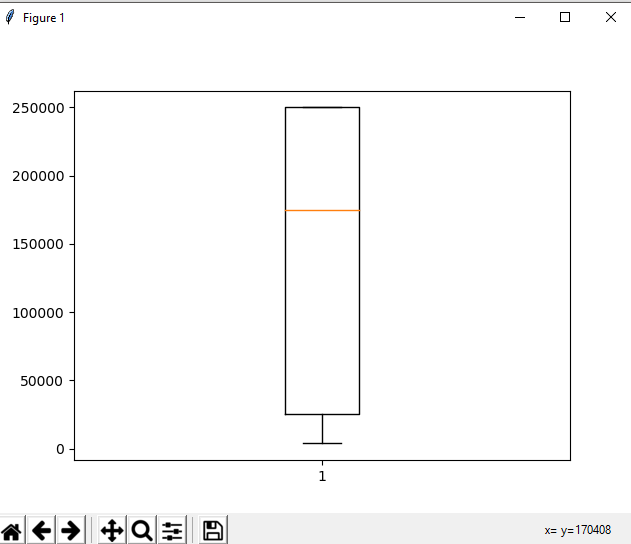
Agrupación de datos
Agrupar por es una medida interesante disponible en pandas que puede ayudarnos a determinar el efecto de diferentes atributos categóricos en otras variables de datos. Veamos un ejemplo en el mismo conjunto de datos en el que queremos averiguar el efecto de la edad y la educación de las personas en el conjunto de datos de votación.
Python3
DF.groupby(['education', 'vote']).mean()
La salida sería algo así:
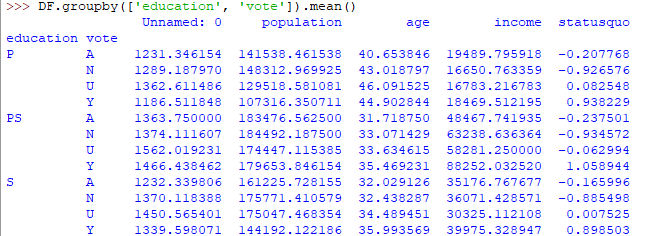
Si este grupo por tabla de salida es menos comprensible, los analistas adicionales usan tablas dinámicas y mapas de calor para visualizarlas.
ANOVA
ANOVA significa Análisis de Varianza. Se realiza para averiguar la relación entre los diferentes grupos de datos categóricos.
Bajo ANOVA tenemos dos medidas como resultado:
– F-testscore: que muestra la variación de la media de los grupos sobre la variación
– valor p: muestra la importancia del resultado
Esto se puede realizar usando el nombre del método scipy del módulo python f_oneway()
Sintaxis:
Estas muestras son medidas de muestra para cada grupo.
Como conclusión, podemos decir que existe una fuerte correlación entre otras variables y una variable categórica si la prueba ANOVA nos da un valor de prueba F grande y un valor de p pequeño.
Correlación y cálculo de correlación
La correlación es una relación simple entre dos variables en un contexto tal que una variable afecta a la otra. La correlación es diferente del acto de causar . Una forma de calcular la correlación entre variables es encontrar la correlación de Pearson. Aquí encontramos dos parámetros, a saber, el coeficiente de Pearson y el valor p. Podemos decir que existe una fuerte correlación entre dos variables cuando el coeficiente de correlación de Pearson está cerca de 1 o -1 y el valor de p es inferior a 0,0001.
El módulo Scipy también proporciona un método para realizar análisis de correlación de Pearson, sintaxis:
Aquí las muestras son los atributos que desea comparar.
Esta es una breve descripción general de EDA en Python, ¡podemos hacer mucho más! ¡Feliz excavación!
Publicación traducida automáticamente
Artículo escrito por KattamuriMeghna y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA