Usar los principios básicos de más de un campo para resolver un problema complicado puede ser muy difícil de lograr usando un área de conocimiento. Con este tipo de enfoque, también se pueden redefinir problemas fuera de los límites habituales y llegar a soluciones utilizando una nueva comprensión de situaciones impenetrables que antes se consideraban imposibles de conseguir.
Análisis de materiales
En términos sencillos, es un campo de estudio para analizar materiales y sus propiedades.
Científicamente: es un estudio para obtener información sobre las propiedades fundamentales de un material para determinar si el material es adecuado para el caso de uso previsto o si necesita algo de dopaje (o cualquier otro enfoque) para que esté bien calificado para el propósito.
Caso de uso: este estudio también se está integrando con la informática para obtener información mejor y más precisa sobre los datos sin tener mucha implementación práctica.
Ejemplo: si uno tiene una base de datos de, digamos, compuestos de Mn (manganeso) y su comportamiento magnético. El análisis de los mismos datos puede predecir las propiedades magnéticas de compuestos magnéticos desconocidos (cuyas propiedades aún son nuevas) utilizando un enfoque de aprendizaje automático.
descriptor
En el diccionario, se describe como una palabra o expresión utilizada para describir o identificar algo.
Se utiliza un descriptor para describir el compuesto a los algoritmos informáticos. Muchas representaciones de elementos de propiedades se pueden convertir en un formato matemático de vectores y arrays (como usar una codificación de vector caliente para describir una configuración electrónica de un elemento) para pasarlos como entrada a un algoritmo de aprendizaje automático.
Módulo Pymatgen
Pymatgen es una forma abreviada de Python Materials Genomics. Es una biblioteca de Python robusta, de código abierto y ampliamente utilizada para el análisis de materiales.
Nota: solo obtener la configuración electrónica, el número atómico o cualquier otra propiedad muy básica del material no tiene en cuenta el análisis del material.
Pymatgen es ampliamente preferido ya que es:
- Clases altamente flexibles para la representación de objetos Elemento, Sitio, Molécula, Estructura, Vecinos más cercanos.
- Variedad de formatos de entrada/salida como CIF, Gaussian, XYZ, VASP.
- Análisis de estructuras electrónicas, como la densidad de estados y la estructura de bandas.
- Potentes herramientas de análisis.
- Integración con la API REST de Materials Project, Crystallography Open Database y otras fuentes de datos externas.
- Es de uso gratuito, está bien documentado, es abierto y rápido.
Instalación
Como no es una biblioteca de python incorporada, es necesario instalarla externamente.
Primer método:
La instalación más sencilla es usando conda. Después de instalar conda:
conda install –canal conda-forge pymatgen
Pymatgen usa ‘gcc’ para la compilación, por lo que se requiere la última versión del mismo para compilar pymatgen.
conda instalar gcc
Pymatgen es de código abierto, por lo que se agregan nuevas funciones periódicamente. Entonces, para actualizar pymatgen a la última versión:
actualización de conda pymatgen
Segundo método:
Usando pipa:
pip instalar pymatgen
y para actualizar pymatgen
pip install –actualizar pymatgen
Tercer Método:
Para instalar pymatgen en google collab
!pip instalar pymatgen
Implementación
Detalles de un elemento y un compuesto
Obtención de detalles (como masa atómica, punto de fusión) de un elemento utilizando la clase Element de la biblioteca Pymatgen. Pase el símbolo del elemento como parámetro a la clase Element.
Del mismo modo, también se pueden obtener detalles de un compuesto.
Python3
import pymatgen.core as pg
# Fetch details of an Element
fe = pg.Element("Fe")
# Atomic mass
print('atomic mass: ', fe.atomic_mass)
print('atomic mass: ', fe.Z)
# Melting point
print('melting point: ', fe.melting_point)
# Fetch details of a composition
cmps = pg.Composition("NaCl")
print('weight of composition: ', cmps.weight)
# Composition allows strings to
# be treated as an Element object
# It returns the number of Cl
# atoms present in the composition
cmps["Cl"]
Producción:

Estructura y formatos de archivo
Pymatgen tiene muchas bibliotecas que se agrupan/separan según las propiedades que representan. Aquí, se crea la primera array de celosía diagonal pymatgen y luego se busca su estructura. Sin un nombre de archivo, se devuelve una string. De lo contrario, la salida se escribe en el archivo. Si solo se proporciona el nombre del archivo
Python3
# import module
import pymatgen.core as pg
from pymatgen.symmetry.analyzer import SpacegroupAnalyzer
# assign and display data
lattice = pg.Lattice.cubic(4.2)
print('LATTICE\n', lattice, '\n')
structure = pg.Structure(lattice, ["Li", "Cl"],
[[0, 0, 0],
[0.5, 0.5, 0.5]])
print('STRUCTURE', '\n', structure)
# Convert structure of the compound
# to user defined formats
structure.to(fmt="poscar")
structure.to(filename="POSCAR")
structure.to(filename="CsCl.cif")
Producción:
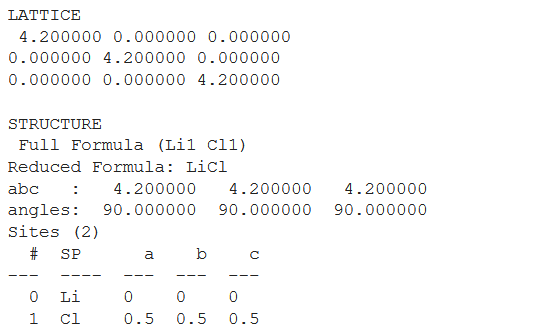
Recuperar estructura
Pymatgen también permite al usuario leer una estructura desde un archivo externo. Se puede lograr lo mismo de dos maneras usando una string y un archivo que se usan en el siguiente código. El archivo que vamos a buscar es la versión computada de MnO2.cif .
Python3
# Reading a structure from a file
structure = pg.Structure.from_str(open("MnO2.cif").read(),
fmt="cif")
structure = pg.Structure.from_file("MnO2.cif")
# Reading a molecule from a file
graphite = pg.Molecule.from_file("graphite.xyz")
# Writing the same molecule but in other file format
mol.to("graphite.cif")
Producción:
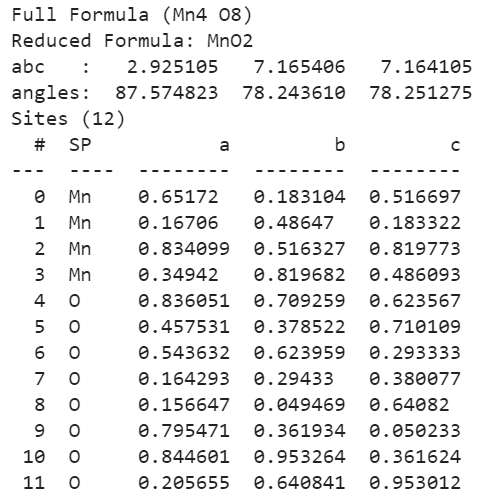
También puede funcionar como conversor de archivos, ya que permite leer una molécula de un archivo en un formato y escribir la misma molécula en un archivo de otro formato.
Fuentes de datos externas
Como se explicó anteriormente, pymatgen se puede vincular a diferentes fuentes de datos externas. Se puede acceder a los datos de Material Project en pymatgen usando la API MPRester del proyecto.
The Materials Project es una de esas bases de datos externas que ponen a disposición sus datos y análisis científicos a través de la API de interfaz de programación de aplicaciones de materiales abierta (también conocida como MPRester API, ya que se basa en los principios de transferencia de estado representacional (REST)). Es posible que esta API se pueda usar con cualquier lenguaje de programación que admita requests HTTP básicas; ya se ha implementado una envoltura para la API de MPRester en la biblioteca pymatgen para facilitar a los investigadores que deseen utilizar sus datos.
Consulte este sitio web para la generación de claves API -> https://materialsproject.org/open
Aquí primero, el objeto se crea a partir de la clave API y luego se consultan los datos de las propiedades de una identificación de tarea en particular (la identificación de la tarea se puede considerar como una identidad única de cada elemento presente en la base de datos de Material Project).
Nota: los nombres de las propiedades se mencionan en las propiedades. Si no hay tales datos de propiedad en particular, se recibe un objeto nulo para esa propiedad en particular.
Python3
# import module
from pymatgen.ext.matproj import MPRester
# create object
m = MPRester(API_key)
# fetch all the required properties of an element using mpid
# fetching details of a compound related to TaskId=mpid-1010
data_one = m.query(criteria={'task_id': 'mp-1010'},
properties=["full_formula",
"spacegroup.symbol",
"volume",
"nsites", "density",
"spacegroup.crystal_system",
"final_energy_per_atom",
"final_energy"])
# display fetched data
print(data_one)
El formato de salida está en la estructura de datos del diccionario para un acceso fácil y comprensible a la propiedad requerida
Producción:


En segundo lugar, obtener todos los datos de propiedades definidas (elementos y compuestos) de los compuestos de hierro (Fe).
Python3
# Fetch all the compounds details of an element in the database
# Fetching data of Fe-Iron
from pymatgen.ext.matproj import MPRester
import pandas as pd
m = MPRester(API_key)
data_s = m.query(criteria={"elements": {"$in": ["Fe"]}},
properties=["full_formula",
"spacegroup.symbol",
"volume",
"nsites", "density",
"spacegroup.crystal_system",
"final_energy_per_atom",
"final_energy"])
# convert data to pandas data
# frame and store it in .csv file
df = pd.DataFrame(data_s)
df.to_csv('all.csv')
# display data saved in all.csv
print(df)
El resultado de consultar todos los datos del elemento Fe está en formato de diccionario anidado y es muy grande para mostrarlo en la consola, por lo que primero se convierte en un marco de datos de pandas y luego se guarda como un archivo .csv.
PRODUCCIÓN:


Caso de uso de la vida real
Aquí, vamos a contar el número de átomos en un compuesto. Se puede hacer fácilmente obteniendo los detalles estructurales del compuesto en formato CIF, ya que contiene todas las ubicaciones de coordenadas de todos y cada uno de los átomos del compuesto.
Primero, elimine todo el texto innecesario del archivo y luego cuente el número de líneas restantes.
El compuesto CoNi3 está asociado con mp-1183751
Python3
# import module
from pymatgen.core import Structure
from pymatgen.ext.matproj import MPRester
import re
m = MPRester(API_key)
id = 'mp-1183751'
data_c = m.query(criteria={'task_id': id},
properties=[
'cifs.conventional_standard'])
# delete extras
with open('cnt.cif', 'w') as f:
filedata = str(data_c)
filedata = re.sub(r'.*_occupancy',
'', filedata)
filedata = filedata[:-4]
filedata = filedata.replace('\\n',
'\n')
f.write(filedata[1:])
f.close()
count = len(open('cnt.cif',
'r').readlines())
# display the no. of atoms
print(count)
Producción:
4
Publicación traducida automáticamente
Artículo escrito por rajeshsharma7 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA