Análisis de contenido de libros/documentos
Los patrones dentro del texto escrito no son los mismos en todos los autores o idiomas. Esto permite a los lingüistas estudiar el idioma de origen o la autoría potencial de textos donde estas características no se conocen directamente, como los Documentos Federalistas de la Revolución Americana.
Objetivo: En este estudio de caso, examinaremos las propiedades de los libros individuales en una colección de libros de varios autores y varios idiomas. Más específicamente, veremos la longitud de los libros, la cantidad de palabras únicas y cómo estos atributos se agrupan por idioma de o paternidad literaria.
Fuente: Project Gutenberg es la biblioteca digital de libros más antigua. Su objetivo es digitalizar y archivar obras culturales y, en la actualidad, contiene más de 50 000 libros, todos publicados anteriormente y ahora disponibles electrónicamente. Descargue algunos de estos libros en inglés y francés desde aquí y los libros en portugués y alemán de aquí para su análisis. Junte todos estos libros en una carpeta llamada Libros con subcarpetas en inglés, francés, alemán y portugués.
Frecuencia de palabras en el texto
Así que vamos a construir una función que cuente la frecuencia de palabras en un texto. Consideraremos un texto de prueba de muestra, y luego reemplazaremos el texto de muestra con el archivo de texto de los libros que acabamos de descargar. Ya que vamos a cuente la frecuencia de las palabras, por lo tanto, las letras MAYÚSCULAS y minúsculas son iguales. Convertiremos todo el texto a minúsculas y lo guardaremos.
Python
text = "This is my test text. We're keeping this text short to keep things manageable." text = text.lower()
La frecuencia de palabras se puede contar de varias maneras. Vamos a codificar, de dos maneras (solo para el conocimiento). Uno usando for loop y el otro usando Counter from collections, que resulta ser más rápido que el anterior. La función devolverá un diccionario de palabras únicas y su frecuencia como un par clave-valor. Entonces, codificamos:
Python3
from collections import Counter
# counts word frequency
def count_words(text):
skips = [".", ", ", ":", ";", "'", '"']
for ch in skips:
text = text.replace(ch, "")
word_counts = {}
for word in text.split(" "):
if word in word_counts:
word_counts[word]+= 1
else:
word_counts[word]= 1
return word_counts
# >>>count_words(text) You can check the function
# counts word frequency using
# Counter from collections
def count_words_fast(text):
text = text.lower()
skips = [".", ", ", ":", ";", "'", '"']
for ch in skips:
text = text.replace(ch, "")
word_counts = Counter(text.split(" "))
return word_counts
# >>>count_words_fast(text) You can check the function
Salida: la salida es un diccionario que contiene las palabras únicas del texto de muestra como clave y la frecuencia de cada palabra como valor. Comparando la salida de ambas funciones, tenemos:
{‘eran’: 1, ‘es’: 1, ‘manejable’: 1, ‘a’: 1, ‘cosas’: 1, ‘guardar’: 1, ‘mi’: 1, ‘prueba’: 1, ‘ texto’: 2, ‘mantener’: 1, ‘breve’: 1, ‘esto’: 2}
Counter({‘texto’: 2, ‘esto’: 2, ‘eran’: 1, ‘es’: 1, ‘manejable’: 1, ‘a’: 1, ‘cosas’: 1, ‘manteniendo’: 1, ‘mi’: 1, ‘prueba’: 1, ‘mantener’: 1, ‘breve’: 1})
Lectura de libros en Python: Desde entonces, tuvimos éxito al probar nuestras funciones de frecuencia de palabras con el texto de muestra. Ahora, vamos a probar las funciones con los libros, que descargamos como archivo de texto. Vamos a crear una función llamada read_book() que leerá nuestros libros en Python y los guardará como una string larga en una variable y los devolverá. El parámetro de la función será la ubicación del libro.txt que se leerá y se pasará al llamar a la función.
Python
#read a book and return it as a string
def read_book(title_path):
with open(title_path, "r", encoding ="utf8") as current_file:
text = current_file.read()
text = text.replace("\n", "").replace("\r", "")
return text
Total de palabras únicas: vamos a diseñar otra función llamada word_stats(), que tomará el diccionario de frecuencia de palabras (salida de count_words_fast()/count_words()) como parámetro. La función devolverá el número total de palabras únicas (sum /total de claves en el diccionario de frecuencia de palabras) y un dict_values que contiene el recuento total de ellos juntos, como una tupla.
Python3
# word_counts = count_words_fast(text) def word_stats(word_counts): num_unique = len(word_counts) counts = word_counts.values() return (num_unique, counts)
Llamar a las funciones: por último, vamos a leer un libro, por ejemplo, la versión en inglés de Romeo y Julieta, y recopilaremos información sobre la frecuencia de palabras, palabras únicas, recuento total de palabras únicas, etc. de las funciones.
Python
text = read_book("./Books / English / shakespeare / Romeo and Juliet.txt")
word_counts = count_words_fast(text)
(num_unique, counts) = word_stats(word_counts)
print(num_unique, sum(counts))
Output: 5118 40776
Con la ayuda de las funciones que creamos, llegamos a saber que hay 5118 palabras únicas en la versión en inglés de Romeo y Julieta y la suma de la frecuencia de las palabras únicas suma 40776. Podemos saber qué palabra ocurrió más en el libro y puede jugar con diferentes versiones de libros, de diferentes idiomas para conocerlos y sus estadísticas con la ayuda de las funciones anteriores.
Trazado de las características características de los libros
Vamos a graficar, (i) Longitud del libro Vs Número de palabras únicas para todos los libros de diferentes idiomas usando matplotlib . Importaremos pandas para crear un marco de datos de pandas, que contendrá información sobre libros como columnas. Clasificaremos estas columnas por diferentes categorías como: «idioma», «autor», «título», «longitud» y «único». Para trazar la longitud del libro a lo largo del eje x y el número de palabras únicas a lo largo del eje y, codificamos:
Python3
import os
import pandas as pd
book_dir = "./Books"
os.listdir(book_dir)
stats = pd.DataFrame(columns =("language",
"author",
"title",
"length",
"unique"))
# check >>>stats
title_num = 1
for language in os.listdir(book_dir):
for author in os.listdir(book_dir+"/"+language):
for title in os.listdir(book_dir+"/"+language+"/"+author):
inputfile = book_dir+"/"+language+"/"+author+"/"+title
print(inputfile)
text = read_book(inputfile)
(num_unique, counts) = word_stats(count_words_fast(text))
stats.loc[title_num]= language,
author.capitalize(),
title.replace(".txt", ""),
sum(counts), num_unique
title_num+= 1
import matplotlib.pyplot as plt
plt.plot(stats.length, stats.unique, "bo-")
plt.loglog(stats.length, stats.unique, "ro")
stats[stats.language =="English"] #to check information on english books
plt.figure(figsize =(10, 10))
subset = stats[stats.language =="English"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="English",
color ="crimson")
subset = stats[stats.language =="French"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="French",
color ="forestgreen")
subset = stats[stats.language =="German"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="German",
color ="orange")
subset = stats[stats.language =="Portuguese"]
plt.loglog(subset.length,
subset.unique,
"o",
label ="Portuguese",
color ="blueviolet")
plt.legend()
plt.xlabel("Book Length")
plt.ylabel("Number of Unique words")
plt.savefig("fig.pdf")
plt.show()
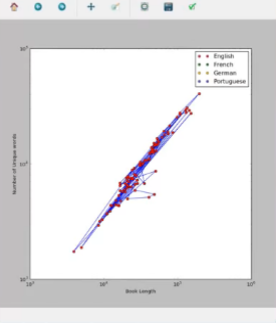
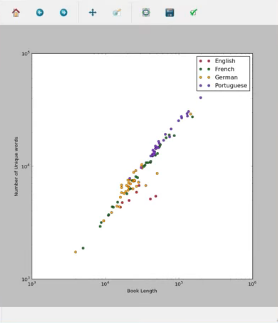
Resultado: Trazamos dos gráficos, el primero que representa cada libro de diferente idioma y autor simplemente como un libro. Los puntos rojos en el primer gráfico representan un solo libro y están conectados por líneas azules. El gráfico logarítmico crea puntos discretos [rojo aquí] y el gráfico lineal crea curvas lineales [azul aquí], uniendo los puntos. El segundo gráfico es un gráfico logarítmico que muestra libros de diferentes idiomas con diferentes colores [rojo para inglés, verde para francés, etc.] como puntos discretos.
Estos gráficos ayudan a analizar hechos visualmente sobre diferentes libros de origen vívido. A partir del gráfico, llegamos a saber que los libros en portugués son más extensos y tienen una mayor cantidad de palabras únicas que los libros en alemán o inglés. Graficar tales datos demuestra ser de gran ayuda para los lingüistas.
Referencia:
- edX – HarvardX – Uso de Python para la investigación
- Ejercicio similar de Datacamp
- next_step: ML -Avanzado
Este artículo es una contribución de Amartya Ranjan Saikia . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA