En el análisis descriptivo, describimos nuestros datos con la ayuda de varios métodos representativos como el uso de cuadros, gráficos, tablas, archivos de Excel, etc. En el análisis descriptivo, describimos nuestros datos de alguna manera y los presentamos de manera significativa para que se puede entender fácilmente. La mayoría de las veces se realiza en pequeños conjuntos de datos y este análisis nos ayuda mucho a predecir algunas tendencias futuras en función de los hallazgos actuales. Algunas medidas que se utilizan para describir un conjunto de datos son medidas de tendencia central y medidas de variabilidad o dispersión.
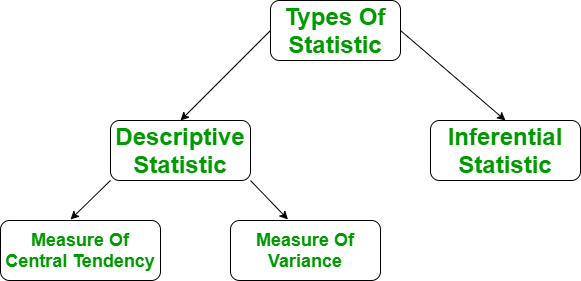
Proceso de Análisis Descriptivo
- La medida de tendencia central
- Medida de variabilidad
Medida de tendencia central
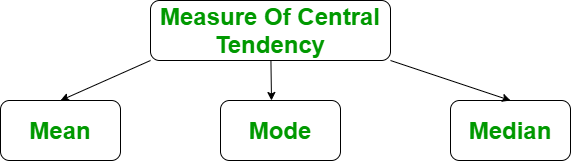
Representa todo el conjunto de datos por un solo valor. Nos da la ubicación de los puntos centrales. Hay tres medidas principales de tendencia central:
- Significar
- Modo
- Mediana
Medida de variabilidad
La medida de la variabilidad se conoce como la dispersión de los datos o qué tan bien se distribuyen nuestros datos. Las medidas de variabilidad más comunes son:
- Rango
- Diferencia
- Desviación Estándar

Necesidad de análisis descriptivo
El análisis descriptivo nos ayuda a comprender nuestros datos y es una parte muy importante del aprendizaje automático. Esto se debe a que Machine Learning se trata de hacer predicciones. Por otro lado, las estadísticas tienen que ver con sacar conclusiones de los datos, que es un paso inicial necesario para el aprendizaje automático. Hagamos este análisis descriptivo en R.
Análisis Descriptivo en R
Los análisis descriptivos consisten en describir simplemente los datos utilizando algunas estadísticas y gráficos de resumen. Aquí, describiremos cómo calcular estadísticas de resumen utilizando el software R.
Importe sus datos en R:
Antes de realizar cualquier cálculo, en primer lugar, debemos preparar nuestros datos, guardarlos en archivos .txt o .csv externos y es una buena práctica guardar el archivo en el directorio actual. Después de esa importación, sus datos en R de la siguiente manera:
Obtenga el archivo csv aquí .
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Print the first 6 rows
print(head(myData))
Producción:
Product Age Gender Education MaritalStatus Usage Fitness Income Miles 1 TM195 18 Male 14 Single 3 4 29562 112 2 TM195 19 Male 15 Single 2 3 31836 75 3 TM195 19 Female 14 Partnered 4 3 30699 66 4 TM195 19 Male 12 Single 3 3 32973 85 5 TM195 20 Male 13 Partnered 4 2 35247 47 6 TM195 20 Female 14 Partnered 3 3 32973 66
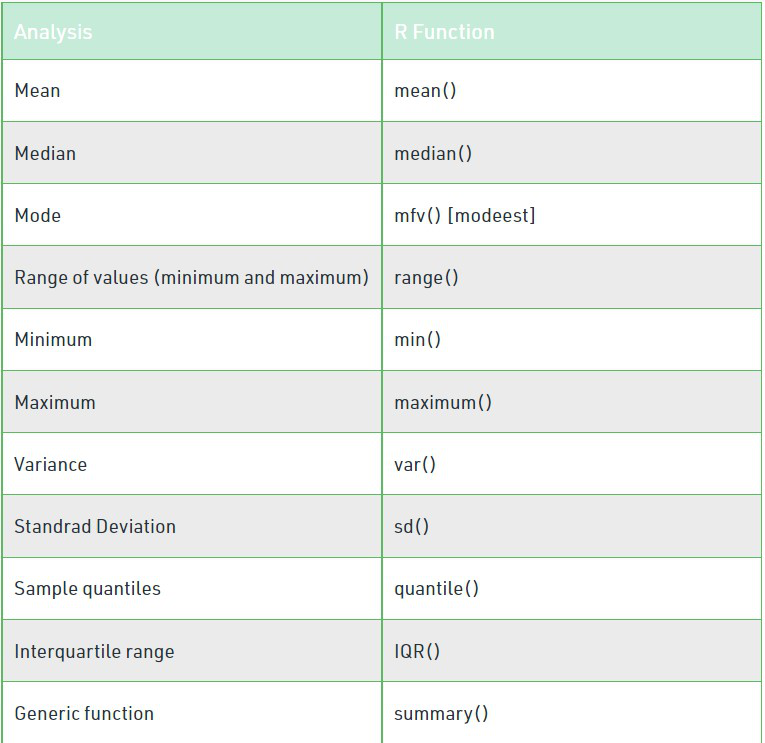
Funciones de R para calcular el análisis descriptivo:
Significar
Es la suma de las observaciones dividida por el número total de observaciones. También se define como promedio, que es la suma dividida por la cuenta.
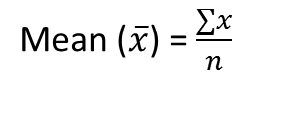
donde n = número de términos
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Compute the mean value
mean = mean(myData$Age)
print(mean)
Producción:
[1] 28.78889
Mediana
Es el valor medio del conjunto de datos. Divide los datos en dos mitades. Si el número de elementos en el conjunto de datos es impar, entonces el elemento central es la mediana y si es par, la mediana sería el promedio de dos elementos centrales.
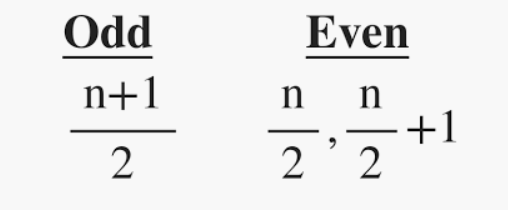
donde n = número de términos
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Compute the median value
median = median(myData$Age)
print(median)
Producción:
[1] 26
Modo
Es el valor que tiene la frecuencia más alta en el conjunto de datos dado. El conjunto de datos puede no tener moda si la frecuencia de todos los puntos de datos es la misma. Además, podemos tener más de un modo si encontramos dos o más puntos de datos que tienen la misma frecuencia.
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the library
library(modeest)
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Compute the mode value
mode = mfv(myData$Age)
print(mode)
Producción:
[1] 25
Rango
El rango describe la diferencia entre el punto de datos más grande y más pequeño en nuestro conjunto de datos. Cuanto mayor sea el rango, mayor será la difusión de los datos y viceversa.
Rango = valor de datos más grande – valor de datos más pequeño
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Calculate the maximum
max = max(myData$Age)
# Calculate the minimum
min = min(myData$Age)
# Calculate the range
range = max - min
cat("Range is:\n")
print(range)
# Alternate method to get min and max
r = range(myData$Age)
print(r)
Producción:
Range is: [1] 32 [1] 18 50
Diferencia
Se define como una desviación cuadrada promedio de la media. Se calcula encontrando la diferencia entre cada punto de datos y el promedio, que también se conoce como la media, elevándolos al cuadrado, sumándolos todos y luego dividiendo por la cantidad de puntos de datos presentes en nuestro conjunto de datos.
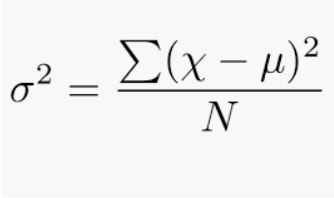
donde,
N = número de términos
u = Media
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Calculating variance
variance = var(myData$Age)
print(variance)
Producción:
[1] 48.21217
Desviación Estándar
Se define como la raíz cuadrada de la varianza. Se calcula encontrando la media, luego restando cada número de la media, que también se conoce como promedio, y elevando al cuadrado el resultado. Sumando todos los valores y luego dividiendo por el número de términos seguido de la raíz cuadrada.
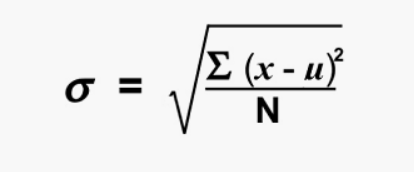
donde,
N = número de términos
u = Media
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F)
# Calculating Standard deviation
std = sd(myData$Age)
print(std)
Producción:
[1] 6.943498
Algunas funciones R más utilizadas en el análisis descriptivo:
Cuartiles
Un cuartil es un tipo de cuantil. El primer cuartil (Q1) se define como el número medio entre el número más pequeño y la mediana del conjunto de datos, el segundo cuartil (Q2) es la mediana del conjunto de datos dado, mientras que el tercer cuartil (Q3) es el medio número entre la mediana y el mayor valor del conjunto de datos.
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F)
# Calculating Quartiles
quartiles = quantile(myData$Age)
print(quartiles)
Producción:
0% 25% 50% 75% 100% 18 24 26 33 50
Rango intercuartil
El rango intercuartil (IQR), también llamado midspread o 50% medio, o técnicamente H-spread es la diferencia entre el tercer cuartil (Q3) y el primer cuartil (Q1). Cubre el centro de la distribución y contiene el 50% de las observaciones.
RIC = Q3 – Q1
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv", stringsAsFactors = F)
# Calculating IQR
IQR = IQR(myData$Age)
print(IQR)
Producción:
[1] 9
función resumen() en R
La función summary() se puede utilizar para mostrar varios resúmenes estadísticos de una variable o de un marco de datos completo.
Resumen de una sola variable:
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Calculating summary
summary = summary(myData$Age)
print(summary)
Producción:
Min. 1st Qu. Median Mean 3rd Qu. Max. 18.00 24.00 26.00 28.79 33.00 50.00
Resumen del marco de datos
Ejemplo:
R
# R program to illustrate
# Descriptive Analysis
# Import the data using read.csv()
myData = read.csv("CardioGoodFitness.csv",
stringsAsFactors = F)
# Calculating summary
summary = summary(myData)
print(summary)
Producción:
Product Age Gender Education
Length:180 Min. :18.00 Length:180 Min. :12.00
Class :character 1st Qu.:24.00 Class :character 1st Qu.:14.00
Mode :character Median :26.00 Mode :character Median :16.00
Mean :28.79 Mean :15.57
3rd Qu.:33.00 3rd Qu.:16.00
Max. :50.00 Max. :21.00
MaritalStatus Usage Fitness Income Miles
Length:180 Min. :2.000 Min. :1.000 Min. : 29562 Min. : 21.0
Class :character 1st Qu.:3.000 1st Qu.:3.000 1st Qu.: 44059 1st Qu.: 66.0
Mode :character Median :3.000 Median :3.000 Median : 50597 Median : 94.0
Mean :3.456 Mean :3.311 Mean : 53720 Mean :103.2
3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.: 58668 3rd Qu.:114.8
Max. :7.000 Max. :5.000 Max. :104581 Max. :360.0
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA