Una de las técnicas de aprendizaje automático más populares o bien establecidas es el análisis discriminante lineal (LDA). Se utiliza principalmente para resolver problemas de clasificación en lugar de problemas de clasificación supervisados. Es básicamente una técnica de reducción de dimensionalidad. Usando las combinaciones lineales de predictores, LDA intenta predecir la clase de las observaciones dadas. Supongamos que las variables predictoras son p. Deje que todas las clases tengan una variante idéntica (es decir, para el análisis univariado, el valor de p es 1) o arrays de covarianza idénticas (es decir, para el análisis multivariado, el valor de p es mayor que 1).
Método de implementación de LDA en R
LDA o análisis discriminante lineal se puede calcular en R utilizando la función lda() del paquete MASS . LDA se utiliza para determinar las medias de los grupos y también para cada individuo, trata de calcular la probabilidad de que el individuo pertenezca a un grupo diferente. Por lo tanto, ese individuo en particular adquiere el puntaje de probabilidad más alto en ese grupo.
Para usar lda()la función, uno debe instalar los siguientes paquetes:
- Paquete MASS
lda()para la función. - paquete tidyverse para una mejor y fácil manipulación y visualización de datos.
- paquete de intercalación para un mejor flujo de trabajo de aprendizaje automático.
Al instalar estos paquetes, prepare los datos. Para preparar los datos, primero se deben dividir los datos en un conjunto de trenes y un conjunto de prueba. Entonces uno necesita normalizar los datos. Al hacerlo, automáticamente se eliminan las variables categóricas. Una vez que los datos están configurados y preparados, se puede comenzar con el análisis discriminante lineal utilizando la lda()función.
Al principio, el algoritmo LDA trata de encontrar las direcciones que pueden maximizar la separación entre las clases. Luego usa estas direcciones para predecir la clase de todos y cada uno de los individuos. Estas direcciones se conocen como discriminantes lineales y son combinaciones lineales de las variables predictoras.
Explicación de la funciónlda()
Antes de implementar el análisis discriminante lineal, discutamos las cosas a considerar:
- Uno necesita inspeccionar las distribuciones univariadas de todas y cada una de las variables. Debe estar distribuida normalmente. De lo contrario, transforme utilizando la función logarítmica y raíz para la distribución exponencial o el método de Box-Cox para la distribución sesgada.
- Es necesario eliminar los valores atípicos de los datos y luego estandarizar las variables para que la escala sea comparable.
- Supongamos que la variable dependiente, es decir, Y es discreta.
- LDA asume que los predictores se distribuyen normalmente, es decir, provienen de una distribución gaussiana. Varias clases tienen medias específicas de clase e igual covarianza o varianza.
Bajo el paquete MASS , tenemos la lda()función para calcular el análisis discriminante lineal. Veamos el método predeterminado para usar la lda()función.
Sintaxis:
lda(fórmula, datos, …, subconjunto, na.acción)
O,
lda(x, agrupación, anterior = proporciones, tol = 1.0e-4, método, CV = FALSO, nu, …)Parámetros :
fórmula : una fórmula que es del grupo de forma ~ x1+x2..
datos : marco de datos del que queremos tomar las variables o individuos de la fórmula, preferiblemente
subconjunto : un índice utilizado para especificar los casos que se van a utilizar para entrenar las muestras.
na.action : una función para especificar la acción que se llevará a cabo si se encuentra NA.
x : se requiere una array o un marco de datos si no se pasa ninguna fórmula en los argumentos.
agrupación : un factor que se utiliza para especificar las clases de las observaciones. prior : las probabilidades previas de la pertenencia a la clase.
tol : una tolerancia que se utiliza para decidir si la array es singular o no.
método : qué tipo de métodos se utilizarán en varios casos.
CV : si es verdadero, devolverá los resultados para la validación cruzada de exclusión.
nu : los grados de libertad del método cuando es method=”t”.
… : los diversos argumentos pasados desde o hacia otros métodos.
La función lda()tiene los siguientes elementos en su salida:
- Posibilidades previas de grupos, es decir, en todos y cada uno de los grupos la proporción de las observaciones de entrenamiento.
- Grupo significa es decir, el centro de gravedad del grupo y se utiliza para mostrar en un grupo la media de todas y cada una de las variables.
- Coeficientes de discriminantes lineales, es decir, la combinación lineal de las variables predictoras que se utilizan para formar la regla de decisión de LDA.
Ejemplo:
Veamos cómo se calcula el análisis discriminante lineal usando la lda()función. Usemos el conjunto de datos de iris de R Studio.
# LINEAR DISCREMINANT ANALYSIS
library(MASS)
library(tidyverse)
library(caret)
theme_set(theme_classic())
# Load the data
data("iris")
# Split the data into training (80%) and test set (20%)
set.seed(123)
training.individuals <- iris$Species %>%
createDataPartition(p = 0.8, list = FALSE)
train.data <- iris[training.individuals, ]
test.data <- iris[-training.individuals, ]
# Estimate preprocessing parameters
preproc.parameter <- train.data %>%
preProcess(method = c("center", "scale"))
# Transform the data using the estimated parameters
train.transform <- preproc.parameter %>% predict(train.data)
test.transform <- preproc.parameter %>% predict(test.data)
# Fit the model
model <- lda(Species~., data = train.transform)
# Make predictions
predictions <- model %>% predict(test.transform)
# Model accuracy
mean(predictions$class==test.transform$Species)
model <- lda(Species~., data = train.transform)
model
Producción:
[1] 1
Call: lda(Species ~ ., data = train.transformed)
Prior probabilities of groups:
setosa versicolor virginica
0.3333333 0.3333333 0.3333333
Group means:
Sepal.Length Sepal.Width Petal.Length Petal.Width
setosa -1.0120728 0.7867793 -1.2927218 -1.2496079
versicolor 0.1174121 -0.6478157 0.2724253 0.1541511
virginica 0.8946607 -0.1389636 1.0202965 1.0954568
Coefficients of linear discriminants:
LD1 LD2
Sepal.Length 0.9108023 0.03183011
Sepal.Width 0.6477657 0.89852536
Petal.Length -4.0816032 -2.22724052
Petal.Width -2.3128276 2.65441936
Proportion of trace:
LD1 LD2
0.9905 0.0095
Trazado gráfico de la salida
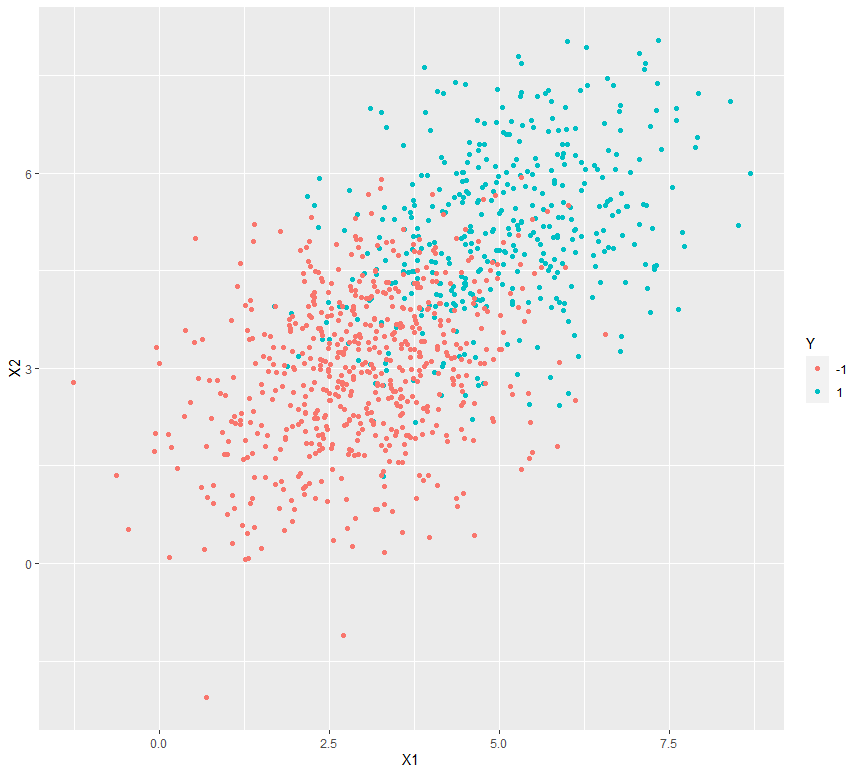
Veamos qué tipo de trazado se realiza en dos conjuntos de datos ficticios. Para esto, usemos la ggplot()función en el paquete ggplot2 para trazar los resultados o la salida obtenida del archivo lda().
Ejemplo:
# Graphical plotting of the output
library(ggplot2)
library(MASS)
library(mvtnorm)
# Variance Covariance matrix for random bivariate gaussian sample
var_covar = matrix(data = c(1.5, 0.4, 0.4, 1.5), nrow = 2)
# Random bivariate Gaussian samples for class +1
Xplus1 <- rmvnorm(400, mean = c(5, 5), sigma = var_covar)
# Random bivariate Gaussian samples for class -1
Xminus1 <- rmvnorm(600, mean = c(3, 3), sigma = var_covar)
# Samples for the dependent variable
Y_samples <- c(rep(1, 400), rep(-1, 600))
# Combining the independent and dependent variables into a dataframe
dataset <- as.data.frame(cbind(rbind(Xplus1, Xminus1), Y_samples))
colnames(dataset) <- c("X1", "X2", "Y")
dataset$Y <- as.character(dataset$Y)
# Plot the above samples and color by class labels
ggplot(data = dataset) + geom_point(aes(X1, X2, color = Y))
Producción:
Aplicaciones
- En Face Recognition System , LDA se utiliza para generar un número más reducido y manejable de características antes de las clasificaciones.
- En el Sistema de identificación de clientes , LDA ayuda a identificar y elegir las características que se pueden usar para describir las características o características de un grupo de clientes que pueden comprar un artículo o producto en particular en un centro comercial.
- En el campo de la ciencia médica , LDA ayuda a identificar las características de varias enfermedades y clasificarlas como leves, moderadas o graves según los síntomas del paciente.