Python es un excelente lenguaje para realizar análisis de datos, principalmente debido al fantástico ecosistema de paquetes de Python centrados en datos. Pandas es uno de esos paquetes y facilita mucho la importación y el análisis de datos. En este artículo, he usado Pandas para analizar datos en el archivo Country Data.csv de conjuntos de datos públicos de la ONU de un sitio web popular ‘statweb.stanford.edu’.
A medida que analicé los datos del país indio, introduje los conceptos clave de Pandas como se muestra a continuación. Antes de leer este artículo, tenga una idea aproximada de los conceptos básicos de matplotlib y csv .
Instalación La
forma más fácil de instalar pandas es usar pip:
pip install pandas
o bien, Descárgala desde aquí
Creando un DataFrame en Pandas
La creación del marco de datos se realiza pasando múltiples Series a la clase DataFrame usando el método pd.Series . Aquí, se pasa en los dos objetos Series, s1 como la primera fila y s2 como la segunda fila.
Ejemplo:
# assigning two series to s1 and s2
s1 = pd.Series([1,2])
s2 = pd.Series(["Ashish", "Sid"])
# framing series objects into data
df = pd.DataFrame([s1,s2])
# show the data frame
df
# data framing in another way
# taking index and column values
dframe = pd.DataFrame([[1,2],["Ashish", "Sid"]],
index=["r1", "r2"],
columns=["c1", "c2"])
dframe
# framing in another way
# dict-like container
dframe = pd.DataFrame({
"c1": [1, "Ashish"],
"c2": [2, "Sid"]})
dframe
Producción:
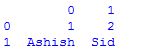


Importación de datos con Pandas
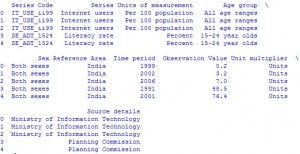
El primer paso es leer los datos. Los datos se almacenan como un archivo de valores separados por comas, o csv, donde cada fila está separada por una nueva línea y cada columna por una coma (,). Para poder trabajar con los datos en Python, es necesario leer el archivo csv en un Pandas DataFrame. Un DataFrame es una forma de representar y trabajar con datos tabulares. Los datos tabulares tienen filas y columnas, al igual que este archivo csv (haga clic en Descargar).
Ejemplo:
# Import the pandas library, renamed as pd
import pandas as pd
# Read IND_data.csv into a DataFrame, assigned to df
df = pd.read_csv("IND_data.csv")
# Prints the first 5 rows of a DataFrame as default
df.head()
# Prints no. of rows and columns of a DataFrame
df.shape
Producción:

29,10
Indexación de DataFrames con Pandas
La indexación puede ser posible utilizando el método pandas.DataFrame.iloc . El método iloc permite recuperar tantas filas y columnas por posición.
Ejemplos:
# prints first 5 rows and every column which replicates df.head() df.iloc[0:5,:] # prints entire rows and columns df.iloc[:,:] # prints from 5th rows and first 5 columns df.iloc[5:,:5]
Indexación usando etiquetas en Pandas
La indexación se puede trabajar con etiquetas utilizando el método pandas.DataFrame.loc , que permite indexar utilizando etiquetas en lugar de posiciones.
Ejemplos:
# prints first five rows including 5th index and every columns of df df.loc[0:5,:] # prints from 5th rows onwards and entire columns df = df.loc[5:,:]
Lo anterior en realidad no se ve muy diferente de df.iloc[0:5,:]. Esto se debe a que, si bien las etiquetas de fila pueden tomar cualquier valor, nuestras etiquetas de fila coinciden exactamente con las posiciones. Pero las etiquetas de columna pueden facilitar mucho las cosas cuando se trabaja con datos. Ejemplo:
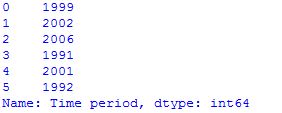
# Prints the first 5 rows of Time period # value df.loc[:5,"Time period"]
Matemáticas de tramas de datos con pandas
El cálculo de los marcos de datos se puede realizar utilizando las funciones estadísticas de las herramientas pandas.
Ejemplos:
# computes various summary statistics, excluding NaN values df.describe() # for computing correlations df.corr() # computes numerical data ranks df.rank()


Trazado de pandas
Los gráficos en estos ejemplos se realizan utilizando la convención estándar para hacer referencia a la API de matplotlib, que proporciona los conceptos básicos en pandas para crear fácilmente gráficos de aspecto decente.
Ejemplos:
# import the required module
import matplotlib.pyplot as plt
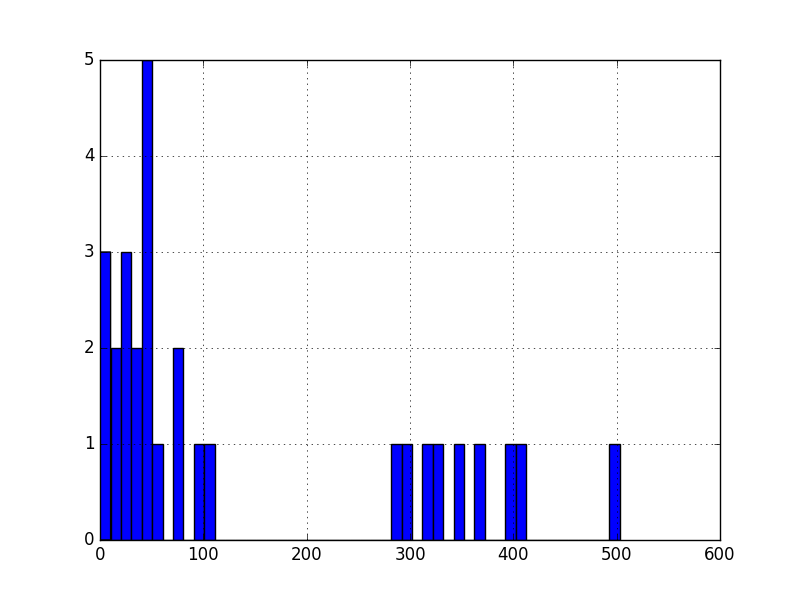
# plot a histogram
df['Observation Value'].hist(bins=10)
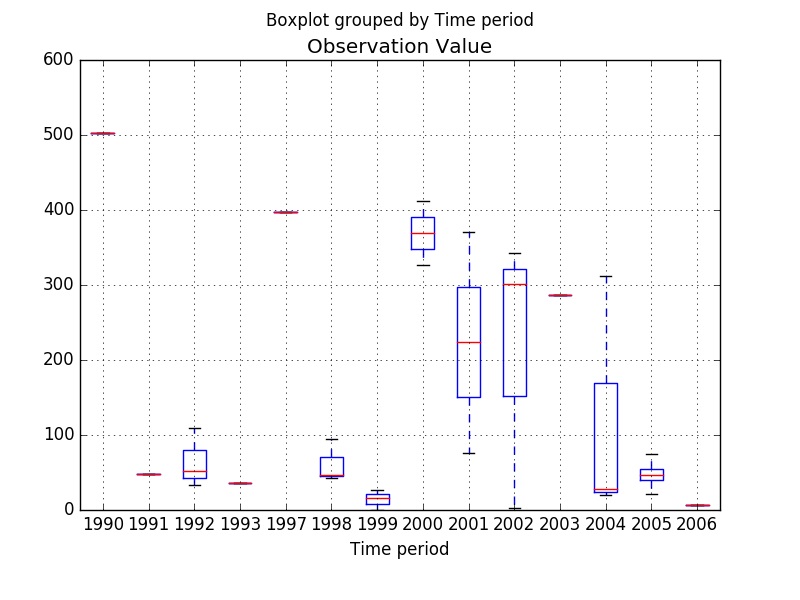
# shows presence of a lot of outliers/extreme values
df.boxplot(column='Observation Value', by = 'Time period')
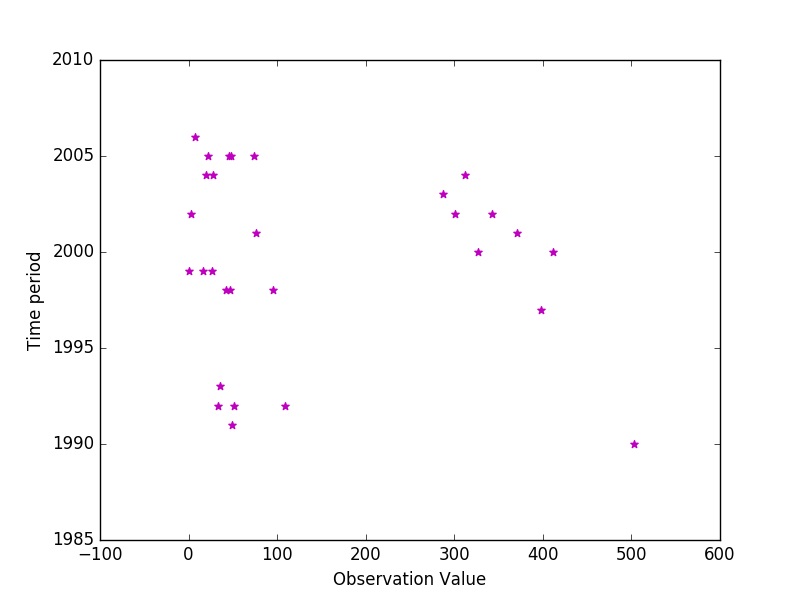
# plotting points as a scatter plot
x = df["Observation Value"]
y = df["Time period"]
plt.scatter(x, y, label= "stars", color= "m",
marker= "*", s=30)
# x-axis label
plt.xlabel('Observation Value')
# frequency label
plt.ylabel('Time period')
# function to show the plot
plt.show()
Análisis y visualización de datos con Python | conjunto 2
Referencia:
Este artículo es una contribución de Afzal_Saan . Si le gusta GeeksforGeeks y le gustaría contribuir, también puede escribir un artículo usando contribuya.geeksforgeeks.org o envíe su artículo por correo a contribuya@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA