Prerrequisitos: NumPy en Python , visualización de análisis de datos con Python | Serie 1
1. Almacenamiento de DataFrame en formato CSV:
Pandas proporciona una to.csv('filename', index = "False|True")función para escribir DataFrame en un archivo CSV. Aquí filenameestá el nombre del archivo CSV que desea crear e indexindica que el índice (si es predeterminado) de DataFrame debe sobrescribirse o no. Si establecemos, index = Falseentonces el índice no se sobrescribe. Por defecto, el valor del índice es TRUEentonces el índice se sobrescribe.
Ejemplo :
import pandas as pd
# assigning three series to s1, s2, s3
s1 = pd.Series([0, 4, 8])
s2 = pd.Series([1, 5, 9])
s3 = pd.Series([2, 6, 10])
# taking index and column values
dframe = pd.DataFrame([s1, s2, s3])
# assign column name
dframe.columns =['Geeks', 'For', 'Geeks']
# write data to csv file
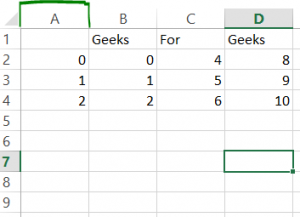
dframe.to_csv('geeksforgeeks.csv', index = False)
dframe.to_csv('geeksforgeeks1.csv', index = True)
Producción :
geeksforgeeks1.csvgeeksforgeeks2.csv
2. Manejo de datos faltantes
La fase de análisis de datos también incluye la capacidad de manejar los datos faltantes de nuestro conjunto de datos, y no sorprende que Pandas también cumpla con esa expectativa. Aquí es donde dropnay/o fillnalos métodos entran en juego. Mientras se ocupa de los datos que faltan, se supone que usted, como analista de datos, debe eliminar la columna que contiene los valores de NaN (método dropna) o completar los datos que faltan con la media o la moda de toda la entrada de la columna (método fillna), esta decisión es de gran importancia y depende de los datos y el efecto que crearía en nuestros resultados.
- Suelte los datos que faltan:
considere que este es el marco de datos generado por el siguiente código: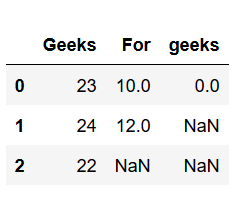
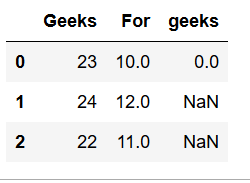
importpandas as pd# Create a DataFramedframe=pd.DataFrame({'Geeks': [23,24,22],'For': [10,12, np.nan],'geeks': [0, np.nan, np.nan]},columns=['Geeks','For','geeks'])# This will remove all the# rows with NAN values# If axis is not defined then# it is along rows i.e. axis = 0dframe.dropna(inplace=True)print(dframe)# if axis is equal to 1dframe.dropna(axis=1, inplace=True)print(dframe)Producción :
axis=0
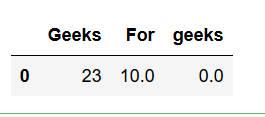 axis=1
axis=1

- Complete los valores faltantes:
ahora, para reemplazar cualquier valor de NaN con la media o la moda de los datos,fillnase usa, lo que podría reemplazar todos los valores de NaN de una columna en particular o incluso en todo el marco de datos según el requisito.importnumpy as npimportpandas as pd# Create a DataFramedframe=pd.DataFrame({'Geeks': [23,24,22],'For': [10,12, np.nan],'geeks': [0, np.nan, np.nan]},columns=['Geeks','For','geeks'])# Use fillna of complete Dataframe# value function will be applied on every columndframe.fillna(value=dframe.mean(), inplace=True)print(dframe)# filling value of one columndframe['For'].fillna(value=dframe['For'].mean(),inplace=True)print(dframe)Producción :
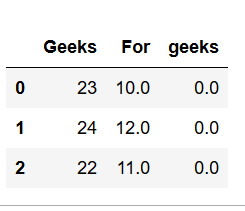
3. Método Groupby (agregación):
El método groupby nos permite agrupar los datos en función de cualquier fila o columna, por lo que podemos aplicar aún más las funciones agregadas para analizar nuestros datos. Agrupe las series usando el mapeador (dict o función clave, aplique la función dada al grupo, devuelva el resultado como una serie) o por una serie de columnas.
Considere que este es el DataFrame generado por el siguiente código: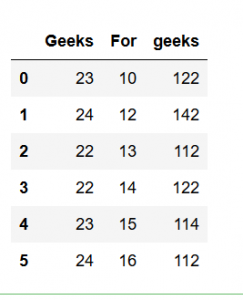
import pandas as pd
import numpy as np
# create DataFrame
dframe = pd.DataFrame({'Geeks': [23, 24, 22, 22, 23, 24],
'For': [10, 12, 13, 14, 15, 16],
'geeks': [122, 142, 112, 122, 114, 112]},
columns = ['Geeks', 'For', 'geeks'])
# Apply groupby and aggregate function
# max to find max value of column
# "For" and column "geeks" for every
# different value of column "Geeks".
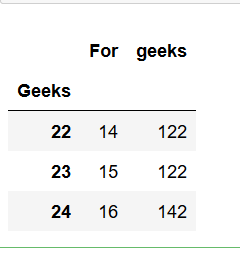
print(dframe.groupby(['Geeks']).max())
Producción :
Publicación traducida automáticamente
Artículo escrito por Mohityadav y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA