Hoy en día, con el avance tecnológico, las técnicas como el aprendizaje automático, etc. se están utilizando a gran escala en muchas organizaciones. Estos modelos suelen trabajar con un conjunto de puntos de datos predefinidos disponibles en forma de conjuntos de datos. Estos conjuntos de datos contienen información pasada/anterior sobre un dominio específico. Es muy importante organizar estos puntos de datos antes de que se introduzcan en el modelo. Aquí es donde usamos el análisis de datos. Si los datos que se alimentan al modelo de aprendizaje automático no están bien organizados, se obtienen resultados falsos o no deseados. Esto puede causar grandes pérdidas a la organización. Por lo tanto, hacer uso de un análisis de datos adecuado es muy importante.
Acerca del conjunto de datos:
Los datos que vamos a usar en este ejemplo son sobre autos. Específicamente, contiene varios puntos de información sobre los autos usados, como su precio, color, etc. Aquí debemos entender que simplemente recopilar datos no es suficiente. Los datos sin procesar no son útiles. Aquí, el análisis de datos juega un papel vital para desbloquear la información que necesitamos y obtener nuevos conocimientos sobre estos datos sin procesar.
Considere este escenario, nuestro amigo, Otis, quiere vender su auto. ¡Pero él no sabe por cuánto debería vender su auto! Quiere maximizar las ganancias, pero también quiere que se venda a un precio razonable para alguien que quiera poseerlo. Así que aquí, nosotros, siendo científicos de datos, podemos ayudar a nuestro amigo Otis.
Pensemos como científicos de datos y definamos claramente algunos de sus problemas: Por ejemplo, ¿hay datos sobre los precios de otros coches y sus características? ¿Qué características de los automóviles afectan sus precios? ¿Color? ¿Marca? ¿Los caballos de fuerza también afectan el precio de venta, o tal vez, algo más?
Como analista de datos o científico de datos, estas son algunas de las preguntas en las que podemos comenzar a pensar. Para responder a estas preguntas, vamos a necesitar algunos datos. Pero estos datos están en forma cruda. Por lo tanto, debemos analizarlo primero. Los datos están disponibles en forma de .csv/.dataformato con nosotros.
Para descargar el archivo utilizado en este ejemplo, haga clic aquí . El archivo proporcionado está en formato .data. Siga el proceso a continuación para convertir un archivo .data a un archivo .csv.
Proceso para convertir un archivo .data a .csv:
- abrir ms excel
- Ir a DATOS
- Seleccionar de texto
- Marque la casilla de verificación en comas (solo)
- ¡Guarde como .csv en la ubicación deseada en su PC!
Módulos necesarios:
- pandas: Pandas es una biblioteca de código abierto que le permite realizar la manipulación de datos en Python. Pandas proporciona una manera fácil de crear, manipular y disputar los datos.
- numpy: Numpy es el paquete fundamental para la computación científica con Python.
numpyse puede utilizar como un contenedor multidimensional eficiente de datos genéricos. - matplotlib: Matplotlib es una biblioteca de trazado 2D de Python que produce cifras de calidad de publicación en una variedad de formatos.
- seaborn: Seaborn es una biblioteca de visualización de datos de Python que se basa en matplotlib. Seaborn proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos.
- scipy: Scipy es un ecosistema basado en Python de software de código abierto para matemáticas, ciencia e ingeniería.
Pasos para instalar estos paquetes:
- Si está utilizando anaconda-jupyter/syder o cualquier otro software de terceros para escribir su código python, asegúrese de establecer la ruta a la «carpeta de scripts» de ese software en el símbolo del sistema de su PC.
- Luego escriba – pip install nombre-paquete
Ejemplo:pip install numpy
- Luego, una vez finalizada la instalación. (¡Asegúrese de estar conectado a Internet!) Abra su IDE, luego importe esos paquetes. Para importar, escriba: nombre del paquete de importación
Ejemplo:import numpy
Pasos que se utilizan en el siguiente código (descripción breve):
- Importar los paquetes
- Establezca la ruta al archivo de datos (archivo .csv)
- Encuentre si hay datos nulos o datos NaN en nuestro archivo. Si los hay, eliminarlos
- Realice varias operaciones de limpieza y visualización de datos en sus datos. Estos pasos se ilustran al lado de cada línea de código en forma de comentarios para una mejor comprensión, ya que sería mejor ver el código uno al lado del otro que explicarlo completamente aquí, no tendría sentido.
- ¡Obtén el resultado!
Comencemos a analizar los datos.
Paso 1: importa los módulos necesarios.
# importing section import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import scipy as sp
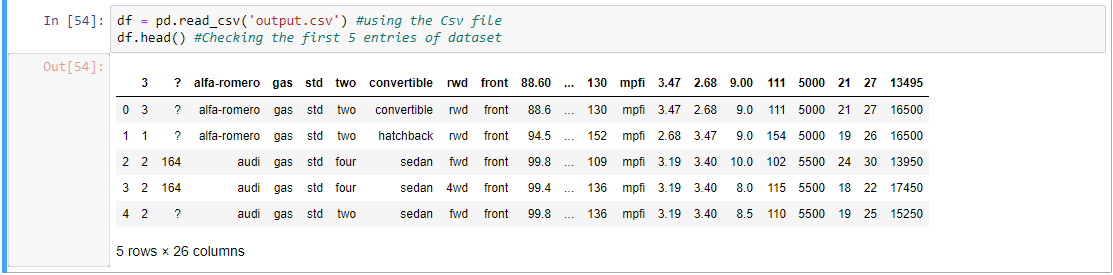
Paso 2: Verifiquemos las primeras cinco entradas del conjunto de datos.
# using the Csv file
df = pd.read_csv('output.csv')
# Checking the first 5 entries of dataset
df.head()
Producción:
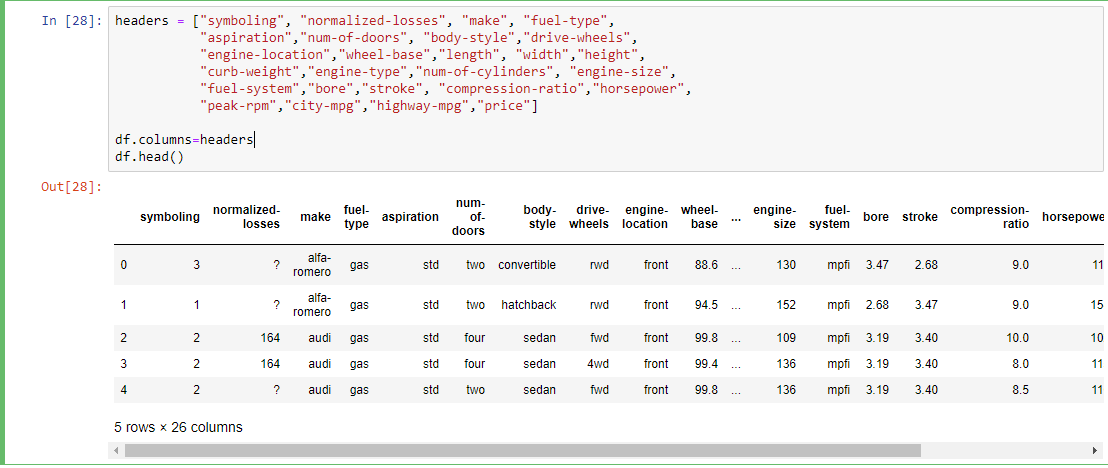
Paso 3: Definición de encabezados para nuestro conjunto de datos.
headers = ["symboling", "normalized-losses", "make", "fuel-type", "aspiration","num-of-doors", "body-style","drive-wheels", "engine-location", "wheel-base","length", "width","height", "curb-weight", "engine-type","num-of-cylinders", "engine-size", "fuel-system","bore","stroke", "compression-ratio", "horsepower", "peak-rpm","city-mpg","highway-mpg","price"] df.columns=headers df.head()
Producción:
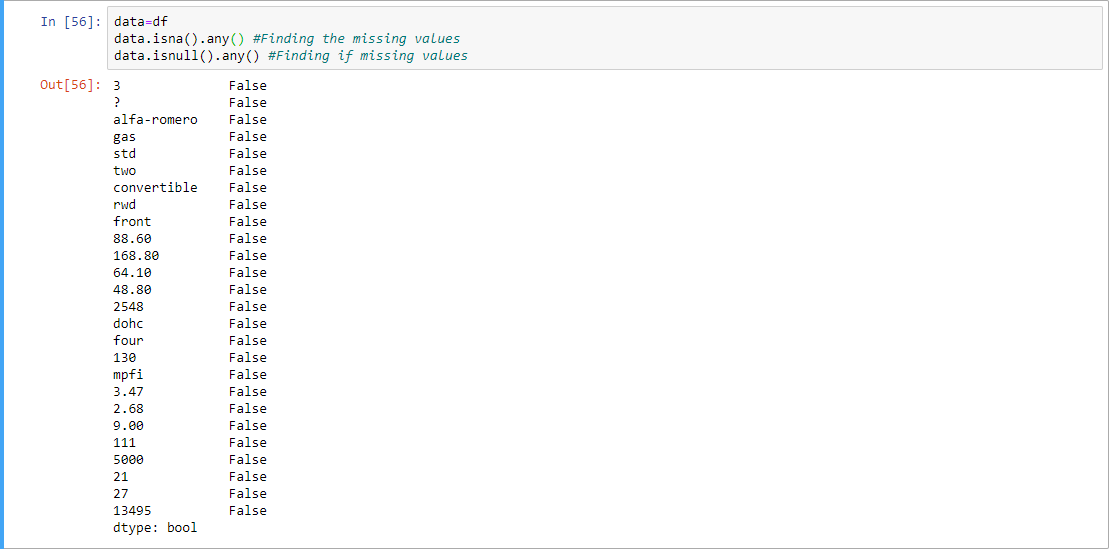
Paso 4: encontrar el valor que falta, si lo hay.
data = df # Finding the missing values data.isna().any() # Finding if missing values data.isnull().any()
Producción:
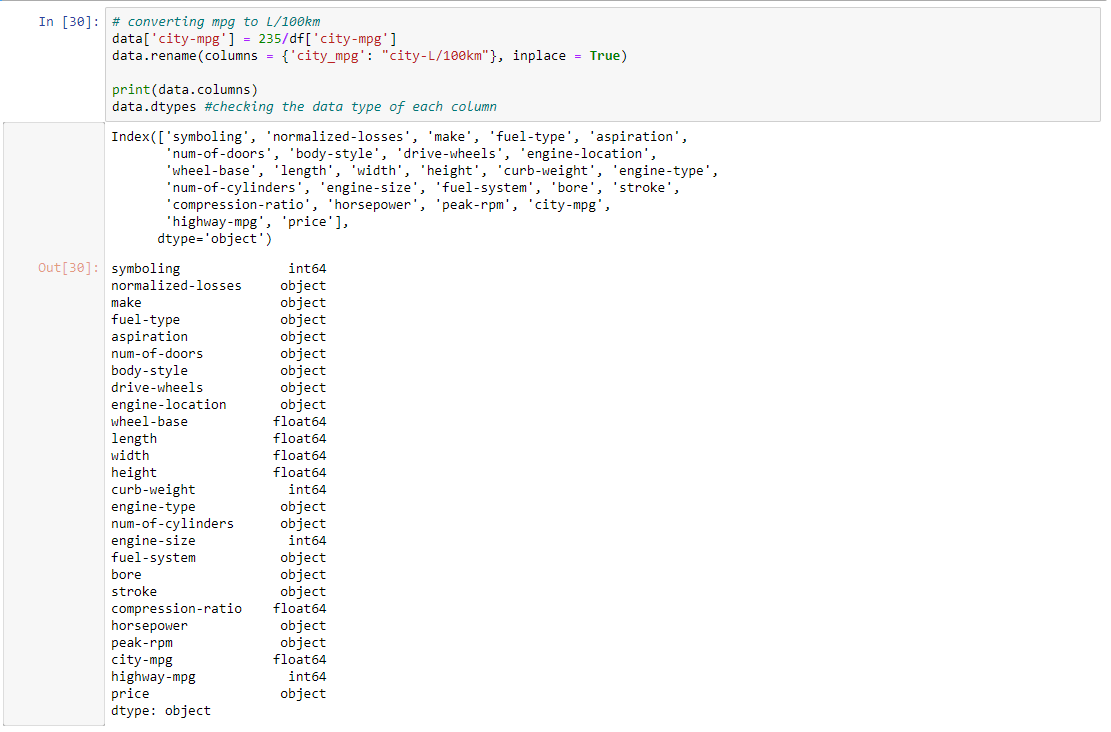
Paso 4: Convertir mpg a L/100km y verificar el tipo de datos de cada columna.
# converting mpg to L / 100km
data['city-mpg'] = 235 / df['city-mpg']
data.rename(columns = {'city_mpg': "city-L / 100km"}, inplace = True)
print(data.columns)
# checking the data type of each column
data.dtypes
Producción:
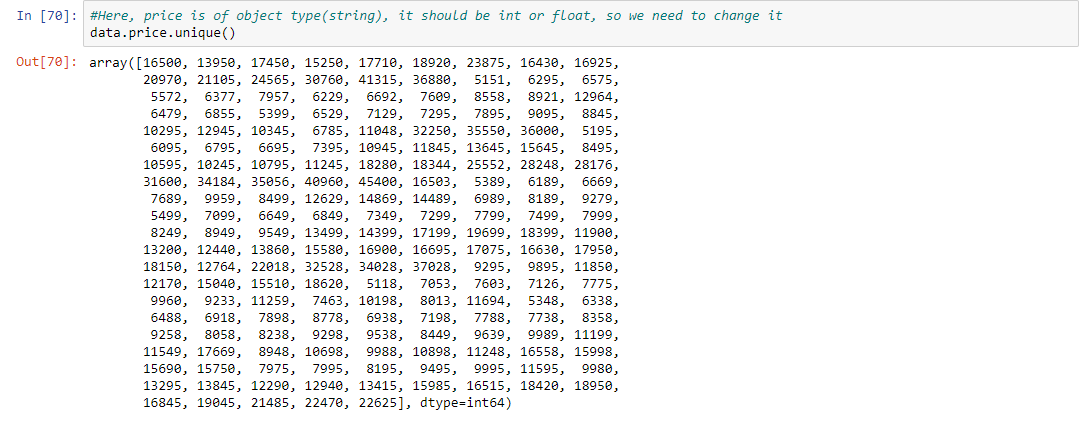
Paso 5: aquí, el precio es del tipo de objeto (string), debe ser int o float, por lo que debemos cambiarlo
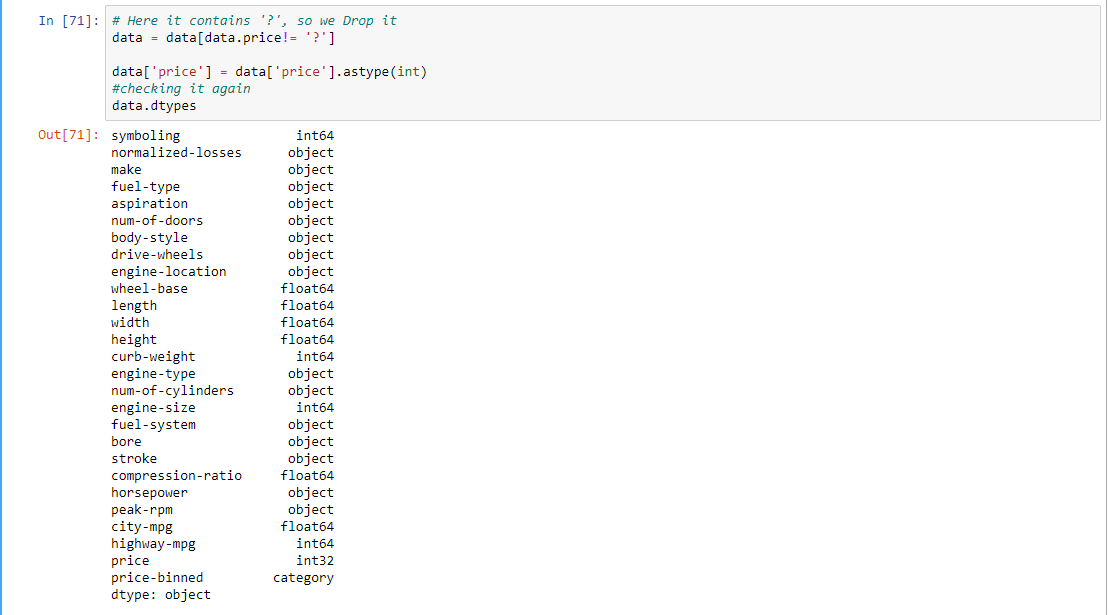
data.price.unique() # Here it contains '?', so we Drop it data = data[data.price != '?'] # checking it again data.dtypes
Producción:
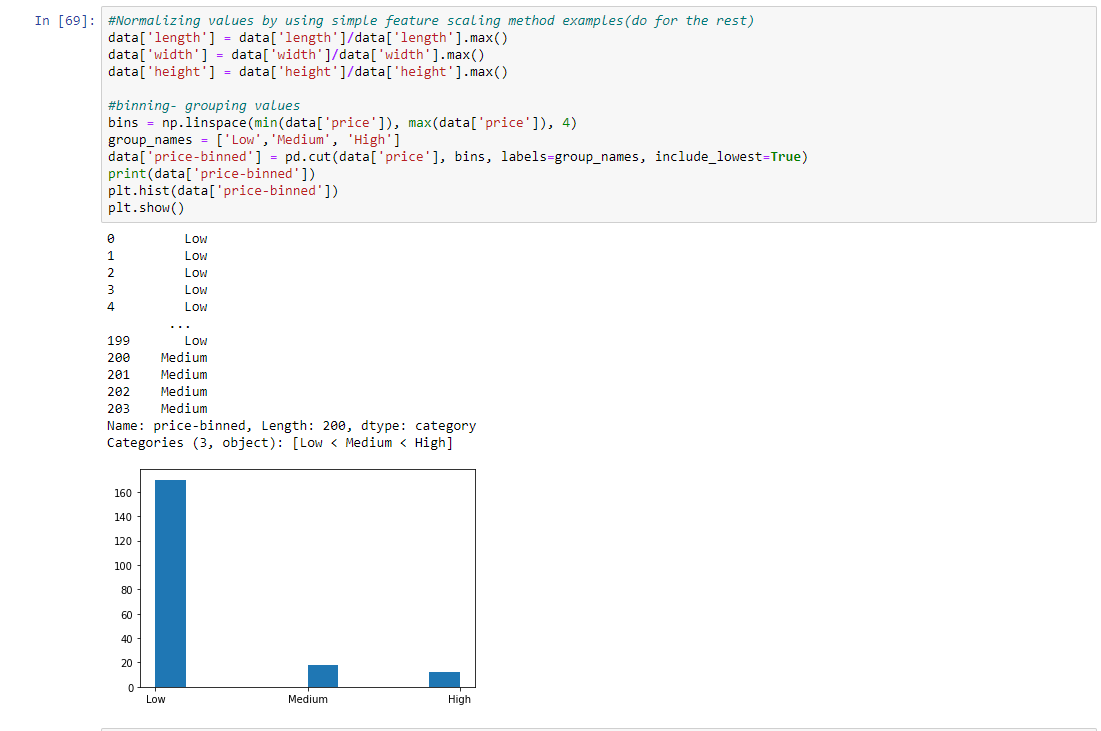
Paso 6: Normalización de valores mediante el uso de ejemplos de métodos de escalado de características simples (haga el resto) y valores de agrupación en intervalos
data['length'] = data['length']/data['length'].max() data['width'] = data['width']/data['width'].max() data['height'] = data['height']/data['height'].max() # binning- grouping values bins = np.linspace(min(data['price']), max(data['price']), 4) group_names = ['Low', 'Medium', 'High'] data['price-binned'] = pd.cut(data['price'], bins, labels = group_names, include_lowest = True) print(data['price-binned']) plt.hist(data['price-binned']) plt.show()
Producción:
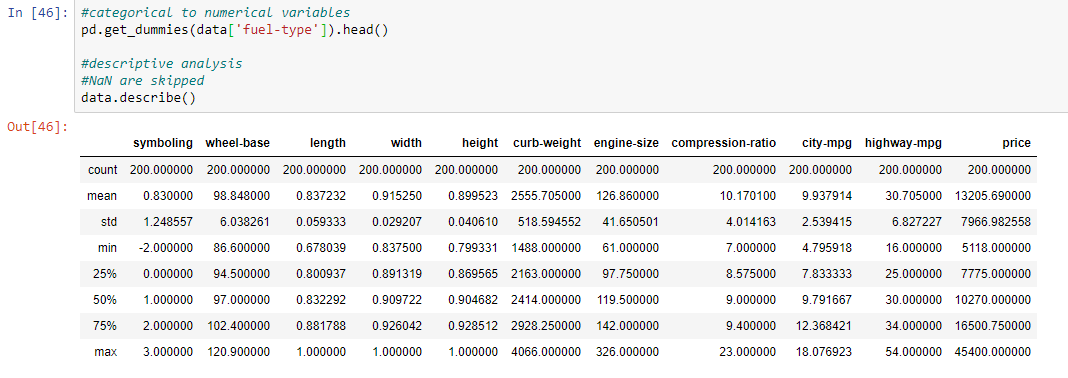
Paso 7: Hacer un análisis descriptivo de datos categóricos a valores numéricos.
# categorical to numerical variables pd.get_dummies(data['fuel-type']).head() # descriptive analysis # NaN are skipped data.describe()
Producción:
Paso 8: Trazar los datos según el precio según el tamaño del motor.
# examples of box plot
plt.boxplot(data['price'])
# by using seaborn
sns.boxplot(x ='drive-wheels', y ='price', data = data)
# Predicting price based on engine size
# Known on x and predictable on y
plt.scatter(data['engine-size'], data['price'])
plt.title('Scatterplot of Enginesize vs Price')
plt.xlabel('Engine size')
plt.ylabel('Price')
plt.grid()
plt.show()
Producción:
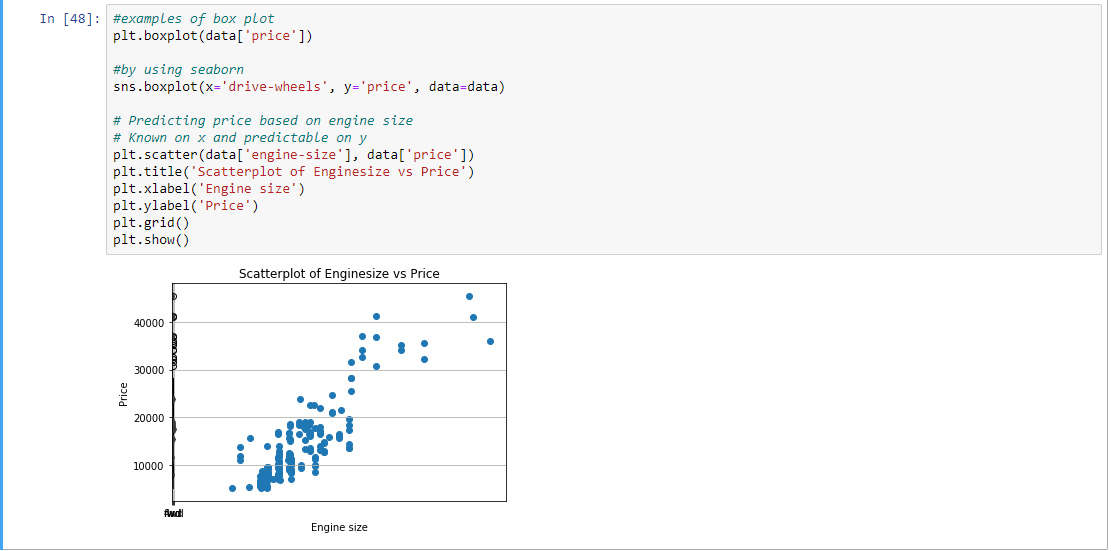
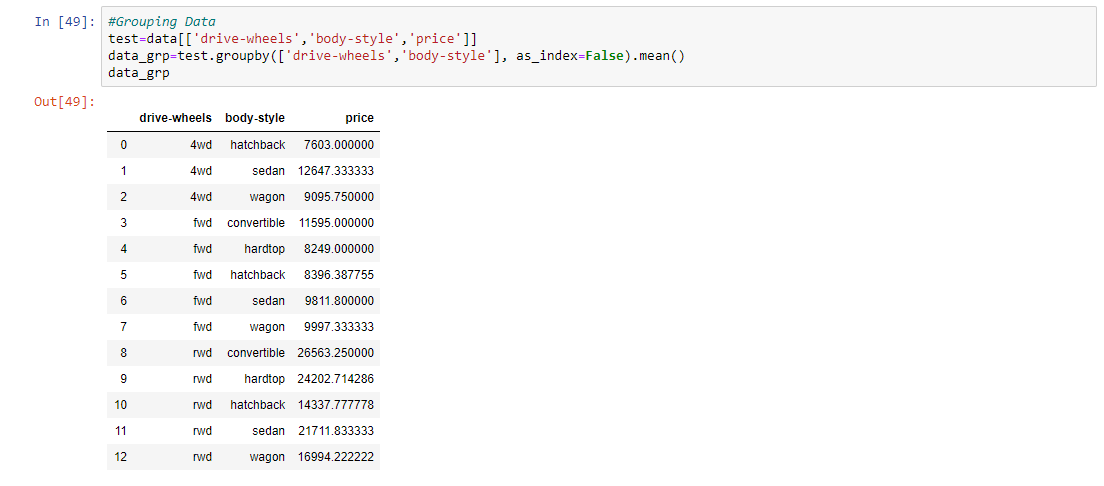
Paso 9: Agrupación de los datos según rueda, estilo de carrocería y precio.
# Grouping Data test = data[['drive-wheels', 'body-style', 'price']] data_grp = test.groupby(['drive-wheels', 'body-style'], as_index = False).mean() data_grp
Producción:
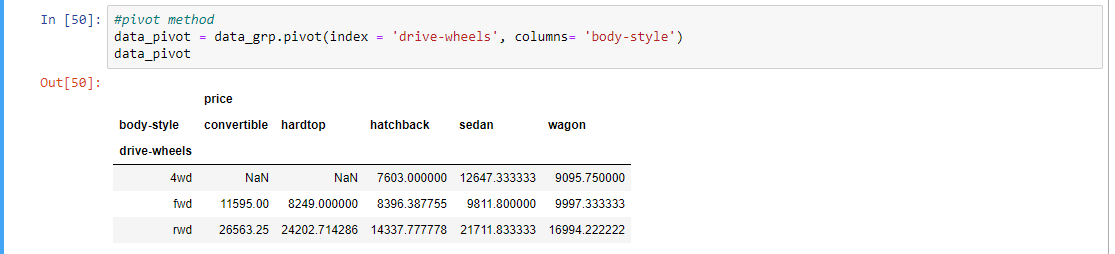
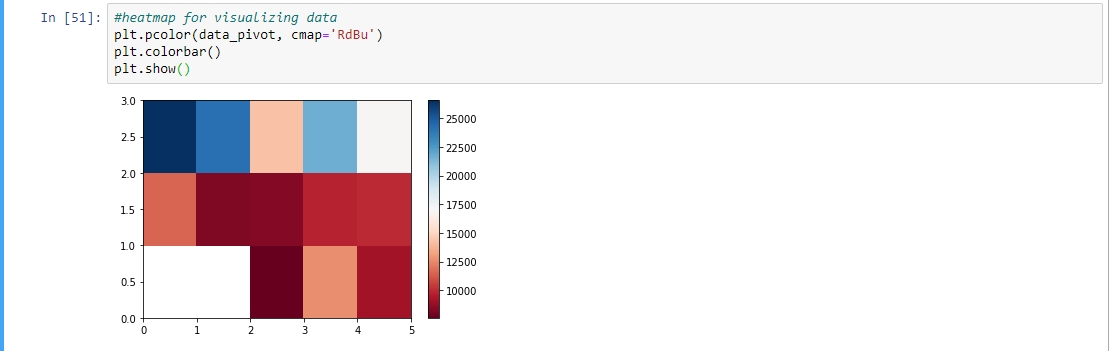
Paso 10: Usar el método pivote y trazar el mapa de calor de acuerdo con los datos obtenidos por el método pivote
# pivot method data_pivot = data_grp.pivot(index = 'drive-wheels', columns = 'body-style') data_pivot # heatmap for visualizing data plt.pcolor(data_pivot, cmap ='RdBu') plt.colorbar() plt.show()
Producción:
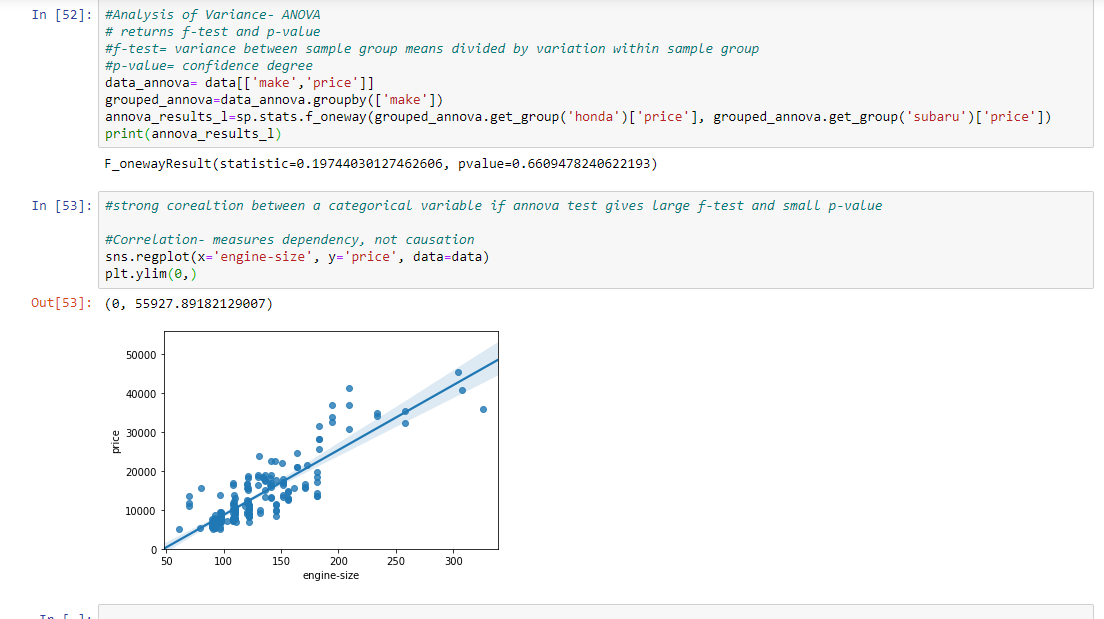
Paso 11: Obteniendo el resultado final y mostrándolo en forma de gráfico. Como la pendiente aumenta en una dirección positiva, es una relación lineal positiva.
# Analysis of Variance- ANOVA
# returns f-test and p-value
# f-test = variance between sample group means divided by
# variation within sample group
# p-value = confidence degree
data_annova = data[['make', 'price']]
grouped_annova = data_annova.groupby(['make'])
annova_results_l = sp.stats.f_oneway(
grouped_annova.get_group('honda')['price'],
grouped_annova.get_group('subaru')['price']
)
print(annova_results_l)
# strong corealtion between a categorical variable
# if annova test gives large f-test and small p-value
# Correlation- measures dependency, not causation
sns.regplot(x ='engine-size', y ='price', data = data)
plt.ylim(0, )
Producción:
Publicación traducida automáticamente
Artículo escrito por sanmaypaniker y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA