Requisito previo: Introducción a Hadoop
HBase es un modelo de datos similar a la tabla grande de Google. Es una base de datos distribuida de código abierto desarrollada por la fundación de software Apache escrita en Java. HBase es una parte esencial de nuestro ecosistema Hadoop. HBase se ejecuta sobre HDFS (Sistema de archivos distribuido de Hadoop). Puede almacenar cantidades masivas de datos de terabytes a petabytes. Está orientado a columnas y es escalable horizontalmente.
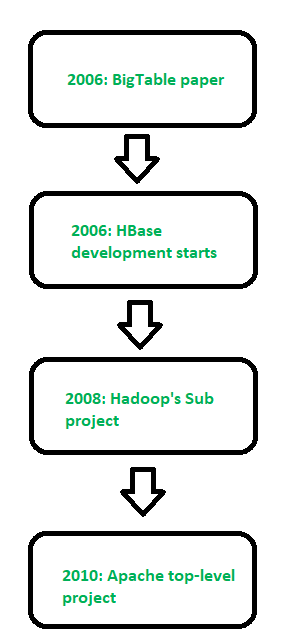
Figura – Historia de HBase
Características de HBase –
- Es linealmente escalable en varios Nodes, así como modularmente escalable, ya que se divide en varios Nodes.
- HBase proporciona lecturas y escrituras consistentes.
- Proporciona medios atómicos de lectura y escritura durante un proceso de lectura o escritura, todos los demás procesos no pueden realizar ninguna operación de lectura o escritura.
- Proporciona una API de Java fácil de usar para el acceso del cliente.
- Es compatible con Thrift y REST API para front-end que no son de Java, lo que admite opciones de codificación de datos binarios, Protobuf y XML.
- Admite Block Cache y Bloom Filters para consultas en tiempo real y para la optimización de consultas de gran volumen.
- HBase proporciona soporte de falla automática entre servidores de región.
- Es compatible con la exportación de métricas con el subsistema de métricas de Hadoop a archivos.
- No impone la relación dentro de sus datos.
- Es una plataforma para almacenar y recuperar datos con acceso aleatorio.
Facebook Messenger Platform estaba usando Apache Cassandra pero cambió de Apache Cassandra a HBase en noviembre de 2010. Facebook estaba tratando de construir una infraestructura escalable y robusta para manejar un conjunto de servicios como mensajes, correo electrónico, chat y SMS en una conversación en tiempo real, por eso HBase es el más adecuado para eso.
RDBMS frente a HBase –
- RDBMS está principalmente orientado a filas, mientras que HBase está orientado a columnas.
- RDBMS tiene un esquema fijo, pero en HBase también podemos escalar o agregar columnas en tiempo de ejecución.
- RDBMS es bueno para datos estructurados, mientras que HBase es bueno para datos semiestructurados.
- RDBMS está optimizado para uniones pero HBase no está optimizado para uniones.
Publicación traducida automáticamente
Artículo escrito por APOORV_CHAUDHARY y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA