Requisito previo: Instalación de Hive 3.1.2, Instalación de Hadoop 3.1.2
HiveQL o HQL es un lenguaje de consulta de Hive que usamos para procesar o consultar datos estructurados en Hive. Las sintaxis de HQL son muy similares a MySQL pero tienen algunas diferencias significativas. Usaremos el comando hive , que es un script de shell bash para completar nuestra demostración de hive usando CLI (interfaz de línea de comandos). Podemos iniciar Hive Shell fácilmente simplemente escribiendo hive en la terminal. Asegúrese de que el directorio /bin de su instalación de Hive se mencione en el archivo .basrc . El archivo .bashrc se ejecuta automáticamente cuando el usuario inicia sesión en el sistema y se ejecutarán todos los comandos necesarios mencionados en este archivo de script. Simplemente podemos comprobar si el /binEl directorio está disponible o no simplemente abriéndolo con el comando como se muestra a continuación.
sudo gedit ~/.bashrc
En caso de que no se agregue la ruta, agréguela para que podamos ejecutar directamente el shell de Hive desde la terminal sin movernos al directorio de Hive. De lo contrario, podemos iniciar Hive manualmente yendo al directorio apache-hive-3.1.2/bin/ y presionando el comando Hive .
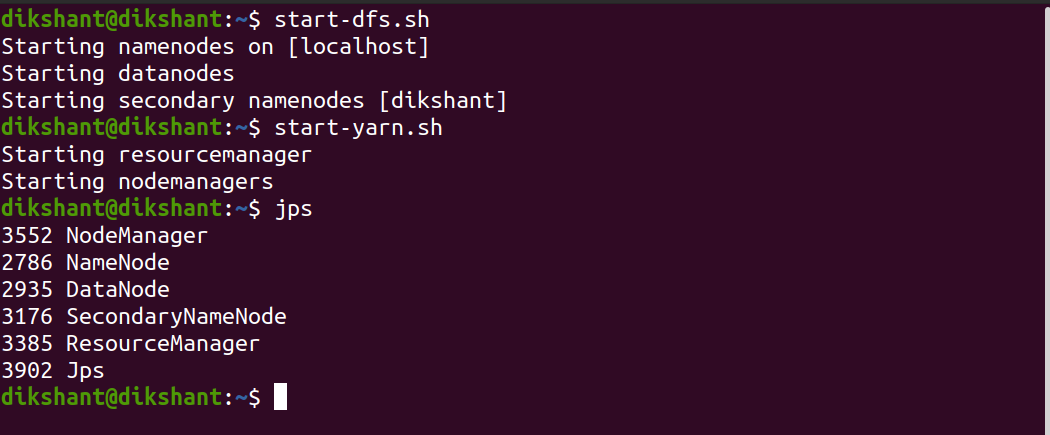
Antes de ejecutar Hive , asegúrese de que todos sus demonios de Hadoop estén iniciados y funcionando. Simplemente podemos iniciar todo el demonio de Hadoop con el siguiente comando.
start-dfs.sh # this will start namenode, datanode and secondary namenode start-yarn.sh # this will start node manager and resource manager jps # To check running daemons
Bases de datos en Apache Hive
La base de datos es un esquema de almacenamiento que contiene varias tablas. Las bases de datos de Hive hacen referencia al espacio de nombres de las tablas. Si no especifica el nombre de la base de datos de forma predeterminada, Hive utiliza su base de datos predeterminada para la creación de tablas y otros fines. La creación de una base de datos permite que varios usuarios creen tablas con un nombre similar en diferentes esquemas para que sus nombres no coincidan.
Entonces, comencemos nuestro shell de colmena para realizar nuestras tareas con el siguiente comando.
hive
Vea las bases de datos ya existentes usando el siguiente comando.
show databases; # this will show the existing databases

Crear sintaxis de base de datos:
Podemos crear una base de datos con la ayuda del siguiente comando, pero si la base de datos ya existe, en ese caso, Hive arrojará un error.
CREATE DATABASE|SCHEMA <database name> # we can use DATABASE or SCHEMA for creation of DB
Ejemplo:
CREATE DATABASE Test; # create database with name Test show databases; # this will show the existing databases
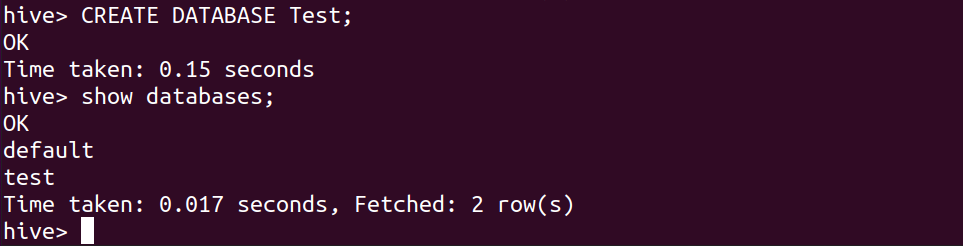
Si volvemos a intentar crear una sección de la base de datos de Prueba, arrojará un error/advertencia de que la base de datos con el nombre Prueba ya existe. En general, no queremos obtener un error si la base de datos existe. Así que usamos el comando de creación de base de datos con la cláusula [SI NO EXISTE]. Esto no arrojará ningún error.
CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name>
Ejemplo:
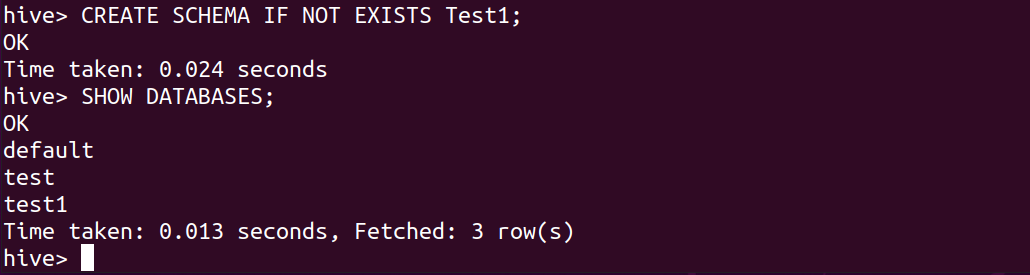
CREATE SCHEMA IF NOT EXISTS Test1; SHOW DATABASES;
Sintaxis para descartar bases de datos existentes:
DROP DATABASE <db_name>; or DROP DATABASE IF EXIST <db_name> # The IF EXIST clause again is used to suppress error
Ejemplo:
DROP DATABASE IF EXISTS Test; DROP DATABASE Test1;
Ahora salga de Hive Shell con el comando de salida .
quit;

Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA