La partición en Apache Hive es muy necesaria para mejorar el rendimiento al escanear las tablas de Hive. Permite a un usuario que trabaja en la colmena consultar una parte pequeña o deseada de las tablas de la colmena.
Supongamos que tenemos una tabla de estudiantes que contiene 5000 registros y queremos procesar solo los datos de los estudiantes que pertenecen a la sección ‘A’ únicamente. Sin embargo, la tabla de estudiantes contiene registros de estudiantes que pertenecen a todas las secciones (A, B, C, D) pero con la partición, no necesitamos procesar todos esos 5000 registros. Aquí, la partición nos ayuda a separar los datos de los estudiantes según sus secciones. Al hacerlo, se incrementará el tiempo para ejecutar la consulta, y no necesitaremos escanear todos los demás datos innecesarios disponibles dentro de la tabla ‘estudiante’.
La partición en la colmena puede ser estática o dinámica. En este artículo, implementaremos la partición estática en la colmena.
Características del particionamiento estático
- Las particiones se agregan manualmente, por lo que también se conoce como partición manual
- La carga de datos en el particionamiento estático es más rápida que en el particionamiento dinámico, por lo que se prefiere el particionamiento estático cuando tenemos que cargar archivos masivos.
- En el particionamiento estático, los archivos individuales se cargan según la partición que queremos configurar.
- donde se usa la cláusula para usar el límite en la partición estática
- Se permite alterar la partición en la partición estática, mientras que la partición dinámica no admite la instrucción Alter.
Para realizar la siguiente operación, asegúrese de que su colmena esté funcionando. A continuación se muestran los pasos para iniciar una colmena en su sistema local.
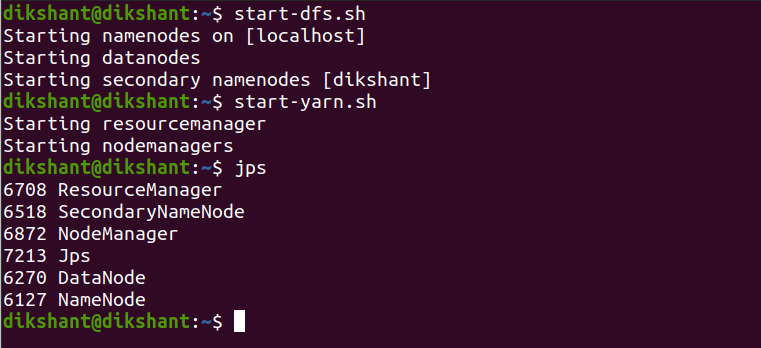
Paso 1: Inicie todo su Hadoop Daemon
start-dfs.sh # this will start namenode, datanode and secondary namenode start-yarn.sh # this will start node manager and resource manager jps # To check running daemons
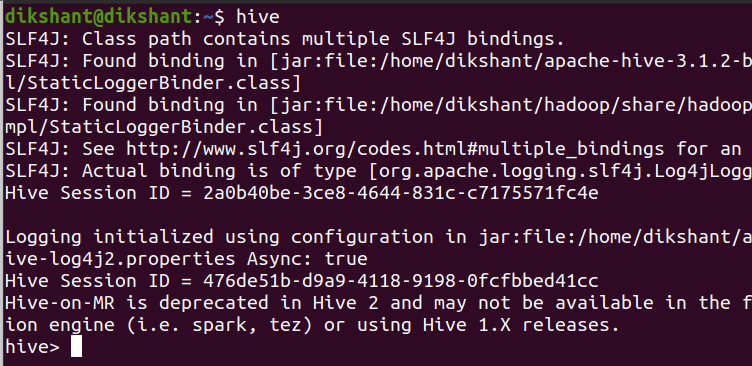
Paso 2: Inicie Hive desde la terminal
hive
Ahora, estamos listos para realizar la demostración rápida.
Particionamiento estático
En el particionamiento estático, particionamos la tabla en función de algún atributo. Los atributos o columnas que usamos para separar registros no están presentes en los datos reales que cargamos en nuestra tabla, pero los separamos usando la instrucción de partición disponible en Hive. Las particiones se dividen manualmente, por eso la partición estática también se conoce como partición manual. a continuación se muestra el ejemplo bien explicado que te ayuda a entenderlo bien.
Paso 1: Vamos a crear una tabla ‘estudiante’ con los siguientes atributos (nombre_estudiante, nombre_padre y porcentaje) y dividirla usando ‘sección’ en nuestra base de datos predeterminada.
Nota: No proporcione el nombre de las columnas particionadas en la instrucción create table <table-name> . Una vez que haya mencionado los nombres en la instrucción Partitioned by , se dividirán automáticamente con sus respectivos atributos en la tabla Hive.
CREATE TABLE student(student_name STRING ,father_name STRING ,percentage FLOAT) partitioned by (section STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';

Paso 2: describa la tabla para ver información sobre los atributos de la tabla y las columnas particionadas
describe student;
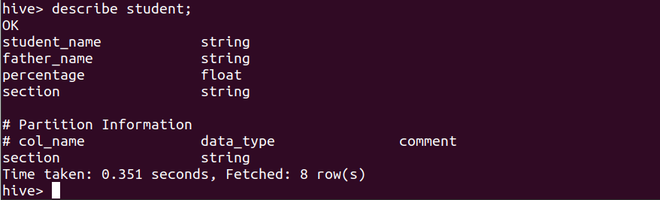
Aquí podemos ver que la columna de la sección se marcó como el atributo de partición y también se agregó a la lista de atributos de la tabla.
Paso 3: Cree 4 archivos diferentes que contengan datos de estudiantes de las secciones respectivas (estudiante-A, estudiante-B, estudiante-C, estudiante-D) asegúrese de que la columna de la sección , que es nuestra columna de partición, nunca se agregue a la tabla real.

Creación de mesa de alumnos según sus secciones
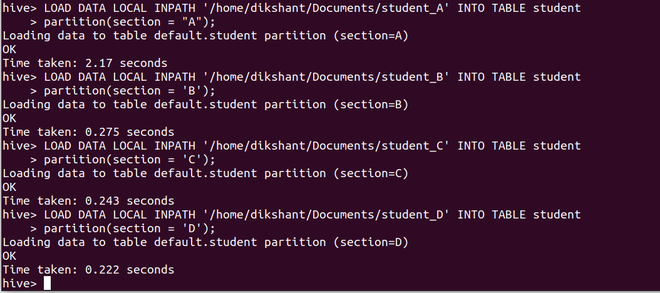
Paso 4: Cargue los datos de 4 archivos diferentes que contengan datos del estudiante por secciones en nuestra tabla de estudiantes junto con el valor del atributo particionado.
una. Cargando datos de estudiante_A particionados con la sección ‘A’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_A' INTO TABLE student partition(section = "A");
b. Cargando datos de student_B particionados con la sección ‘B’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_B' INTO TABLE student partition(section = 'B');
C. Cargando datos de student_C particionados con la sección ‘C’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_C' INTO TABLE student partition(section = 'C');
re . Cargando datos de student_D particionados con la sección ‘D’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_D' INTO TABLE student partition(section = 'D');
Paso 5: Ahora ve a tu HDFS (/user/hive/warehouse/) y revisa la tabla de estudiantes para ver cómo se hacen las particiones.
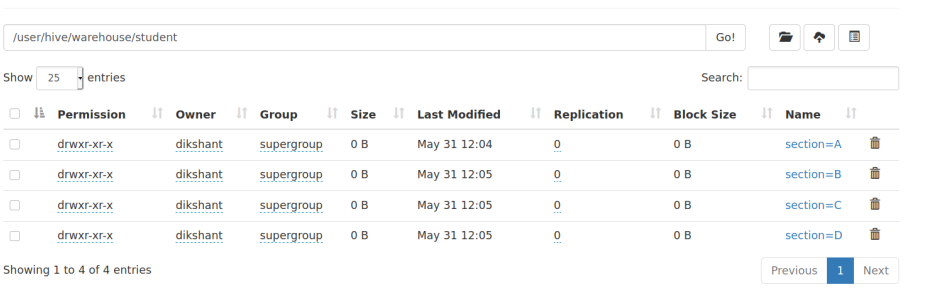
Aquí podemos observar fácilmente que la tabla de estudiantes está dividida y contiene datos de estudiantes de acuerdo con su sección. Ahora, si queremos procesar los datos del estudiante que pertenecen a la sección_A, no necesitamos recorrer toda la tabla ya que está dividida. Cada partición contiene los datos de la tabla según la partición mencionada.
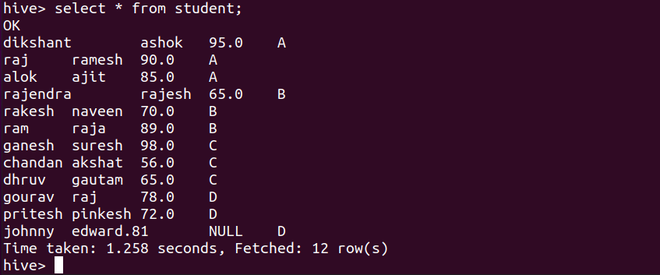
Debajo de la consulta de selección, se seleccionará todo de la tabla de estudiantes . Como podemos observar, no hemos agregado ninguna columna de sección, pero como se menciona manualmente en una partición, se agrega.
select * from student;
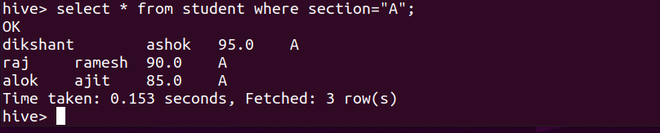
Ahora, si operamos en esta tabla de estudiantes con la cláusula where como se ve a continuación. Hive nunca consultará todos esos 12 registros. Es simplemente realizar el procesamiento en la partición hecha por nosotros en esta tabla de estudiantes. En nuestro caso, solo consultará la partición section=A .
select * from student where section="A";
Así es como realizamos la partición estática en la colmena.
Publicación traducida automáticamente
Artículo escrito por dikshantmalidev y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA