En este artículo, vamos a ver cómo aplanar una lista de tramas de datos. El aplanamiento se define como convertir o cambiar el formato de datos a un formato estrecho. La ventaja de la lista aplanada es que aumenta la velocidad de computación y la buena comprensión de los datos.
Ejemplo:
Consideremos el marco de datos que contiene valores como pagos en cuatro meses. En realidad, los datos se almacenan en un formato de lista.

Nota: 0,1,2 son los índices de los registros
Aplanar significa asignar listas por separado para cada autor.
Vamos a realizar operaciones de aplanamiento en la lista usando marcos de datos.
Método 1:
Paso 1: Cree un marco de datos simple.
Python3
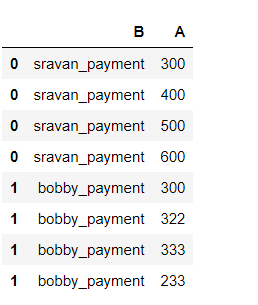
#importing pandas module import pandas as pd #creating dataframe with 2 columns df = pd.DataFrame(data=[[[ 300, 400, 500, 600], 'sravan_payment'], [[ 300, 322, 333, 233], 'bobby_payment']], index=[ 0, 1], columns=[ 'A', 'B']) display(df)
Producción:
Paso 2: itera cada fila con una columna específica.
Python3
flatdata = pd.DataFrame([( index, value) for ( index, values) in df[ 'A' ].iteritems() for value in values], columns = [ 'index', 'A']).set_index( 'index' ) df = df.drop( 'A', axis = 1 ).join( flatdata ) display(df)
Producción:
Métodos 2: Uso de los métodos de aplanamiento.
Vamos a aplicar la función flatten para el código anterior.
Python3
#importing pandas module for dataframe. import pandas as pd df = pd.DataFrame(data=[[[ 300, 400, 500, 600], 'sravan_payment'], [[ 300, 322, 333, 233], 'bobby_payment']], index = [ 0, 1], columns = [ 'A', 'B']) display(df)
Producción:
Python3
df.values.flatten()
Producción:

Publicación traducida automáticamente
Artículo escrito por sravankumar8128 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA