Dada una string, encuentra la substring más larga que es palíndromo.
Ya hemos discutido los enfoques Naïve [O(n 3 )], cuadrático [O(n 2 )] y lineal [O(n)] en el Conjunto 1 , Conjunto 2 y el Algoritmo de Manacher .
En este artículo, discutiremos otro enfoque de tiempo lineal basado en el árbol de sufijos.
Si la string dada es S, entonces el enfoque es el siguiente:
- Invierta la string S (digamos que la string invertida es R)
- Obtenga la substring común más larga de S y R dado que LCS en S y R debe estar en la misma posición en S
¿Puedes ver por qué decimos que LCS en R y S debe estar desde la misma posición en S ?
Veamos los siguientes ejemplos:
- Para S = xababayz y R = zyababax , LCS y LPS ambos son ababa (SAME)
- Para S = abacdfgdcaba y R = abacdgfdcaba , LCS es abacd y LPS es aba (DIFERENTE)
- Para S = pqrqpabcdfgdcba y R = abcdgfdcbapqrqp , LCS y LPS son pqrqp (MISMO)
- Para S = pqqpabcdfghfdcba y R = abcdfhgfdcbapqqp , LCS es abcdf y LPS es pqqp (DIFERENTE)
Podemos ver que LCS y LPS no son siempre iguales. cuando son diferentes?
Cuando S tiene una copia invertida de una substring no palindrómica que tiene una longitud igual o mayor que LPS en S, entonces LCS y LPS serán diferentes .
En el segundo ejemplo anterior (S = abacdfgdcaba ), para la substring abacd , existe una copia inversa dcaba en S, que es de mayor longitud que LPS aba , por lo que LPS y LCS son diferentes aquí. Igual es el escenario en el ejemplo 4th . Para manejar este escenario, decimos que LPS en S es igual que LCS en S y R dado que LCS en R y S deben estar desde la misma posición en S. Si nos fijamos en el 2º
ejemplo de nuevo, la substring aba en R proviene exactamente de la misma posición en S que la substring aba en S, que es CERO (índice 0 ) y, por lo tanto, esto es LPS.
La restricción de posición:

Nos referiremos al índice de string S como índice directo (S i ) y al índice de string R como índice inverso (R i ).
Según la figura anterior, un carácter con índice i (índice directo) en una string S de longitud N, estará en el índice N-1-i (índice inverso) en su string invertida R.
Si tomamos una substring de longitud L en string S con índice inicial i y índice final j (j = i+L-1), luego en su string invertida R, la substring invertida de la misma comenzará en el índice N-1-j y terminará en el índice N-1 -i.
Si hay una substring común de longitud L en los índices S i (índice directo) y R i (índice inverso) en S y R, estos vendrán desde la misma posición en S si R i = (N – 1) – (S i+ L – 1) donde N es la longitud de la string.
Entonces, para encontrar LPS de la string S, encontramos la string común más larga de S y R donde ambas substrings satisfacen la restricción anterior, es decir, si la substring en S está en el índice Si , entonces la misma substring debe estar en R en el índice (N – 1) – (Si + L – 1) . Si este no es el caso, entonces esta substring no es candidata a LPS.
Los enfoques ingenuos [O(N*M 2 )] y de programación dinámica [O(N*M)] para encontrar LCS de dos strings ya se analizan aquí, que se pueden ampliar para agregar restricciones de posición para dar LPS de una string determinada.
Ahora discutiremos el enfoque del árbol de sufijos, que no es más que una extensión del enfoque LCS del árbol de sufijos, donde agregaremos la restricción de posición.
Mientras encontramos LCS de dos strings X e Y, simplemente tomamos el Node más profundo marcado como XY (es decir, el Node que tiene sufijos de ambas strings como sus hijos).
Mientras buscamos LPS de la string S, encontraremos nuevamente LCS de S y R con la condición de que la substring común debe satisfacer la restricción de posición (la substring común debe provenir de la misma posición en S). Para verificar la restricción de posición, necesitamos conocer todos los índices directos e inversos en cada Node interno (es decir, los índices de sufijo de todos los hijos de hoja debajo de los Nodes internos).
En el árbol de sufijos generalizados de S#R$, una substring en la ruta desde la raíz a un Node interno es una substring común si el Node interno tiene sufijos de ambas strings S y R. El índice de la substring común en S y R se puede encontrar mirando el índice de sufijo en la hoja respectiva Node.
Si la string S# tiene una longitud N, entonces:
- Si el índice de sufijo de una hoja es menor que N, entonces ese sufijo pertenece a S y el mismo índice de sufijo se convertirá en el índice directo de todos los Nodes antepasados.
- Si el índice de sufijo de una hoja es mayor que N, entonces ese sufijo pertenece a R y el índice inverso para todos los Nodes antecesores será N – índice de sufijo
Tomemos la string S = cabbaabb . La siguiente figura es un árbol de sufijos generalizados para cabbaabb#bbaabbac$ donde hemos mostrado índices directos e inversos de todos los sufijos secundarios en todos los Nodes internos (excepto raíz).
Los índices directos están entre paréntesis() y los índices inversos están entre corchetes [].
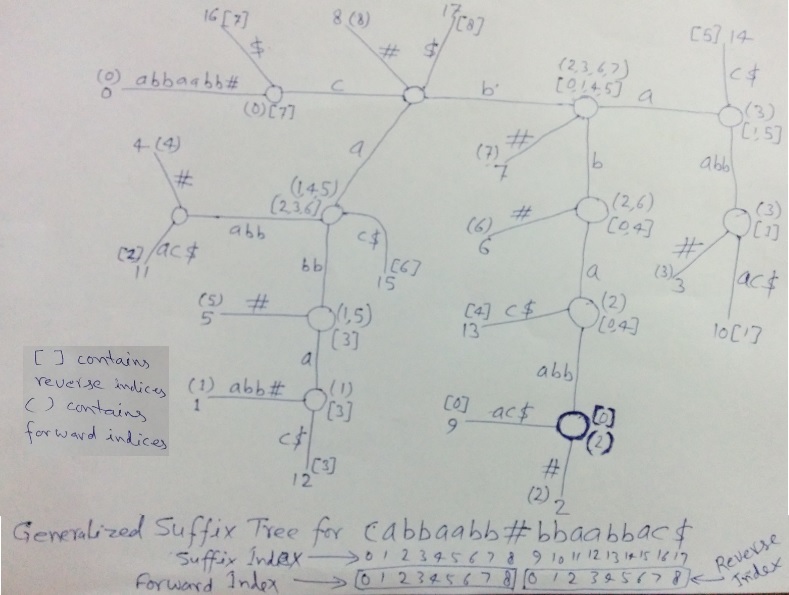
En la figura anterior, todos los Nodes hoja tendrán un índice directo o inverso según la string (S o R) a la que pertenezcan. Luego, los índices directos o inversos de los hijos se propagan al padre.
Mire la figura para comprender cuál sería el índice hacia adelante o hacia atrás en una hoja con un índice de sufijo dado. En la parte inferior de la figura, se muestra que las hojas con índices de sufijo de 0 a 8 obtendrán los mismos valores (0 a 8) que su índice directo en S y las hojas con índices de sufijo 9 a 17 obtendrán un índice inverso en R de 0 a 8.
Por ejemplo, el Node interno resaltado tiene dos hijos con índices de sufijo 2 y 9. La hoja con índice de sufijo 2 es de la posición 2 en S, por lo que su índice de avance es 2 y se muestra en(). La hoja con el índice de sufijo 9 es de la posición 0 en R, por lo que su índice inverso es 0 y se muestra en []. Estos índices se propagan al padre y el padre tiene una hoja con el índice de sufijo 14 para el cual el índice inverso es 4. Entonces, en este Node principal, el índice directo es (2) y el índice inverso es [0,4]. Y de la misma manera, deberíamos poder entender cómo se calculan los índices directos e inversos en todos los Nodes.
En la figura anterior, todos los Nodes internos tienen sufijos de las strings S y R, es decir, todos ellos representan una substring común en la ruta desde la raíz hasta ellos mismos. Ahora necesitamos encontrar el Node más profundo que satisfaga la restricción de posición. Para esto, debemos verificar si hay un índice directo S i en un Node, luego debe haber un índice inverso R i con valor (N – 2) – (S i + L – 1) donde N es la longitud de la string S# y L es la profundidad del Node (o la longitud de la substring). En caso afirmativo, considere este Node como candidato a LPS; de lo contrario, ignórelo. En la figura anterior, se resalta el Node más profundo que representa LPS como bbaabb.
No hemos mostrado índices directos e inversos en el Node raíz en la figura. Debido a que el Node raíz en sí mismo no representa ninguna substring común (también en la implementación del código, los índices directo e inverso no se calcularán en el Node raíz)
¿Cómo implementar este enfoque para encontrar LPS? Estas son las cosas que necesitamos:
- Necesitamos saber los índices de avance y retroceso en cada Node.
- Para un índice directo S i dado en un Node interno, necesitamos saber si el índice inverso R i = (N – 2) – (S i + L – 1) también está presente en el mismo Node.
- Realice un seguimiento del Node interno más profundo que satisfaga la condición anterior.
Una forma de hacer lo anterior es:
mientras DFS está en el árbol de sufijos, podemos almacenar índices directos e inversos en cada Node de alguna manera (el almacenamiento ayudará a evitar recorridos repetidos en el árbol cuando necesitamos saber los índices directos e inversos en un Node). Más tarde, podemos hacer otro DFS para buscar Nodes que satisfagan la restricción de posición. Para verificar la restricción de posición, necesitamos buscar en la lista de índices.
¿Qué estructura de datos es adecuada aquí para hacer todo esto de la manera más rápida?
- Si almacenamos índices en una array, requerirá una búsqueda lineal que hará que el enfoque general no sea lineal en el tiempo.
- Si almacenamos índices en un árbol (establecido en C++, TreeSet en Java), podemos usar la búsqueda binaria, pero aún así el enfoque general será no lineal en el tiempo.
- Si almacenamos índices en un conjunto basado en funciones hash (unordered_set en C++, HashSet en Java), proporcionará una búsqueda constante en promedio y esto hará que el enfoque general sea lineal en el tiempo. Un conjunto basado en una función hash puede ocupar más espacio dependiendo de los valores que se almacenen.
Usaremos dos unordered_set (uno para los índices directos y otro para los índices inversos) en nuestra implementación, agregados como una variable miembro en la estructura SuffixTreeNode.
C
// A C++ program to implement Ukkonen's Suffix Tree Construction
// Here we build generalized suffix tree for given string S
// and it's reverse R, then we find
// longest palindromic substring of given string S
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <iostream>
#include <unordered_set>
#define MAX_CHAR 256
using namespace std;
struct SuffixTreeNode {
struct SuffixTreeNode *children[MAX_CHAR];
//pointer to other node via suffix link
struct SuffixTreeNode *suffixLink;
/*(start, end) interval specifies the edge, by which the
node is connected to its parent node. Each edge will
connect two nodes, one parent and one child, and
(start, end) interval of a given edge will be stored
in the child node. Lets say there are two nods A and B
connected by an edge with indices (5, 8) then this
indices (5, 8) will be stored in node B. */
int start;
int *end;
/*for leaf nodes, it stores the index of suffix for
the path from root to leaf*/
int suffixIndex;
//To store indices of children suffixes in given string
unordered_set<int> *forwardIndices;
//To store indices of children suffixes in reversed string
unordered_set<int> *reverseIndices;
};
typedef struct SuffixTreeNode Node;
char text[100]; //Input string
Node *root = NULL; //Pointer to root node
/*lastNewNode will point to newly created internal node,
waiting for it's suffix link to be set, which might get
a new suffix link (other than root) in next extension of
same phase. lastNewNode will be set to NULL when last
newly created internal node (if there is any) got it's
suffix link reset to new internal node created in next
extension of same phase. */
Node *lastNewNode = NULL;
Node *activeNode = NULL;
/*activeEdge is represented as input string character
index (not the character itself)*/
int activeEdge = -1;
int activeLength = 0;
// remainingSuffixCount tells how many suffixes yet to
// be added in tree
int remainingSuffixCount = 0;
int leafEnd = -1;
int *rootEnd = NULL;
int *splitEnd = NULL;
int size = -1; //Length of input string
int size1 = 0; //Size of 1st string
int reverseIndex; //Index of a suffix in reversed string
unordered_set<int>::iterator forwardIndex;
Node *newNode(int start, int *end)
{
Node *node =(Node*) malloc(sizeof(Node));
int i;
for (i = 0; i < MAX_CHAR; i++)
node->children[i] = NULL;
/*For root node, suffixLink will be set to NULL
For internal nodes, suffixLink will be set to root
by default in current extension and may change in
next extension*/
node->suffixLink = root;
node->start = start;
node->end = end;
/*suffixIndex will be set to -1 by default and
actual suffix index will be set later for leaves
at the end of all phases*/
node->suffixIndex = -1;
node->forwardIndices = new unordered_set<int>;
node->reverseIndices = new unordered_set<int>;
return node;
}
int edgeLength(Node *n) {
if(n == root)
return 0;
return *(n->end) - (n->start) + 1;
}
int walkDown(Node *currNode)
{
/*activePoint change for walk down (APCFWD) using
Skip/Count Trick (Trick 1). If activeLength is greater
than current edge length, set next internal node as
activeNode and adjust activeEdge and activeLength
accordingly to represent same activePoint*/
if (activeLength >= edgeLength(currNode))
{
activeEdge += edgeLength(currNode);
activeLength -= edgeLength(currNode);
activeNode = currNode;
return 1;
}
return 0;
}
void extendSuffixTree(int pos)
{
/*Extension Rule 1, this takes care of extending all
leaves created so far in tree*/
leafEnd = pos;
/*Increment remainingSuffixCount indicating that a
new suffix added to the list of suffixes yet to be
added in tree*/
remainingSuffixCount++;
/*set lastNewNode to NULL while starting a new phase,
indicating there is no internal node waiting for
it's suffix link reset in current phase*/
lastNewNode = NULL;
//Add all suffixes (yet to be added) one by one in tree
while(remainingSuffixCount > 0) {
if (activeLength == 0)
activeEdge = pos; //APCFALZ
// There is no outgoing edge starting with
// activeEdge from activeNode
if (activeNode->children] == NULL)
{
//Extension Rule 2 (A new leaf edge gets created)
activeNode->children] =
newNode(pos, &leafEnd);
/*A new leaf edge is created in above line starting
from an existing node (the current activeNode), and
if there is any internal node waiting for it's suffix
link get reset, point the suffix link from that last
internal node to current activeNode. Then set lastNewNode
to NULL indicating no more node waiting for suffix link
reset.*/
if (lastNewNode != NULL)
{
lastNewNode->suffixLink = activeNode;
lastNewNode = NULL;
}
}
// There is an outgoing edge starting with activeEdge
// from activeNode
else
{
// Get the next node at the end of edge starting
// with activeEdge
Node *next = activeNode->children] ;
if (walkDown(next))//Do walkdown
{
//Start from next node (the new activeNode)
continue;
}
/*Extension Rule 3 (current character being processed
is already on the edge)*/
if (text[next->start + activeLength] == text[pos])
{
//APCFER3
activeLength++;
/*STOP all further processing in this phase
and move on to next phase*/
break;
}
/*We will be here when activePoint is in middle of
the edge being traversed and current character
being processed is not on the edge (we fall off
the tree). In this case, we add a new internal node
and a new leaf edge going out of that new node. This
is Extension Rule 2, where a new leaf edge and a new
internal node get created*/
splitEnd = (int*) malloc(sizeof(int));
*splitEnd = next->start + activeLength - 1;
//New internal node
Node *split = newNode(next->start, splitEnd);
activeNode->children] = split;
//New leaf coming out of new internal node
split->children] = newNode(pos, &leafEnd);
next->start += activeLength;
split->children] = next;
/*We got a new internal node here. If there is any
internal node created in last extensions of same
phase which is still waiting for it's suffix link
reset, do it now.*/
if (lastNewNode != NULL)
{
/*suffixLink of lastNewNode points to current newly
created internal node*/
lastNewNode->suffixLink = split;
}
/*Make the current newly created internal node waiting
for it's suffix link reset (which is pointing to root
at present). If we come across any other internal node
(existing or newly created) in next extension of same
phase, when a new leaf edge gets added (i.e. when
Extension Rule 2 applies is any of the next extension
of same phase) at that point, suffixLink of this node
will point to that internal node.*/
lastNewNode = split;
}
/* One suffix got added in tree, decrement the count of
suffixes yet to be added.*/
remainingSuffixCount--;
if (activeNode == root && activeLength > 0) //APCFER2C1
{
activeLength--;
activeEdge = pos - remainingSuffixCount + 1;
}
else if (activeNode != root) //APCFER2C2
{
activeNode = activeNode->suffixLink;
}
}
}
void print(int i, int j)
{
int k;
for (k=i; k<=j && text[k] != '#'; k++)
printf("%c", text[k]);
if(k<=j)
printf("#");
}
//Print the suffix tree as well along with setting suffix index
//So tree will be printed in DFS manner
//Each edge along with it's suffix index will be printed
void setSuffixIndexByDFS(Node *n, int labelHeight)
{
if (n == NULL) return;
if (n->start != -1) //A non-root node
{
//Print the label on edge from parent to current node
//Uncomment below line to print suffix tree
//print(n->start, *(n->end));
}
int leaf = 1;
int i;
for (i = 0; i < MAX_CHAR; i++)
{
if (n->children[i] != NULL)
{
//Uncomment below two lines to print suffix index
// if (leaf == 1 && n->start != -1)
// printf(" [%d]\n", n->suffixIndex);
//Current node is not a leaf as it has outgoing
//edges from it.
leaf = 0;
setSuffixIndexByDFS(n->children[i], labelHeight +
edgeLength(n->children[i]));
if(n != root)
{
//Add children's suffix indices in parent
n->forwardIndices->insert(
n->children[i]->forwardIndices->begin(),
n->children[i]->forwardIndices->end());
n->reverseIndices->insert(
n->children[i]->reverseIndices->begin(),
n->children[i]->reverseIndices->end());
}
}
}
if (leaf == 1)
{
for(i= n->start; i<= *(n->end); i++)
{
if(text[i] == '#')
{
n->end = (int*) malloc(sizeof(int));
*(n->end) = i;
}
}
n->suffixIndex = size - labelHeight;
if(n->suffixIndex < size1) //Suffix of Given String
n->forwardIndices->insert(n->suffixIndex);
else //Suffix of Reversed String
n->reverseIndices->insert(n->suffixIndex - size1);
//Uncomment below line to print suffix index
// printf(" [%d]\n", n->suffixIndex);
}
}
void freeSuffixTreeByPostOrder(Node *n)
{
if (n == NULL)
return;
int i;
for (i = 0; i < MAX_CHAR; i++)
{
if (n->children[i] != NULL)
{
freeSuffixTreeByPostOrder(n->children[i]);
}
}
if (n->suffixIndex == -1)
free(n->end);
free(n);
}
/*Build the suffix tree and print the edge labels along with
suffixIndex. suffixIndex for leaf edges will be >= 0 and
for non-leaf edges will be -1*/
void buildSuffixTree()
{
size = strlen(text);
int i;
rootEnd = (int*) malloc(sizeof(int));
*rootEnd = - 1;
/*Root is a special node with start and end indices as -1,
as it has no parent from where an edge comes to root*/
root = newNode(-1, rootEnd);
activeNode = root; //First activeNode will be root
for (i=0; i<size; i++)
extendSuffixTree(i);
int labelHeight = 0;
setSuffixIndexByDFS(root, labelHeight);
}
void doTraversal(Node *n, int labelHeight, int* maxHeight,
int* substringStartIndex)
{
if(n == NULL)
{
return;
}
int i=0;
int ret = -1;
if(n->suffixIndex < 0) //If it is internal node
{
for (i = 0; i < MAX_CHAR; i++)
{
if(n->children[i] != NULL)
{
doTraversal(n->children[i], labelHeight +
edgeLength(n->children[i]),
maxHeight, substringStartIndex);
if(*maxHeight < labelHeight
&& n->forwardIndices->size() > 0 &&
n->reverseIndices->size() > 0)
{
for (forwardIndex=n->forwardIndices->begin();
forwardIndex!=n->forwardIndices->end();
++forwardIndex)
{
reverseIndex = (size1 - 2) -
(*forwardIndex + labelHeight - 1);
//If reverse suffix comes from
//SAME position in given string
//Keep track of deepest node
if(n->reverseIndices->find(reverseIndex) !=
n->reverseIndices->end())
{
*maxHeight = labelHeight;
*substringStartIndex = *(n->end) -
labelHeight + 1;
break;
}
}
}
}
}
}
}
void getLongestPalindromicSubstring()
{
int maxHeight = 0;
int substringStartIndex = 0;
doTraversal(root, 0, &maxHeight, &substringStartIndex);
int k;
for (k=0; k<maxHeight; k++)
printf("%c", text[k + substringStartIndex]);
if(k == 0)
printf("No palindromic substring");
else
printf(", of length: %d",maxHeight);
printf("\n");
}
// driver program to test above functions
int main(int argc, char *argv[])
{
size1 = 9;
printf("Longest Palindromic Substring in cabbaabb is: ");
strcpy(text, "cabbaabb#bbaabbac$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 17;
printf("Longest Palindromic Substring in forgeeksskeegfor is: ");
strcpy(text, "forgeeksskeegfor#rofgeeksskeegrof$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf("Longest Palindromic Substring in abcde is: ");
strcpy(text, "abcde#edcba$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 7;
printf("Longest Palindromic Substring in abcdae is: ");
strcpy(text, "abcdae#eadcba$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf("Longest Palindromic Substring in abacd is: ");
strcpy(text, "abacd#dcaba$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf("Longest Palindromic Substring in abcdc is: ");
strcpy(text, "abcdc#cdcba$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 13;
printf("Longest Palindromic Substring in abacdfgdcaba is: ");
strcpy(text, "abacdfgdcaba#abacdgfdcaba$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 15;
printf("Longest Palindromic Substring in xyabacdfgdcaba is: ");
strcpy(text, "xyabacdfgdcaba#abacdgfdcabayx$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 9;
printf("Longest Palindromic Substring in xababayz is: ");
strcpy(text, "xababayz#zyababax$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
size1 = 6;
printf("Longest Palindromic Substring in xabax is: ");
strcpy(text, "xabax#xabax$"); buildSuffixTree();
getLongestPalindromicSubstring();
//Free the dynamically allocated memory
freeSuffixTreeByPostOrder(root);
return 0;
}
Producción:
Longest Palindromic Substring in cabbaabb is: bbaabb, of length: 6 Longest Palindromic Substring in forgeeksskeegfor is: geeksskeeg, of length: 10 Longest Palindromic Substring in abcde is: a, of length: 1 Longest Palindromic Substring in abcdae is: a, of length: 1 Longest Palindromic Substring in abacd is: aba, of length: 3 Longest Palindromic Substring in abcdc is: cdc, of length: 3 Longest Palindromic Substring in abacdfgdcaba is: aba, of length: 3 Longest Palindromic Substring in xyabacdfgdcaba is: aba, of length: 3 Longest Palindromic Substring in xababayz is: ababa, of length: 5 Longest Palindromic Substring in xabax is: xabax, of length: 5
Complejidad temporal: O(n)
Espacio Auxiliar: O(n)
Seguimiento:
Detectar TODOS los palíndromos en una string dada.
Por ejemplo, para la string abcddcbefgf, todos los palíndromos posibles son a, b, c, d, e, f, g, dd, fgf, cddc, bcddcb.
Hemos publicado los siguientes artículos sobre aplicaciones de árboles de sufijos:
- Aplicación de árbol de sufijos 1: comprobación de substrings
- Aplicación de árbol de sufijos 2: búsqueda de todos los patrones
- Aplicación de árbol de sufijos 3: substring repetida más larga
- Aplicación de árbol de sufijos 4: construir una array de sufijos de tiempo lineal
- Aplicación de árbol de sufijos 5: substring común más larga
- Árbol de sufijos generalizados 1
Este artículo es una contribución de Anurag Singh . Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA