Prerrequisitos: Pandas
Pandas es una biblioteca de Python para el análisis y la manipulación de datos. A menudo, el análisis de datos requiere que los datos se dividan en grupos para realizar varias operaciones en estos grupos. La función GroupBy en Pandas emplea la estrategia dividir-aplicar-combinar, lo que significa que realiza una combinación de: dividir un objeto, aplicar funciones al objeto y combinar los resultados. En este artículo, usaremos la función groupby() para realizar varias operaciones en datos agrupados.
Agregación
La agregación implica la creación de resúmenes estadísticos de datos con métodos como media, mediana, moda, min (mínimo), max (máximo), std (desviación estándar), var (varianza), suma, conteo, etc. Para realizar la operación de agregación en grupos:
- Módulo de importación
- Crear o cargar datos
- Cree un objeto GroupBy que agrupe datos a lo largo de una clave o varias claves
- Aplicar una operación estadística.
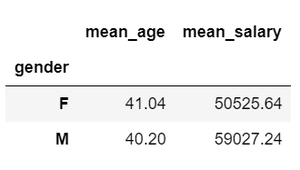
Ejemplo 1: Calcular los salarios medios y la edad de los grupos de hombres y mujeres. Da la media de las columnas numéricas y agrega un prefijo a los nombres de las columnas.
Python3
# Import required libraries
import pandas as pd
import numpy as np
# Create a sample dataframe
df = pd.DataFrame({"dept": np.random.choice(["IT", "HR", "Sales", "Production"], size=50),
"gender": np.random.choice(["F", "M"], size=50),
"age": np.random.randint(22, 60, size=50),
"salary": np.random.randint(20000, 90000, size=50)})
df.index.name = "emp_id"
# Calculate mean data of gender groups
df.groupby('gender').mean().add_prefix('mean_')
Producción:
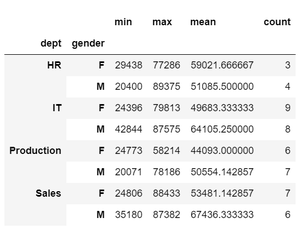
Ejemplo 2: Realización de varias operaciones de agregado utilizando la función de agregado ( DataFrameGroupBy.agg ) que acepta una string, una función o una lista de funciones.
Python3
# Import required libraries
import pandas as pd
import numpy as np
# Create a sample dataframe
df = pd.DataFrame({"dept": np.random.choice(["IT", "HR", "Sales", "Production"], size=50),
"gender": np.random.choice(["F", "M"], size=50),
"age": np.random.randint(22, 60, size=50),
"salary": np.random.randint(20000, 90000, size=50)})
df.index.name = "emp_id"
# Calculate min, max, mean and count of salaries
# in different departments for males and females
df.groupby(['dept', 'gender'])['salary'].agg(["min", "max", "mean", "count"])
Producción:
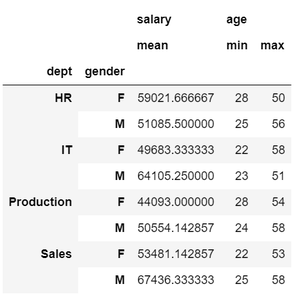
Ejemplo 3: especificación de varias columnas y sus correspondientes operaciones agregadas de la siguiente manera.
Python3
# Import required libraries
import pandas as pd
import numpy as np
# Create a sample dataframe
df = pd.DataFrame({"dept": np.random.choice(["IT", "HR", "Sales", "Production"], size=50),
"gender": np.random.choice(["F", "M"], size=50),
"age": np.random.randint(22, 60, size=50),
"salary": np.random.randint(20000, 90000, size=50)})
df.index.name = "emp_id"
# Calculate mean salaries and min-max age of employees
# in different departments for gender groups
df.groupby(['dept', 'gender']).agg({'salary': 'mean', 'age': ['min', 'max']})
Producción:
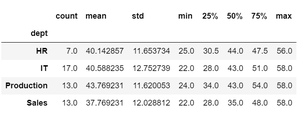
Ejemplo 4: Mostrar estadísticas comunes para cualquier grupo.
Python3
# Import required libraries
import pandas as pd
import numpy as np
# Create a sample dataframe
df = pd.DataFrame({"dept": np.random.choice(["IT", "HR", "Sales", "Production"], size=50),
"gender": np.random.choice(["F", "M"], size=50),
"age": np.random.randint(22, 60, size=50),
"salary": np.random.randint(20000, 90000, size=50)})
df.index.name = "emp_id"
# Statistics of employee age grouped by departments
df["age"].groupby(df['dept']).describe()
Producción:
Crear bins o grupos y aplicar operaciones
El método de corte de Pandas ordena los valores en intervalos de contenedores creando grupos o categorías. A continuación, se pueden realizar agregaciones u otras funciones en estos grupos. La implementación de esto se muestra a continuación:
Ejemplo: la edad se divide en rangos de edad y se calcula el recuento de observaciones en los datos de muestra.
Python3
# Import required libraries
import pandas as pd
import numpy as np
# Create a sample dataframe
df = pd.DataFrame({"dept": np.random.choice(["IT", "HR", "Sales", "Production"], size=50),
"gender": np.random.choice(["F", "M"], size=50),
"age": np.random.randint(22, 60, size=50),
"salary": np.random.randint(20000, 90000, size=50)})
df.index.name = "emp_id"
# Create bin intervals
bins = [20, 30, 45, 60]
# Segregate ages into bins of age groups
df['categories'] = pd.cut(df['age'], bins,
labels=['Young', 'Middle', 'Old'])
# Calculate number of observations in each age category
df['age'].groupby(df['categories']).count()
Producción:

Transformación
La transformación es realizar una operación específica de grupo en la que los valores individuales cambian mientras que la forma de los datos sigue siendo la misma. Usamos la función transform() para hacerlo.
Ejemplo :
Python3
# Import required libraries
import pandas as pd
import numpy as np
# Create a sample dataframe
df = pd.DataFrame({"dept": np.random.choice(["IT", "HR", "Sales", "Production"], size=50),
"gender": np.random.choice(["F", "M"], size=50),
"age": np.random.randint(22, 60, size=50),
"salary": np.random.randint(20000, 90000, size=50)})
df.index.name = "emp_id"
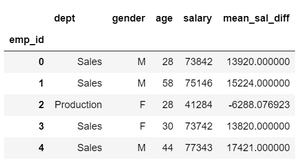
# Calculate mean difference by transforming each salary value
df['mean_sal_diff'] = df['salary'].groupby(
df['dept']).transform(lambda x: x - x.mean())
df.head()
Producción:
Publicación traducida automáticamente
Artículo escrito por akshisaxena y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA