Arthur Samuel “Machine Learning” “Campo de estudio que le da a las computadoras la capacidad de aprender sin ser programadas explícitamente”
En este artículo, analicemos los dos aprendizajes más importantes, por ejemplo, el aprendizaje supervisado y no supervisado en la programación R.
lenguaje R de la
Ventajas de implementar el aprendizaje automático usando el lenguaje R
- Proporciona un buen código explicativo. Por ejemplo, si se encuentra en la etapa inicial de trabajo con un proyecto de aprendizaje automático y necesita explicar el trabajo que realiza, se vuelve fácil trabajar con la comparación del lenguaje R con el lenguaje python, ya que proporciona el método estadístico adecuado para trabajar con datos. con menos líneas de código.
- El lenguaje R es perfecto para la visualización de datos. El lenguaje R proporciona el mejor prototipo para trabajar con modelos de aprendizaje automático.
- El lenguaje R tiene las mejores herramientas y paquetes de biblioteca para trabajar con proyectos de aprendizaje automático. Los desarrolladores pueden usar estos paquetes para crear el mejor modelo previo, modelo y modelo posterior de los proyectos de aprendizaje automático. Además, los paquetes para R son más avanzados y extensos que el lenguaje Python, lo que lo convierte en la primera opción para trabajar con proyectos de aprendizaje automático.
Aprendizaje supervisado
que el aprendizaje supervisado se clasifica en dos categorías de algoritmos:
- Clasificación : un problema de clasificación es cuando la variable de salida es una categoría, como «Rojo» o «azul» o «enfermedad» y «sin enfermedad».
- Regresión : un problema de regresión es cuando la variable de salida es un valor real, como «dólares» o «peso».
El aprendizaje supervisado trata o aprende con datos «etiquetados». Esto implica que algunos datos ya están etiquetados con la respuesta correcta.
Tipos
- Regresión
- Regresión logística
- Clasificación
- Clasificadores Naïve Bayes
- Árboles de decisión
- Máquinas de vectores soporte
Implementación en R
Implementemos uno de los aprendizajes supervisados muy populares, es decir , la regresión lineal simple en la programación R. Regresión lineal simple
lm(Y ~ modelo)
El comando lm() proporciona los coeficientes del modelo pero no proporciona más información estadística. El siguiente código R se usa para implementar la regresión lineal simple.
Ejemplo:
R
# Simple Linear Regression
# Importing the dataset
dataset = read.csv('salary.csv')
# Splitting the dataset into the
# Training set and Test set
install.packages('caTools')
library(caTools)
split = sample.split(dataset$Salary,
SplitRatio = 0.7)
trainingset = subset(dataset, split == TRUE)
testset = subset(dataset, split == FALSE)
# Fitting Simple Linear Regression
# to the Training set
lm.r = lm(formula = Salary ~ YearsExperience,
data = trainingset)
coef(lm.r)
# Predicting the Test set results
ypred = predict(lm.r, newdata = testset)
install.packages("ggplot2")
library(ggplot2)
# Visualising the Training set results
ggplot() + geom_point(aes(x = trainingset$YearsExperience,
y = trainingset$Salary),
colour = 'red') +
geom_line(aes(x = trainingset$YearsExperience,
y = predict(lm.r, newdata = trainingset)),
colour = 'blue') +
ggtitle('Salary vs Experience (Training set)') +
xlab('Years of experience') +
ylab('Salary')
# Visualising the Test set results
ggplot() + geom_point(aes(x = testset$YearsExperience,
y = testset$Salary),
colour = 'red') +
geom_line(aes(x = trainingset$YearsExperience,
y = predict(lm.r, newdata = trainingset)),
colour = 'blue') +
ggtitle('Salary vs Experience (Test set)') +
xlab('Years of experience') +
ylab('Salary')
Producción:
Intercept YearsExperience 24558.39 10639.23
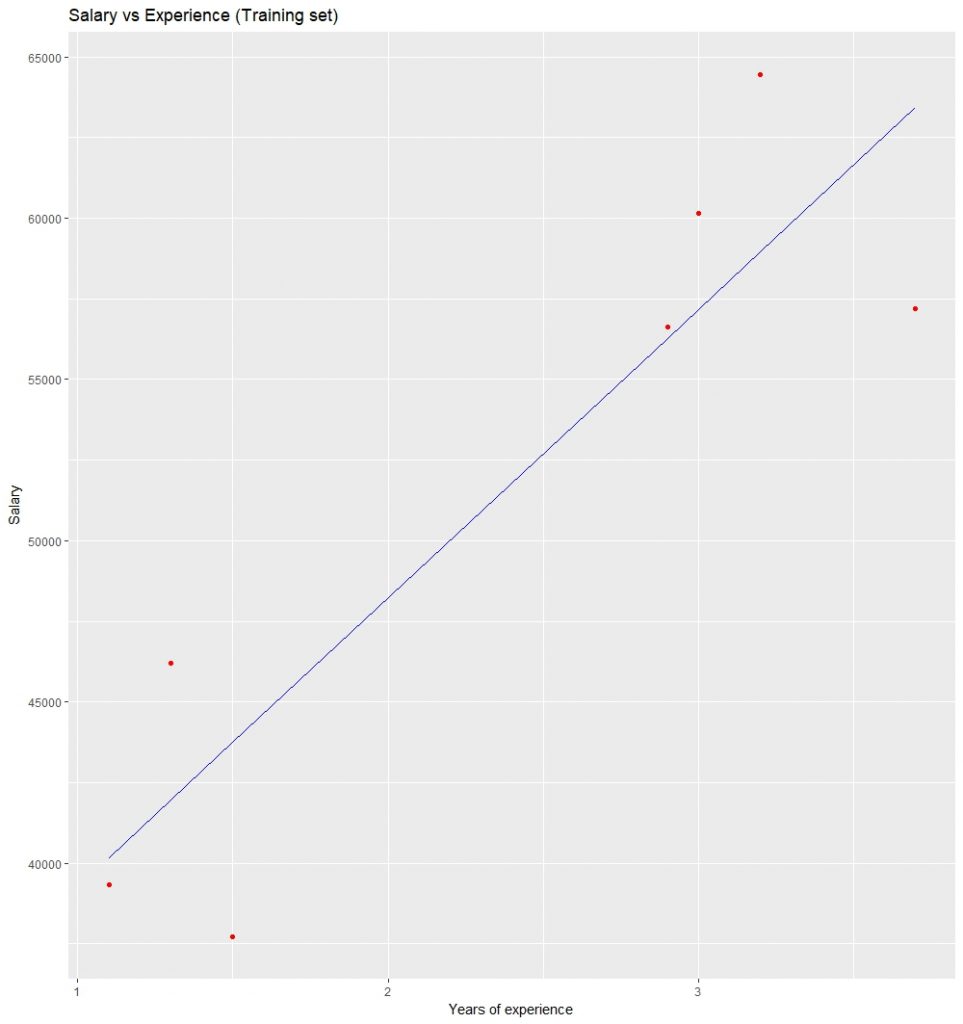
Visualización de los resultados del conjunto de entrenamiento:
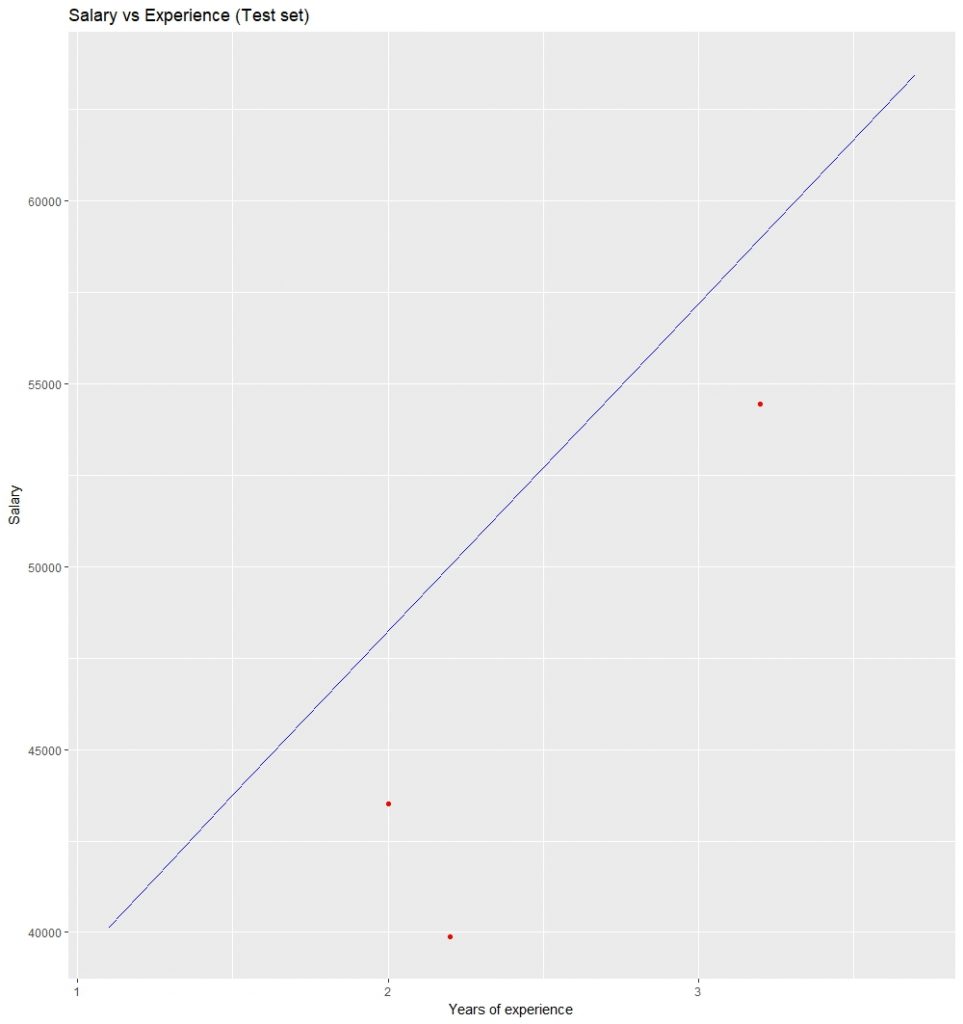
Visualización de los resultados del conjunto de pruebas:
Aprendizaje sin supervisión
R – El aprendizaje no supervisado es el entrenamiento de máquinas que utilizan información que no está clasificada ni etiquetada y que permite que el algoritmo actúe sobre esa información sin guía. En este caso, la tarea de la máquina es agrupar información desordenada según similitudes, patrones y diferencias sin ningún entrenamiento previo de datos. A diferencia del aprendizaje supervisado, no se proporciona ningún maestro, lo que significa que no se dará capacitación a la máquina. Por lo tanto, la máquina está restringida a encontrar la estructura oculta en datos no etiquetados por nosotros mismos. El aprendizaje no supervisado se clasifica en dos categorías de algoritmos:
- Agrupamiento : un problema de agrupamiento es donde desea descubrir los agrupamientos inherentes en los datos, como agrupar clientes por comportamiento de compra.
- Asociación : un problema de aprendizaje de reglas de asociación es donde desea descubrir reglas que describan grandes porciones de sus datos, como que las personas que compran X también tienden a comprar Y.
Tipos
Agrupación:
- Exclusivo (particionamiento)
- aglomerativo
- superposición
- probabilístico
Tipos de agrupamiento:
- Agrupación jerárquica
- Agrupamiento de K-medias
- K-NN (k vecinos más cercanos)
- Análisis de componentes principales
- Valor singular de descomposición
- Análisis de componentes independientes
Implementar en k-means agrupamiento en R
Implementemos uno de los aprendizajes no supervisados muy populares , es decir, el agrupamiento de K-means en la programación R. K significa agrupar R Programar agrupaciones
Sintaxis: kmeans(x, centros = 3, nstart = 10)
Dónde:
- x son datos numéricos
- centres es el número predefinido de grupos
- el algoritmo k-means tiene un componente aleatorio y se puede repetir nstart veces para mejorar el modelo devuelto
R
# Installing Packages
install.packages("ClusterR")
install.packages("cluster")
# Loading package
library(ClusterR)
library(cluster)
# Loading data
data(iris)
# Structure
str(iris)
# Removing initial label of
# Species from original dataset
iris_1 <- iris[, -5]
# Fitting K-Means clustering Model
# to training dataset
set.seed(240) # Setting seed
kmeans.re <- kmeans(iris_1, centers = 3,
nstart = 20)
kmeans.re
# Cluster identification for
# each observation
kmeans.re$cluster
# Confusion Matrix
cm <- table(iris$Species, kmeans.re$cluster)
cm
# Model Evaluation and visualization
plot(iris_1[c("Sepal.Length", "Sepal.Width")])
plot(iris_1[c("Sepal.Length", "Sepal.Width")],
col = kmeans.re$cluster)
plot(iris_1[c("Sepal.Length", "Sepal.Width")],
col = kmeans.re$cluster,
main = "K-means with 3 clusters")
# Plotiing cluster centers
kmeans.re$centers
kmeans.re$centers[, c("Sepal.Length",
"Sepal.Width")]
# cex is font size, pch is symbol
points(kmeans.re$centers[, c("Sepal.Length",
"Sepal.Width")],
col = 1:3, pch = 8, cex = 3)
# Visualizing clusters
y_kmeans <- kmeans.re$cluster
clusplot(iris_1[, c("Sepal.Length", "Sepal.Width")],
y_kmeans,
lines = 0,
shade = TRUE,
color = TRUE,
labels = 2,
plotchar = FALSE,
span = TRUE,
main = paste("Cluster iris"),
xlab = 'Sepal.Length',
ylab = 'Sepal.Width')
Producción:
- Modelo kmeans_re:
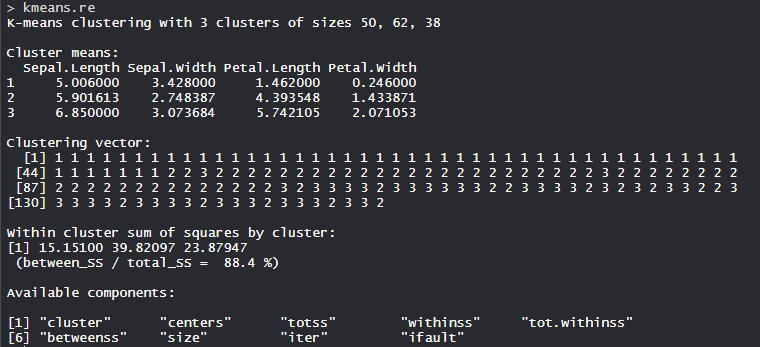
Se fabrican los 3 clusters que son de 50, 62 y 38 tamaños respectivamente. Dentro del clúster, la suma de cuadrados es 88,4%.
- Identificación del conglomerado:
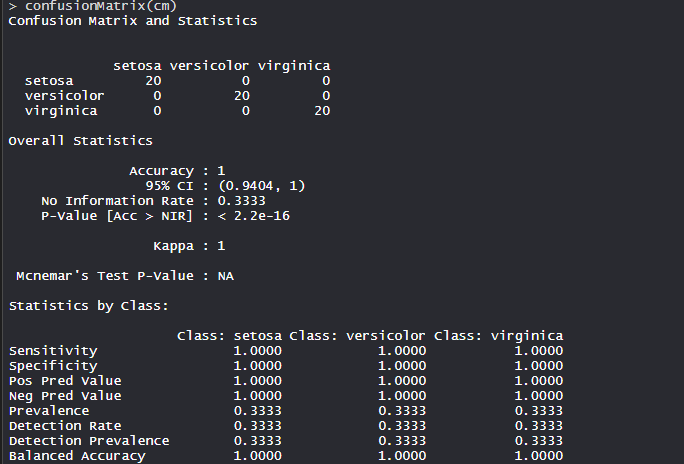
El modelo logró una precisión del 100 % con un valor p inferior a 1. Esto indica que el modelo es bueno.
- Array de confusión:
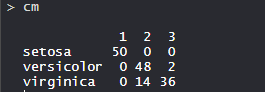
Entonces, 50 Setosa se clasifican correctamente como Setosa. De 62 Versicolor, 48 Versicolor se clasifican correctamente como Versicolor y 14 se clasifican como virginica. De 36 vírgenes, 19 vírgenes se clasifican correctamente como vírgenes y 2 se clasifican como Versicolor.
- K-medias con gráfico de 3 grupos:
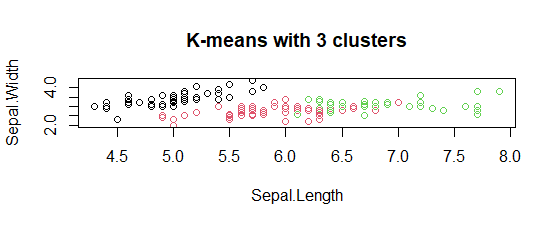
El modelo mostró 3 parcelas de conglomerados con tres colores diferentes y con Sepal.longitud y con Sepal.ancho.
- Trazado de centros de conglomerados:
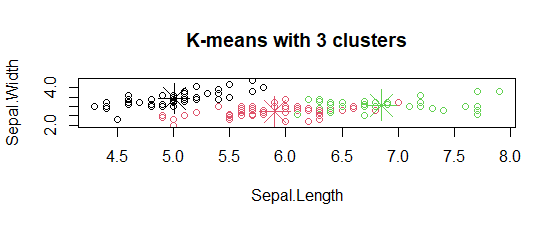
En la parcela, los centros de los conglomerados están marcados con cruces del mismo color del conglomerado.
- Parcela de conglomerados:
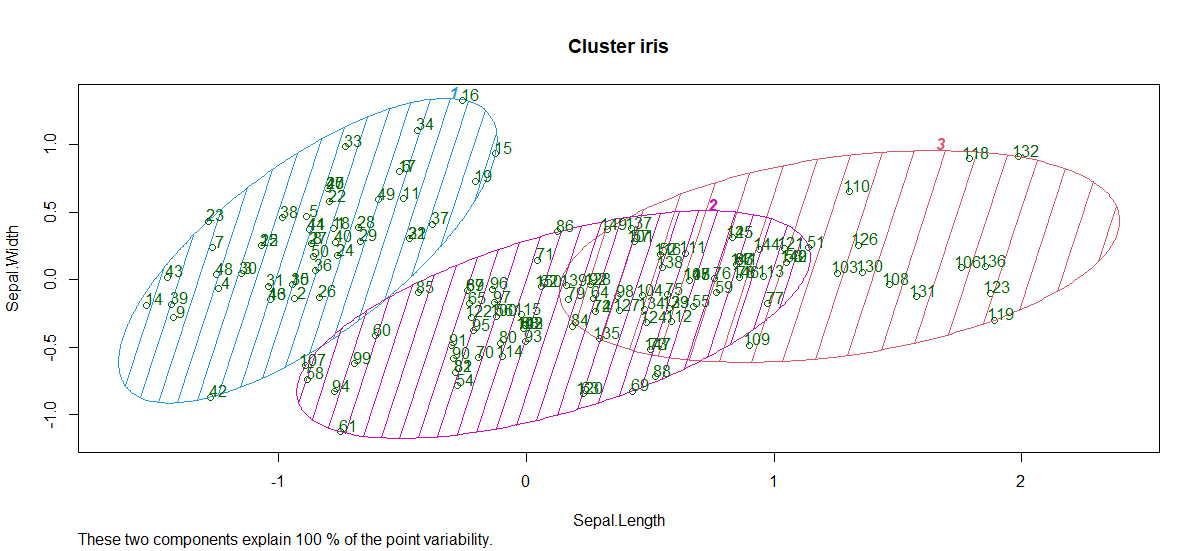
Entonces, se forman 3 grupos con diferentes longitudes y anchos de sépalos.
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA