Inserción en un árbol de búsqueda m-Way:
La inserción en un árbol de búsqueda m-Way es similar a los árboles binarios, pero no debe haber más de m-1 elementos en un Node. Si el Node está lleno, se creará un Node secundario para insertar los elementos adicionales.
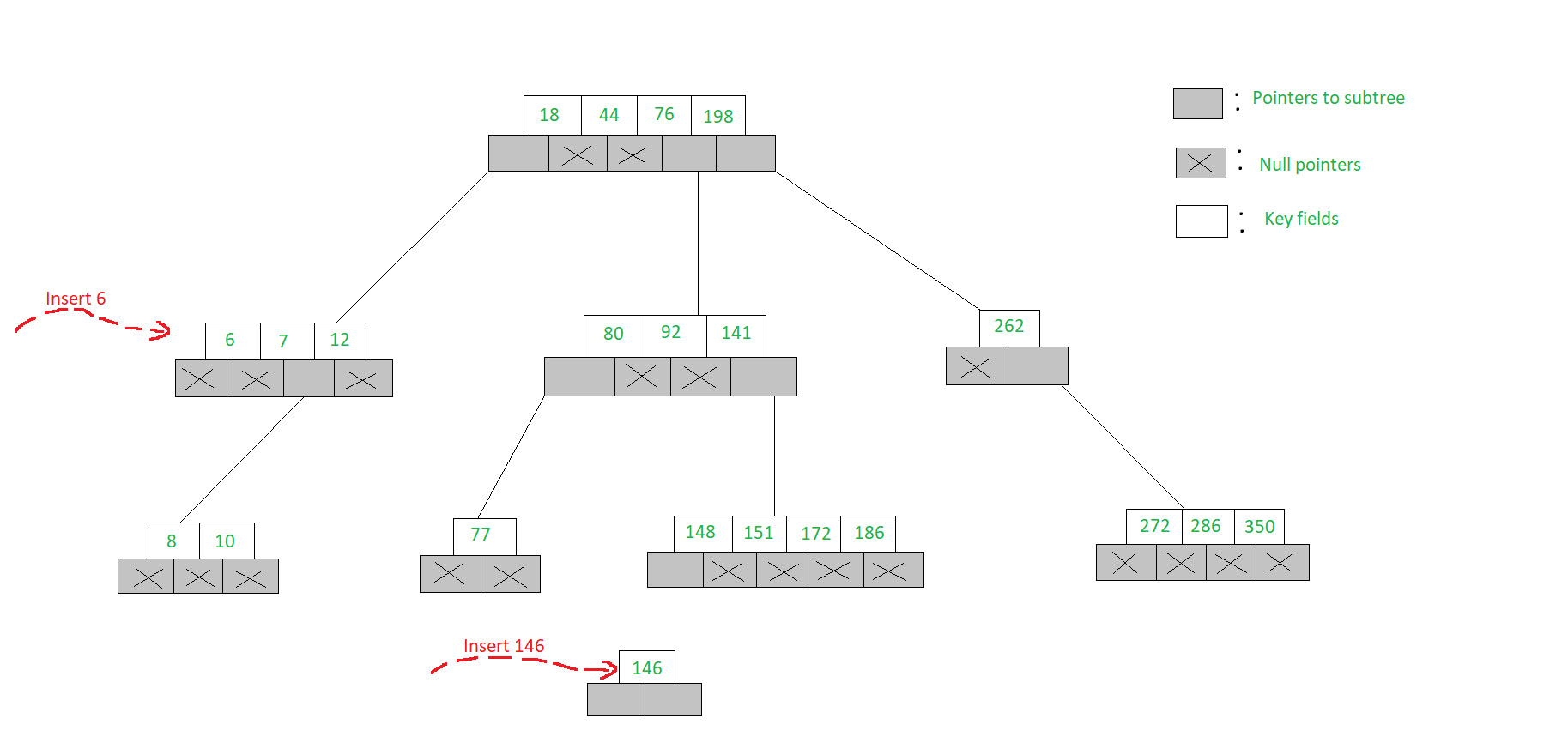
Veamos el ejemplo que se da a continuación para insertar un elemento en un árbol de búsqueda de m-Way.
Ejemplo:
- Para insertar un nuevo elemento en un árbol de búsqueda de m-Way se procede de la misma manera que se haría para buscar el elemento
- Para insertar 6 en el árbol de búsqueda de 5 vías que se muestra en la figura, procedemos a buscar 6 y encontramos que nos caemos del árbol en el Node [7, 12] con el primer Node secundario que muestra un puntero nulo
- Dado que el Node tiene solo dos claves y un árbol de búsqueda de 5 vías puede acomodar hasta 4 claves en un Node, 6 se inserta en el Node como [6, 7, 12]
- Pero para insertar 146, el Node [148, 151, 172, 186] ya está lleno, por lo que abrimos un nuevo Node secundario e insertamos 146 en él. Ambas inserciones se han ilustrado a continuación.
C
// Inserts a value in the m-Way tree
struct node* insert(int val,
struct node* root)
{
int i;
struct node *c, *n;
int flag;
// Function setval() is called which
// returns a value 0 if the new value
// is inserted in the tree, otherwise
// it returns a value 1
flag = setval(val, root, &i, &c);
if (flag) {
n = (struct node*)malloc(sizeof(struct node));
n->count = 1;
n->value[1] = i;
n->child[0] = root;
n->child[1] = c;
return n;
}
return root;
}
C++
// Inserts a value in the m-Way tree
struct node* insert(int val,
struct node* root)
{
int i;
struct node *c, *n;
int flag;
// Function setval() is called which
// returns a value 0 if the new value
// is inserted in the tree, otherwise
// it returns a value 1
flag = setval(val, root, &i, &c);
if (flag) {
n = new node();
n->count = 1;
n->value[1] = i;
n->child[0] = root;
n->child[1] = c;
return n;
}
return root;
}
Java
// Inserts a value in the m-Way tree
public node insert(int val, node root)
{
int i;
node c, n;
int flag;
// Function setval() is called which
// returns a value 0 if the new value
// is inserted in the tree, otherwise
// it returns a value 1
flag = setval(val, root, i, c);
if (flag) {
n = new node();
n.count = 1;
n.value[1] = i;
n.child[0] = root;
n.child[1] = c;
return n;
}
return root;
}
// This code is contributed by Tapesh(tapeshdua420)
Python3
# Inserts a value in the m-Way tree def insert(val, root): # Function setval() is called which # returns a value 0 if the new value # is inserted in the tree, otherwise # it returns a value 1 i,c=0,None flag = setval(val, root, i, c) if (flag) : n = node() n.count = 1 n.value[1] = i n.child[0] = root n.child[1] = c return n return root
C#
// Inserts a value in the m-Way tree
public node insert(int val, node root)
{
int i;
node c, n;
int flag;
// Function setval() is called which returns a value 0
// if the new value is inserted in the tree, otherwise
// it returns a value 1
flag = setval(val, root, i, c);
if (flag) {
n = new node();
n.count = 1;
n.value[1] = i;
n.child[0] = root;
n.child[1] = c;
return n;
}
return root;
}
// This code is contributed by Tapesh(tapeshdua420)
insertar():
- La función insert() recibe dos parámetros: la dirección del nuevo Node y el valor que se inserta
- Esta función llama a una función setval() que devuelve un valor 0 si el nuevo valor se inserta en el árbol, de lo contrario, devuelve un valor 1
- Si devuelve 1 , se asigna memoria para el nuevo Node, se asigna el valor 1 a la variable recuento y se inserta el nuevo valor en el Node.
- Luego, las direcciones de los Nodes secundarios se almacenan en punteros secundarios y, finalmente, se devuelve la dirección del Node.
C++
// Sets the value in the node
int setval(int val,
struct node* n,
int* p,
struct node** c)
{
int k;
// if node is null
if (n == NULL) {
*p = val;
*c = NULL;
return 1;
}
else {
// Checks whether the value to be
// inserted is present or not
if (searchnode(val, n, &k))
cout << "Key value already exists\n";
// The if-else condition checks whether
// the number of nodes is greater or less
// than the maximum number. If it is less
// then it inserts the new value in the
// same level node, otherwise, it splits the
// node and then inserts the value
if (setval(val, n->child[k], p, c)) {
// if the count is less than the max
if (n->count < MAX) {
fillnode(*p, *c, n, k);
return 0;
}
else {
// Insert by splitting
split(*p, *c, n, k, p, c);
return 1;
}
}
return 0;
}
}
C
// Sets the value in the node
int setval(int val,
struct node* n,
int* p,
struct node** c)
{
int k;
// if node is null
if (n == NULL) {
*p = val;
*c = NULL;
return 1;
}
else {
// Checks whether the value to be
// inserted is present or not
if (searchnode(val, n, &k))
printf("Key value already exists\n");
// The if-else condition checks whether
// the number of nodes is greater or less
// than the maximum number. If it is less
// then it inserts the new value in the
// same level node, otherwise, it splits the
// node and then inserts the value
if (setval(val, n->child[k], p, c)) {
// if the count is less than the max
if (n->count < MAX) {
fillnode(*p, *c, n, k);
return 0;
}
else {
// Insert by splitting
split(*p, *c, n, k, p, c);
return 1;
}
}
return 0;
}
}
Java
// Sets the value in the node
public static int setval(int val, node n, int p, node c)
{
int k;
// if node is null
if (n == null) {
p = val;
c = null;
return 1;
}
else {
// Checks whether the value to be
// inserted is present or not
if (searchnode(val, n, k)) {
System.out.println("Key value already exists");
}
// The if-else condition checks whether
// the number of nodes is greater or less
// than the maximum number. If it is less
// then it inserts the new value in the
// same level node, otherwise, it splits the
// node and then inserts the value
if (setval(val, n.child[k], p, c)) {
// if the count is less than the max
if (n.count < MAX) {
fillnode(p, c, n, k);
return 0;
}
else {
// Insert by splitting
split(p, c, n, k, p, c);
return 1;
}
}
return 0;
}
}
// This code is contributed by Tapesh(tapeshdua420)
Python3
# Sets the value in the node
def setval(val, n, p, c):
k=0
# if node is None
if (n == None) :
p = val
c = None
return 1
else :
# Checks whether the value to be
# inserted is present or not
if (searchnode(val, n, k)):
print("Key value already exists")
# The if-else condition checks whether
# the number of nodes is greater or less
# than the maximum number. If it is less
# then it inserts the new value in the
# same level node, otherwise, it splits the
# node and then inserts the value
if (setval(val, n.child[k], p, c)) :
# if the count is less than the max
if (n.count < MAX) :
fillnode(p, c, n, k)
return 0
else :
# Insert by splitting
split(p, c, n, k, p, c)
return 1
return 0
C#
// Sets the value in the node
public static int setval(int val, node n, int p, node c)
{
int k;
// if node is null
if (n == null) {
p = val;
c = null;
return 1;
}
else {
// Checks whether the value to be
// inserted is present or not
if (searchnode(val, n, k)) {
Console.WriteLine("Key value already exists");
}
// The if-else condition checks whether
// the number of nodes is greater or less
// than the maximum number. If it is less
// then it inserts the new value in the
// same level node, otherwise, it splits the
// node and then inserts the value
if (setval(val, n.child[k], p, c)) {
// if the count is less than the max
if (n.count < MAX) {
fillnode(p, c, n, k);
return 0;
}
else {
// Insert by splitting
split(p, c, n, k, p, c);
return 1;
}
}
return 0;
}
}
// This code is contributed by Tapesh(tapeshdua420)
setval():
- La función setval() recibe cuatro parámetros
- El primer argumento es el valor que se va a insertar.
- El segundo argumento es la dirección del Node.
- El tercer argumento es un puntero entero que apunta a una variable de bandera local definida en la función insert()
- El último argumento es un puntero a puntero al Node secundario que se establecerá en una función llamada desde esta función
- La función setval() devuelve un valor de bandera que indica si el valor se inserta o no
- Si el Node está vacío, esta función llama a una función searchnode() que verifica si el valor ya existe en el árbol.
- Si el valor ya existe, se muestra un mensaje adecuado
- Luego se realiza una llamada recursiva a la función setval() para el hijo del Node
- Si esta vez la función devuelve un valor 1, significa que el valor no está insertado
- Luego se verifica una condición si el Node está lleno o no.
- Si el Node no está lleno, se llama a una función fillnode() que completa el valor en el Node, por lo tanto, en este punto se devuelve un valor 0
- Si el Node está lleno, se llama a la función split() que divide el Node existente. En este punto, se devuelve un valor 1 para agregar el valor actual al nuevo Node
C++
// Adjusts the value of the node
void fillnode(int val,
struct node* c,
struct node* n,
int k)
{
int i;
// Shifting the node by one position
for (i = n->count; i > k; i--) {
n->value[i + 1] = n->value[i];
n->child[i + 1] = n->child[i];
}
n->value[k + 1] = val;
n->child[k + 1] = c;
n->count++;
}
C
// Adjusts the value of the node
void fillnode(int val,
struct node* c,
struct node* n,
int k)
{
int i;
// Shifting the node by one position
for (i = n->count; i > k; i--) {
n->value[i + 1] = n->value[i];
n->child[i + 1] = n->child[i];
}
n->value[k + 1] = val;
n->child[k + 1] = c;
n->count++;
}
Python3
# Adjusts the value of the node def fillnode(val, c, n, k): i=0 # Shifting the node by one position for i in range(n.count, k, -1): n.value[i + 1] = n.value[i] n.child[i + 1] = n.child[i] n.value[k + 1] = val n.child[k + 1] = c n.count+=1
llenarNode():
- La función fillnode() recibe cuatro parámetros
- El primero es el valor que se va a insertar.
- El segundo es la dirección del Node secundario del nuevo valor que se va a insertar
- La tercera es la dirección del Node en el que se va a insertar el nuevo valor.
- El último parámetro es la posición del Node donde se insertará el nuevo valor.
C++
// Splits the node
void split(int val,
struct node* c,
struct node* n,
int k, int* y,
struct node** newnode)
{
int i, mid;
if (k <= MIN)
mid = MIN;
else
mid = MIN + 1;
// Allocating the memory for a new node
*newnode = new node();
for (i = mid + 1; i <= MAX; i++) {
(*newnode)->value[i - mid] = n->value[i];
(*newnode)->child[i - mid] = n->child[i];
}
(*newnode)->count = MAX - mid;
n->count = mid;
// it checks whether the new value
// that is to be inserted is inserted
// at a position less than or equal
// to minimum values required in a node
if (k <= MIN)
fillnode(val, c, n, k);
else
fillnode(val, c, *newnode, k - mid);
*y = n->value[n->count];
(*newnode)->child[0] = n->child[n->count];
n->count--;
}
C
// Splits the node
void split(int val,
struct node* c,
struct node* n,
int k, int* y,
struct node** newnode)
{
int i, mid;
if (k <= MIN)
mid = MIN;
else
mid = MIN + 1;
// Allocating the memory for a new node
*newnode = (struct node*)
malloc(sizeof(struct node));
for (i = mid + 1; i <= MAX; i++) {
(*newnode)->value[i - mid] = n->value[i];
(*newnode)->child[i - mid] = n->child[i];
}
(*newnode)->count = MAX - mid;
n->count = mid;
// it checks whether the new value
// that is to be inserted is inserted
// at a position less than or equal
// to minimum values required in a node
if (k <= MIN)
fillnode(val, c, n, k);
else
fillnode(val, c, *newnode, k - mid);
*y = n->value[n->count];
(*newnode)->child[0] = n->child[n->count];
n->count--;
}
Python3
# Splits the node def split(val, c, n, k, y, newnode): i, mid=0,0 if (k <= MIN): mid = MIN else: mid = MIN + 1 # Allocating the memory for a new node newnode = node() for i in range(mid + 1,MAX+1) : newnode.value[i - mid] = n.value[i] newnode.child[i - mid] = n.child[i] newnode.count = MAX - mid n.count = mid # it checks whether the new value # that is to be inserted is inserted # at a position less than or equal # to minimum values required in a node if (k <= MIN): fillnode(val, c, n, k) else: fillnode(val, c, newnode, k - mid) y = n.value[n.count] newnode.child[0] = n.child[n.count] n.count-=1
separar():
- La función split() recibe seis parámetros
- Los primeros cuatro parámetros son exactamente los mismos que en el caso de la función fillnode()
- El quinto parámetro es un puntero a la variable que contiene el valor desde donde se divide el Node.
- El último parámetro es un puntero a puntero del nuevo Node creado en el momento de la división
- En esta función en primer lugar se comprueba si el nuevo valor que se va a insertar se inserta en una posición menor o igual a los valores mínimos requeridos en un Node
- Si se cumple la condición, el Node se divide en la posición MIN
- De lo contrario, el Node se divide en una posición más que MIN
- Luego, la memoria se asigna dinámicamente para un nuevo Node.
- A continuación, se ejecuta un bucle for que copia en el nuevo Node los valores y los elementos secundarios que se encuentran en el lado derecho del valor desde donde se divide el Node.
Eliminación en un árbol de búsqueda m-Way:
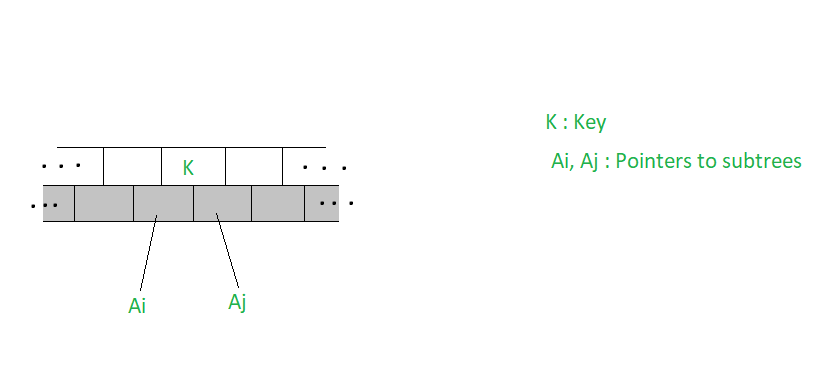
Sea K una clave a eliminar del árbol de búsqueda de m-Way. Para borrar la clave se procede como se haría para buscar la clave. Deje que el Node que acomoda la clave sea como se ilustra a continuación.
Enfoque:
Hay varios casos para la eliminación
- Si (A i = A j = NULL) entonces elimine K
- Si (A i != NULL, A j = NULL) elija el mayor de los elementos clave K’ en el Node secundario señalado por A i , elimine la clave K’ y reemplace K por K’
- Obviamente, la eliminación de K’ puede requerir reemplazos posteriores y, por lo tanto, eliminaciones de manera similar, para permitir que la clave K’ suba en el árbol.
- Si (A i = NULL, A j != NULL) , elija el elemento clave K” más pequeño del subárbol señalado por A j , elimine K” y reemplace K por K”
- Nuevamente, la eliminación de K” puede desenstringr reemplazos y eliminaciones posteriores para permitir que K” suba en el árbol
- Si (A i !=NULL, A j != NULL) elija el mayor de los elementos clave K’ del subárbol señalado por A i , o el menor de los elementos clave K” del subárbol señalado por A j para reemplazar K
- Como se mencionó anteriormente, para mover K’ o K” hacia arriba en el árbol puede requerir reemplazos y eliminaciones posteriores.
Ejemplo:
- Para eliminar 151, buscamos 151 y observamos que en el Node hoja [148, 151, 172, 186] donde está presente, tanto su puntero de subárbol izquierdo como su puntero de subárbol derecho son tales que (A i = A j = NULO)
- Por lo tanto, simplemente eliminamos 151 y el Node se convierte en [148, 172, 186]. La eliminación de 92 también sigue un proceso similar
- Para eliminar 262, encontramos que sus punteros de subárbol izquierdo y derecho A i</sub y Aj respectivamente, son tales que (Ai = Aj = NULL)
- Por lo tanto, elegimos el elemento más pequeño 272 del Node secundario [272, 286, 350], eliminamos 272 y reemplazamos 262 con 272. Tenga en cuenta que, para eliminar 272, el procedimiento de eliminación debe observarse nuevamente
- Para eliminar 12, encontramos que el Node [7, 12] acomoda 12 y la clave satisface (A i != NULL, A j = NULL)
- Por lo tanto, elegimos la mayor de las claves del Node señalado por Ai, a saber, 10 y reemplazamos 12 con 10. Esta eliminación se ilustra a continuación.
C++
// Deletes value from the node
struct node* del(int val,
struct node* root)
{
struct node* temp;
if (!delhelp(val, root)) {
cout << '\n';
cout << "value %d not found.\n";
}
else {
if (root->count == 0) {
temp = root;
root = root->child[0];
free(temp);
}
}
return root;
}
C
// Deletes value from the node
struct node* del(int val,
struct node* root)
{
struct node* temp;
if (!delhelp(val, root)) {
printf("\n");
printf("value %d not found.\n", val);
}
else {
if (root->count == 0) {
temp = root;
root = root->child[0];
free(temp);
}
}
return root;
}
Python3
# Deletes value from the node
def delete(val, root):
temp=None
if (not delhelp(val, root)) :
print()
print("value not found.")
else :
if (root.count == 0) :
temp = root
root = root.child[0]
return root
del():
- La función del() recibe dos parámetros. El primero es el valor que se va a eliminar, el segundo es la dirección del Node raíz.
- Esta función llama a otra función auxiliar delhelp() que devuelve el valor 0 si la eliminación del valor no se realiza correctamente, 1 de lo contrario
- De lo contrario, se verifica una condición si el conteo es 0
- Si es así, indica que el Node del que se elimina el valor es el último valor
- Por lo tanto, el primer hijo del Node se convierte en Node y el Node original se elimina. Finalmente, se devuelve la dirección del nuevo Node raíz.
C++
// Helper function for del()
int delhelp(int val,
struct node* root)
{
int i;
int flag;
if (root == NULL)
return 0;
else {
// Again searches for the node
flag = searchnode(val,
root,
&i);
// if flag is true
if (flag) {
if (root->child[i - 1]) {
copysucc(root, i);
// delhelp() is called recursively
flag = delhelp(root->value[i],
root->child[i])
if (!flag)
{
cout << "\n";
cout << "value %d not found.\n";
}
}
else
clear(root, i);
}
else {
// Recursion
flag = delhelp(val, root->child[i]);
}
if (root->child[i] != NULL) {
if (root->child[i]->count < MIN)
restore(root, i);
}
return flag;
}
}
C
// Helper function for del()
int delhelp(int val,
struct node* root)
{
int i;
int flag;
if (root == NULL)
return 0;
else {
// Again searches for the node
flag = searchnode(val,
root,
&i);
// if flag is true
if (flag) {
if (root->child[i - 1]) {
copysucc(root, i);
// delhelp() is called recursively
flag = delhelp(root->value[i],
root->child[i])
if (!flag)
{
printf("\n");
printf("value %d not found.\n", val);
}
}
else
clear(root, i);
}
else {
// Recursion
flag = delhelp(val, root->child[i]);
}
if (root->child[i] != NULL) {
if (root->child[i]->count < MIN)
restore(root, i);
}
return flag;
}
}
Python3
# Helper function for del()
def delhelp(val, root):
i,flag=None,None
if (root == None):
return 0
else :
# Again searches for the node
flag = searchnode(val,root,i)
# if flag is true
if (flag) :
if (root.child[i - 1]) :
copysucc(root, i)
# delhelp() is called recursively
flag = delhelp(root.value[i],
root.child[i])
if (not flag):
print()
print("value not found.")
else:
clear(root, i)
else :
# Recursion
flag = delhelp(val, root.child[i])
if (root.child[i] != None) :
if (root.child[i].count < MIN):
restore(root, i)
return flag
delhelp():
- La función delhelp() recibe dos parámetros. El primero es el valor que se eliminará y el segundo es la dirección del Node del que se eliminará.
- Inicialmente se comprueba si el Node es NULL
- Si es así, se devuelve un valor 0
- De lo contrario, se realiza una llamada a la función searchnode()
- Si se encuentra el valor, se verifica otra condición para ver si hay algún hijo del valor que se va a eliminar.
- Si es así, se llama a la función copysucc() que copia el sucesor del valor que se va a eliminar y luego se realiza una llamada recursiva a la función delhelp() para el valor que se va a eliminar y su hijo .
- Si el elemento secundario está vacío, se realiza una llamada a la función clear() que elimina el valor
- Si la función searchnode() falla, se realiza una llamada recursiva a la función delhelp() pasando la dirección del hijo
- Si el elemento secundario del Node no está vacío, se llama a la función restore() para fusionar el elemento secundario con sus hermanos .
- Finalmente, se devuelve el valor de la bandera , que se establece como un valor devuelto de la función searchnode()
C++
// Removes the value from the
// node and adjusts the values
void clear(struct node* m, int k)
{
int i;
for (i = k + 1; i <= m->count; i++) {
m->value[i - 1] = m->value[i];
m->child[i - 1] = m->child[i];
}
m->count--;
}
C
// Removes the value from the
// node and adjusts the values
void clear(struct node* m, int k)
{
int i;
for (i = k + 1; i <= m->count; i++) {
m->value[i - 1] = m->value[i];
m->child[i - 1] = m->child[i];
}
m->count--;
}
Python3
# Removes the value from the # node and adjusts the values def clear(m, k): for i in range(k + 1,m.count+1) : m.value[i - 1] = m.value[i] m.child[i - 1] = m.child[i] m.count-=1
clear():
- La función clear() recibe dos parámetros. El primero es la dirección del Node del que se eliminará el valor y el segundo es la posición del valor que se eliminará.
- Esta función simplemente cambia los valores un lugar a la izquierda desde la posición donde está presente el valor que se va a eliminar.
C++
// Copies the successor of the
// value that is to be deleted
void copysucc(struct node* m, int i)
{
struct node* temp;
temp = p->child[i];
while (temp->child[0])
temp = temp->child[0];
p->value[i] = temp->value[i];
}
C
// Copies the successor of the
// value that is to be deleted
void copysucc(struct node* m, int i)
{
struct node* temp;
temp = p->child[i];
while (temp->child[0])
temp = temp->child[0];
p->value[i] = temp->value[i];
}
Python3
# Copies the successor of the # value that is to be deleted def copysucc(m, i): temp = p.child[i] while (temp.child[0]): temp = temp.child[0] p.value[i] = temp.value[i]
copiasucc()
- La función copysucc() recibe dos parámetros. La primera es la dirección del Node donde se copiará el sucesor y la segunda es la posición del valor que se sobrescribirá con su sucesor.
C++
// Adjusts the node
void restore(struct node* m, int i)
{
if (i == 0) {
if (m->child[1]->count > MIN)
leftshift(m, 1);
else
merge(m, 1);
}
else {
if (i == m->count) {
if (m->child[i - 1]->count > MIN)
rightshift(m, i);
else
merge(m, i);
}
else {
if (m->child[i - 1]->count > MIN)
rightshift(m, i);
else {
if (m->child[i + 1]->count > MIN)
leftshift(m, i + 1);
else
merge(m, i);
}
}
}
}
C
// Adjusts the node
void restore(struct node* m, int i)
{
if (i == 0) {
if (m->child[1]->count > MIN)
leftshift(m, 1);
else
merge(m, 1);
}
else {
if (i == m->count) {
if (m->child[i - 1]->count > MIN)
rightshift(m, i);
else
merge(m, i);
}
else {
if (m->child[i - 1]->count > MIN)
rightshift(m, i);
else {
if (m->child[i + 1]->count > MIN)
leftshift(m, i + 1);
else
merge(m, i);
}
}
}
}
Python3
# Adjusts the node def restore(m, i): if (i == 0): if (m.child[1].count > MIN): leftshift(m, 1) else: merge(m, 1) else : if (i == m.count) : if (m.child[i - 1].count > MIN): rightshift(m, i) else: merge(m, i) else : if (m.child[i - 1].count > MIN): rightshift(m, i) else : if (m.child[i + 1].count > MIN): leftshift(m, i + 1) else: merge(m, i)
restaurar():
- La función restaurar() recibe dos parámetros. El primero es el Node que se va a restaurar y el segundo es la posición del valor desde donde se restauran los valores.
- Si el segundo parámetro es 0, entonces se verifica otra condición para averiguar si los valores presentes en el primer hijo son más que el número mínimo requerido de valores
- Si es así, se llama a la función leftshift() pasando la dirección del Node y un valor 1, lo que significa que el valor de este Node se desplazará desde el primer valor.
- Si la condición no se cumple, se llama a la función merge() para fusionar los dos elementos secundarios del Node .
C++
// Adjusts the values and children
// while shifting the value from
// parent to right child
void rightshift(struct node* m, int k)
{
int i;
struct node* temp;
temp = m->child[k];
// Copying the nodes
for (i = temp->count; i > 0; i--) {
temp->value[i + 1] = temp->value[i];
temp->child[i + 1] = temp->child[i];
}
temp->child[1] = temp->child[0];
temp->count++;
temp->value[1] = m->value[k];
temp = m->child[k - 1];
m->value[k] = temp->value[temp->count];
m->child[k]->child[0]
= temp->child[temp->count];
temp->count--;
}
// Adjusts the values and children
// while shifting the value from
// parent to left child
void leftshift(struct node* m, int k)
{
int i;
struct node* temp;
temp = m->child[k - 1];
temp->count++;
temp->value[temp->count] = m->value[k];
temp->child[temp->count]
= m->child[k]->child[0];
temp = m->child[k];
m->value[k] = temp->value[1];
temp->child[0] = temp->child[1];
temp->count--;
for (i = 1; i <= temp->count; i++) {
temp->value[i] = temp->value[i + 1];
temp->child[i] = temp->child[i + 1];
}
}
C
// Adjusts the values and children
// while shifting the value from
// parent to right child
void rightshift(struct node* m, int k)
{
int i;
struct node* temp;
temp = m->child[k];
// Copying the nodes
for (i = temp->count; i > 0; i--) {
temp->value[i + 1] = temp->value[i];
temp->child[i + 1] = temp->child[i];
}
temp->child[1] = temp->child[0];
temp->count++;
temp->value[1] = m->value[k];
temp = m->child[k - 1];
m->value[k] = temp->value[temp->count];
m->child[k]->child[0]
= temp->child[temp->count];
temp->count--;
}
// Adjusts the values and children
// while shifting the value from
// parent to left child
void leftshift(struct node* m, int k)
{
int i;
struct node* temp;
temp = m->child[k - 1];
temp->count++;
temp->value[temp->count] = m->value[k];
temp->child[temp->count]
= m->child[k]->child[0];
temp = m->child[k];
m->value[k] = temp->value[1];
temp->child[0] = temp->child[1];
temp->count--;
for (i = 1; i <= temp->count; i++) {
temp->value[i] = temp->value[i + 1];
temp->child[i] = temp->child[i + 1];
}
}
Python3
# Adjusts the values and children # while shifting the value from # parent to right child def rightshift(m, k): temp = m.child[k] # Copying the nodes for i in range(temp.count,0,-1) : temp.value[i + 1] = temp.value[i] temp.child[i + 1] = temp.child[i] temp.child[1] = temp.child[0] temp.count+=1 temp.value[1] = m.value[k] temp = m.child[k - 1] m.value[k] = temp.value[temp.count] m.child[k].child[0] = temp.child[temp.count] temp.count-=1 # Adjusts the values and children # while shifting the value from # parent to left child def leftshift(m, k): temp = m.child[k - 1] temp.count+=1 temp.value[temp.count] = m.value[k] temp.child[temp.count] = m.child[k].child[0] temp = m.child[k] m.value[k] = temp.value[1] temp.child[0] = temp.child[1] temp.count-=1 for i in range(1, temp.count+1): temp.value[i] = temp.value[i + 1] temp.child[i] = temp.child[i + 1]
desplazamiento a la derecha() y desplazamiento a la izquierda()
- La función rightshift() recibe dos parámetros
- La primera es la dirección del Node desde donde se cambia el valor a su hijo y la segunda es la posición k del valor que se va a cambiar.
- La función leftshift() es exactamente igual que la función rightshift()
- La función merge() recibe dos parámetros. La primera es la dirección del Node desde el cual se copiará el valor al elemento secundario y la segunda es la posición del valor.
C++
// Merges two nodes
void merge(struct node* m, int k)
{
int i;
struct node *temp1, *temp2;
temp1 = m->child[k];
temp2 = m->child[k - 1];
temp2->count++;
temp2->value[temp2->count] = m->value[k];
temp2->child[temp2->count] = m->child[0];
for (i = 0; i <= temp1->count; i++) {
temp2->count++;
temp2->value[temp2->count] = temp1->value[i];
temp2->child[temp2->count] = temp1->child[i];
}
for (i = k; i < m->count; i++) {
m->value[i] = m->value[i + 1];
m->child[i] = m->child[i + 1];
}
m->count--;
free(temp1);
}
C
// Merges two nodes
void merge(struct node* m, int k)
{
int i;
struct node *temp1, *temp2;
temp1 = m->child[k];
temp2 = m->child[k - 1];
temp2->count++;
temp2->value[temp2->count] = m->value[k];
temp2->child[temp2->count] = m->child[0];
for (i = 0; i <= temp1->count; i++) {
temp2->count++;
temp2->value[temp2->count] = temp1->value[i];
temp2->child[temp2->count] = temp1->child[i];
}
for (i = k; i < m->count; i++) {
m->value[i] = m->value[i + 1];
m->child[i] = m->child[i + 1];
}
m->count--;
free(temp1);
}
Python3
# Merges two nodes def merge(m, k): temp1 = m.child[k] temp2 = m.child[k - 1] temp2.count+=1 temp2.value[temp2.count] = m.value[k] temp2.child[temp2.count] = m.child[0] for i in range(temp1.count+1): temp2.count+=1 temp2.value[temp2.count] = temp1.value[i] temp2.child[temp2.count] = temp1.child[i] for i in range(k,m.count): m.value[i] = m.value[i + 1] m.child[i] = m.child[i + 1] m.count-=1
Java
void merge(Node m, int k)
{
int i;
Node temp1, temp2;
temp1 = m.child[k];
temp2 = m.child[k - 1];
temp2.count++;
temp2.value[temp2.count] = m.value[k];
temp2.child[temp2.count] = m.child[0];
for (i = 0; i <= temp1.count; i++) {
temp2.count++;
temp2.value[temp2.count] = temp1.value[i];
temp2.child[temp2.count] = temp1.child[i];
}
for (i = k; i < m.count; i++) {
m.value[i] = m.value[i + 1];
m.child[i] = m.child[i + 1];
}
m.count--;
}
- La función merge() recibe dos parámetros
- La primera es la dirección del Node desde el cual se copiará el valor al elemento secundario y la segunda es la posición del valor.
- En esta función, se definen dos variables temporales temp1 y temp2 para contener las direcciones de los dos hijos del valor que se va a copiar.
- Inicialmente, el valor del Node se copia a su hijo. Luego, el primer hijo del Node se convierte en el hijo respectivo del Node donde se copia el valor
- Luego se ejecutan dos bucles for, de los cuales primero se copian todos los valores y los elementos secundarios de un elemento secundario al otro elemento secundario.
- El segundo bucle cambia el valor y el hijo del Node desde donde se copia el valor
- Luego se decrementa el conteo del Node desde donde se copia el Node. Finalmente, la memoria ocupada por el segundo Node se libera llamando a free()
Publicación traducida automáticamente
Artículo escrito por Shubhadarshie y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA