Los árboles de decisión son útiles algoritmos de aprendizaje automático supervisado que tienen la capacidad de realizar tareas de regresión y clasificación. Se caracteriza por Nodes y ramas, donde las pruebas de cada atributo se representan en los Nodes, el resultado de este procedimiento se representa en las ramas y las etiquetas de clase se representan en los Nodes hoja. Por lo tanto, utiliza un modelo similar a un árbol basado en varias decisiones que se utilizan para calcular sus resultados probables. Estos tipos de algoritmos basados en árboles son uno de los algoritmos más utilizados debido a que estos algoritmos son fáciles de interpretar y usar. Aparte de esto, los modelos predictivos desarrollados por este algoritmo tienen una buena estabilidad y una precisión decente, por lo que son muy populares.
Tipos de árboles de decisión
- Tocón de decisión: se utiliza para generar un árbol de decisión con una sola división, por lo que también se conoce como árbol de decisión de un nivel. Es conocido por su bajo rendimiento predictivo en la mayoría de los casos debido a su simplicidad.
- M5: Conocido por su precisión de clasificación precisa y su capacidad para funcionar bien en un árbol de decisiones potenciado y pequeños conjuntos de datos con demasiado ruido.
- ID3 (Dichroatiser iterativo 3): uno de los algoritmos de árbol de decisión centrales y ampliamente utilizados utiliza un enfoque de búsqueda codicioso de arriba hacia abajo a través del conjunto de datos dado y selecciona el mejor atributo para clasificar el conjunto de datos dado
- C4.5: También conocido como clasificador estadístico, este tipo de árbol de decisión se deriva de su padre ID3. Esto genera decisiones basadas en un montón de predictores.
- C5.0: al ser el sucesor del C4.5, en términos generales tiene dos modelos, a saber, el árbol básico y el modelo basado en reglas, y sus Nodes solo pueden predecir objetivos categóricos.
- CHAID: ampliado como detector automático de interacción de chi-cuadrado, este algoritmo básicamente estudia las variables fusionadas para justificar el resultado de la variable dependiente mediante la estructuración de un modelo predictivo
- MARS: Expandido como splines de regresión adaptativa multivariante, este algoritmo crea una serie de modelos lineales por partes que se utilizan para modelar irregularidades e interacciones entre variables, son conocidos por su capacidad para manejar datos numéricos con mayor eficiencia.
- Árboles de inferencia condicional: este es un tipo de árbol de decisión que utiliza un marco de inferencia condicional para segregar recursivamente las variables de respuesta, es conocido por su flexibilidad y sus bases sólidas.
- CARRITO: Expandido como Árboles de Clasificación y Regresión, se predicen los valores de las variables objetivo si son continuas o se identifican las clases necesarias si son categóricas.
Como se puede ver, hay muchos tipos de árboles de decisión, pero se dividen en dos categorías principales según el tipo de variable objetivo, que son:
- Árbol de decisión de variables categóricas: se refiere a los árboles de decisión cuyas variables objetivo tienen un valor limitado y pertenecen a un grupo en particular.
- Árbol de decisión de variable continua: se refiere a los árboles de decisión cuyas variables de destino pueden tomar valores de una amplia gama de tipos de datos.
Árbol de decisión en lenguaje de programación R
Consideremos el escenario en el que una empresa médica quiere predecir si una persona morirá si se expone al virus. El factor importante que determina este resultado es la fortaleza de su sistema inmunológico, pero la compañía no tiene esta información. Dado que esta es una variable importante, se puede construir un árbol de decisión para predecir la fuerza inmunológica en función de factores como los ciclos de sueño, los niveles de cortisol, la ingesta de suplementos, los nutrientes derivados de la ingesta de alimentos, etc. de la persona, que son todas variables continuas.
Funcionamiento de un árbol de decisión en R
- Particionamiento: se refiere al proceso de dividir el conjunto de datos en subconjuntos. La decisión de hacer divisiones estratégicas afecta en gran medida la precisión del árbol. El árbol utiliza muchos algoritmos para dividir un Node en subNodes, lo que da como resultado un aumento general en la claridad del Node con respecto a la variable de destino. Se utilizan varios algoritmos como el chi-cuadrado y el índice de Gini para este propósito y se elige el algoritmo con la mejor eficiencia.
- Poda: se refiere al proceso en el que los Nodes de las ramas se convierten en Nodes de hojas, lo que da como resultado el acortamiento de las ramas del árbol. La esencia detrás de esta idea es que los árboles más simples evitan el sobreajuste, ya que los árboles de clasificación más complejos pueden ajustarse bien a los datos de entrenamiento, pero hacen un trabajo decepcionante al clasificar nuevos valores.
- Selección del árbol: El objetivo principal de este proceso es seleccionar el árbol más pequeño que se ajuste a los datos por las razones discutidas en la sección de poda.
Factores importantes a considerar al seleccionar el árbol en R
- Entropía:
Se utiliza principalmente para determinar la uniformidad en la muestra dada. Si la muestra es completamente uniforme, la entropía es 0, si está dividida uniformemente, es uno. Cuanto mayor es la entropía, más difícil se vuelve sacar conclusiones de esa información. - Ganancia de información:
propiedad estadística que mide qué tan bien se separan los ejemplos de entrenamiento en función de la clasificación objetivo. La idea principal detrás de la construcción de un árbol de decisión es encontrar un atributo que devuelva la entropía más pequeña y la ganancia de información más alta. Es básicamente una medida de la disminución de la entropía total, y se calcula calculando la diferencia total entre la entropía antes de la división y la entropía promedio después de la división del conjunto de datos en función de los valores de atributos dados.
R – Ejemplo de árbol de decisión
Examinemos ahora este concepto con la ayuda de un ejemplo, que en este caso es el conjunto de datos de «habilidades de lectura» más utilizado, visualizando un árbol de decisión para él y examinando su precisión.
Importe las bibliotecas requeridas y cargue el conjunto de datos readSkills y ejecute head (readingSkills)
R
library(datasets)
library(caTools)
library(party)
library(dplyr)
library(magrittr)
data("readingSkills")
head(readingSkills)
Producción:
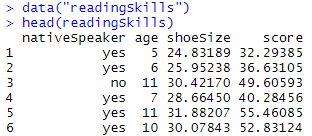
Como puede ver claramente, hay 4 columnas nativeSpeaker, age, shoeSize y score. Por lo tanto, básicamente vamos a averiguar si una persona es hablante nativo o no utilizando los otros criterios y ver la precisión del modelo de árbol de decisión desarrollado al hacerlo.
Dividir el conjunto de datos en una proporción de 4:1 para entrenar y probar datos
R
sample_data = sample.split(readingSkills, SplitRatio = 0.8) train_data <- subset(readingSkills, sample_data == TRUE) test_data <- subset(readingSkills, sample_data == FALSE)
Separar los datos en conjuntos de entrenamiento y prueba es una parte importante de la evaluación de los modelos de minería de datos. Por lo tanto, se separa en conjuntos de entrenamiento y prueba. Una vez que se ha procesado un modelo mediante el uso del conjunto de entrenamiento, prueba el modelo haciendo predicciones contra el conjunto de prueba. Debido a que los datos en el conjunto de prueba ya contienen valores conocidos para el atributo que desea predecir, es fácil determinar si las conjeturas del modelo son correctas.
Cree el modelo de árbol de decisión usando ctree y trace el modelo
R
model<- ctree(nativeSpeaker ~ ., train_data) plot(model)
La sintaxis básica para crear un árbol de decisión en R es:
ctree(formula, data)
donde , la fórmula describe las variables predictoras y de respuesta y data es el conjunto de datos utilizado. En este caso, nativeSpeaker es la variable de respuesta y las otras variables predictoras están representadas por, por lo tanto, cuando trazamos el modelo, obtenemos el siguiente resultado.
Producción:
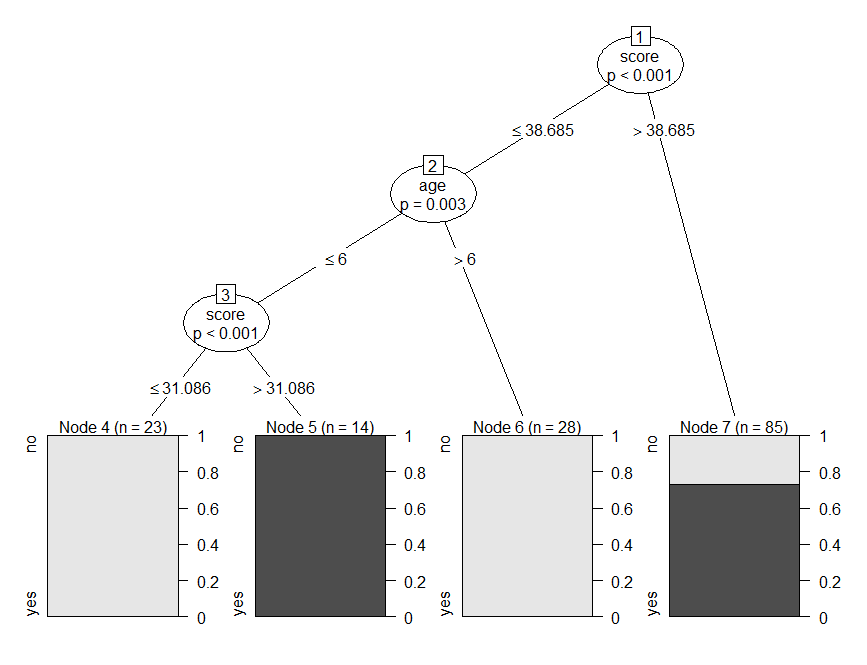
Del árbol se desprende que aquellos que tienen una puntuación menor o igual a 31,08 y cuya edad es menor o igual a 6 no son hablantes nativos y para aquellos cuya puntuación es mayor a 31,086 bajo el mismo criterio, se encuentran ser hablantes nativos.
Haciendo una predicción
R
# testing the people who are native speakers # and those who are not predict_model<-predict(ctree_, test_data) # creates a table to count how many are classified # as native speakers and how many are not m_at <- table(test_data$nativeSpeaker, predict_model) m_at
Producción
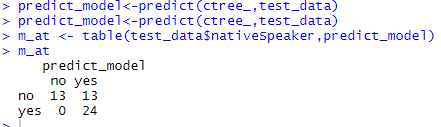
El modelo predijo correctamente que 13 personas no serían hablantes nativos, pero clasificó a 13 adicionales como no nativos, y el modelo, por analogía, no clasificó erróneamente a ninguno de los pasajeros como hablantes nativos cuando en realidad no lo son.
Determinación de la precisión del modelo desarrollado
R
ac_Test < - sum(diag(table_mat)) / sum(table_mat)
print(paste('Accuracy for test is found to be', ac_Test))
Producción:

Aquí se calcula la prueba de precisión de la array de confusión y se encuentra que es 0,74. Por lo tanto, se encuentra que este modelo predice con una precisión del 74 %.
Inferencia
Por lo tanto, los árboles de decisión son algoritmos muy útiles, ya que no solo se utilizan para elegir alternativas en función de los valores esperados, sino que también se utilizan para la clasificación de prioridades y la realización de predicciones. Depende de nosotros determinar la precisión del uso de dichos modelos en las aplicaciones apropiadas.
Ventajas de los árboles de decisión
- Fácil de entender e interpretar.
- No requiere normalización de datos
- No facilita la necesidad de escalar los datos.
- La etapa de preprocesamiento requiere menos esfuerzo en comparación con otros algoritmos principales, por lo tanto, de alguna manera optimiza el problema dado.
Desventajas de los árboles de decisión
- Requiere más tiempo para entrenar el modelo.
- Tiene una complejidad considerable y requiere más tiempo para procesar los datos.
- Cuando la disminución en el parámetro de entrada del usuario es muy pequeña, conduce a la terminación del árbol.
- Los cálculos pueden volverse muy complejos a veces