Los árboles genéricos son una colección de Nodes donde cada Node es una estructura de datos que consta de registros y una lista de referencias a sus hijos (no se permiten referencias duplicadas). A diferencia de la lista enlazada, cada Node almacena la dirección de varios Nodes. Cada Node almacena la dirección de sus hijos y la dirección del primer Node se almacenará en un puntero separado llamado raíz.
Los árboles Genéricos son los árboles N-arios que tienen las siguientes propiedades:
1. Muchos niños en cada Node.
2. El número de Nodes para cada Node no se conoce de antemano.
Ejemplo:
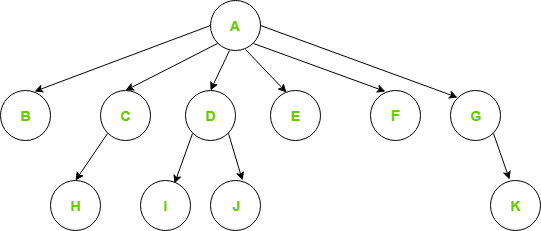
Árbol Genérico
Para representar el árbol anterior, tenemos que considerar el peor de los casos, que es el Node con un máximo de hijos (en el ejemplo anterior, 6 hijos) y asignar esa cantidad de punteros para cada Node.
La representación del Node basada en este método se puede escribir como:
C
//Node declaration
struct Node{
int data;
struct Node *firstchild;
struct Node *secondchild;
struct Node *thirdchild;
struct Node *fourthchild;
struct Node *fifthchild;
struct Node *sixthchild;
}
Las desventajas de la representación anterior son:
- Desperdicio de memoria : no se requieren todos los punteros en todos los casos. Por lo tanto, hay mucho desperdicio de memoria.
- Número desconocido de hijos : el número de hijos de cada Node no se conoce de antemano.
Enfoque sencillo:
Para almacenar la dirección de los niños en un Node, podemos usar una array o una lista enlazada. Pero nos enfrentaremos a algunos problemas con ambos.
- En la lista Vinculada , no podemos acceder aleatoriamente a la dirección de ningún niño. Así que será caro.
- En array , podemos acceder aleatoriamente a la dirección de cualquier niño, pero solo podemos almacenar un número fijo de direcciones de niños en él.
Mejor enfoque:
Podemos usar arrays dinámicas para almacenar la dirección de la dirección de los niños. Podemos acceder aleatoriamente a la dirección de cualquier niño y el tamaño del vector tampoco es fijo.
C
//Node declaration
struct Node{
int data;
vector<Node*> children;
}
Enfoque eficiente:
Representación del primer hijo/próximo hermano
En la representación del primer hijo/próximo hermano, los pasos que se siguen son:
En cada Node, vincula a los hijos del mismo padre (hermanos) de izquierda a derecha.
- Elimine los enlaces de padre a todos los hijos excepto al primer hijo.
Dado que tenemos un vínculo entre los niños, no necesitamos vínculos adicionales de los padres a todos los niños. Esta representación nos permite recorrer todos los elementos comenzando por el primer hijo del padre.
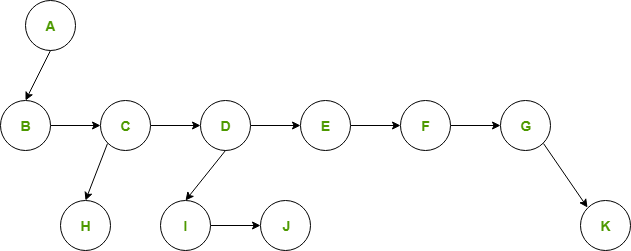
PRIMER HIJO/PRÓXIMO HERMANO REPRESENTACIÓN
La declaración de Node para la representación del primer hijo/siguiente hermano se puede escribir como:
C
//Node declaration
struct Node{
int data;
struct Node *firstChild;
struct Node *nextSibling;
}
ventajas:
- Memoria eficiente: no se requieren enlaces adicionales, por lo que se ahorra mucha memoria.
- Tratados como árboles binarios: dado que podemos convertir cualquier árbol genérico en representación binaria, podemos tratar todos los árboles genéricos con una representación de primer hijo/siguiente hermano como árboles binarios. En lugar de punteros izquierdo y derecho, solo usamos firstChild y nextSibling.
- Muchos algoritmos se pueden expresar más fácilmente porque es solo un árbol binario.
- Cada Node tiene un tamaño fijo, no se requiere una array o vector auxiliar.
Altura del árbol genérico de la array principal
Árbol genérico: recorrido de orden de nivel
Publicación traducida automáticamente
Artículo escrito por shruti171112208 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA