¿Qué es el archivo robots.txt?
La superficie web es un lugar abierto. Varios motores de búsqueda pueden acceder a casi todos los sitios web en la superficie, por ejemplo, si buscamos algo en Google, se puede obtener una gran cantidad de resultados. Pero, ¿qué pasa si los diseñadores web crean algo en su sitio web y no quieren que Google u otros motores de búsqueda accedan a él? Aquí es donde entra en juego el archivo robots.txt . El archivo Robots.txt es un archivo de texto creado por el diseñador para evitar que los motores de búsqueda y los bots rastreen sus sitios. Contiene la lista de sitios permitidos y no permitidos y cada vez que un bot quiere acceder al sitio web, verifica el archivo robots.txt y accede solo a aquellos sitios que están permitidos. No muestra los sitios no permitidos en los resultados de búsqueda.
Necesidad del archivo robots.txt: la razón más importante para esto es mantener privadas todas las secciones de un sitio web para que ningún robot pueda acceder a él. También ayuda a evitar que los motores de búsqueda indexen ciertos archivos. Además, también especifica la ubicación del mapa del sitio.
¿Cómo crear un archivo robots.txt?
El archivo robots.txt es un archivo de texto simple ubicado en su servidor web que le dice a los rastreadores web como el bot de Google si deben acceder a un archivo o no. Este archivo se puede crear en el Bloc de notas. La sintaxis viene dada por:
User-agent: {name of user without braces}
Disallow: {site disallowed by the owner, i.e this can't be indexed}
Sitemap: {the sitemap location of the website}
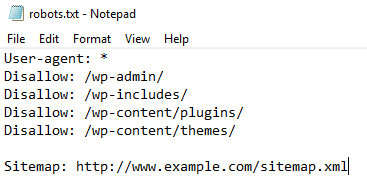
Descripción del componente:
- User-agent: *
Disallow:
El sitio web está abierto a todos los motores de búsqueda (asterisco) y ninguno de sus contenidos está prohibido. - Agente de usuario: Googlebot
Disallow: /
El motor de búsqueda de Googlebot no puede indexar ninguno de sus contenidos. - Agente de usuario: *
Disallow: /file.html
Esto es acceso parcial. Se puede acceder a todos los demás contenidos excepto file.html. - Tiempo de visita: 0200-0300
Esto limita el tiempo para el rastreador. Los contenidos pueden ser indexados sólo entre el intervalo de tiempo dado. - Crawl-delay: 20
Prohíbe que los rastreadores accedan al sitio con frecuencia, ya que haría que el sitio se ralentizara.
Una vez que el archivo esté completo y listo, guárdelo con el nombre “robots.txt” (esto es importante, no use otro nombre) y súbalo al directorio raíz del sitio web. Esto permitirá que el archivo robots.txt haga su trabajo.
Nota: Todo el mundo puede acceder al archivo robots.txt en Internet. Todos pueden ver el nombre de los archivos y agentes de usuario permitidos y no permitidos. Aunque nadie puede abrir los archivos, solo se muestran los nombres de los archivos.
Para comprobar el archivo robots.txt de un sitio web,
"website name" + "/robots.txt" eg: https://www.geeksforgeeks.org/robot.txt
¿Cómo funciona el archivo robots.txt?
Cuando busca algo en cualquier motor de búsqueda, el robot de búsqueda (que es el agente de usuario) encuentra el sitio web para mostrar los resultados. Pero antes de mostrarlo, o incluso indexarlo, busca el archivo robots.txt del sitio web, si lo hay. Si hay uno, el robot de búsqueda lo revisa para verificar los sitios permitidos y no permitidos en el sitio web. Ignora todos los sitios no permitidos ubicados en el archivo y continúa mostrando los contenidos permitidos en los resultados. Así, sólo podrá ver los contenidos permitidos por el titular del sitio web.
Ejemplo:
User-agent: Googlebot Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/plugins/ Disallow: /wp-content/themes/ Crawl-delay: 20 Visit-time: 0200-0300
Esto significa que el bot de Google puede rastrear cada página con un retraso de 20 ms, excepto aquellas URL que no están permitidas durante el intervalo de tiempo de 0200 a 0300 UTC únicamente.
Razón para usar el archivo robots.txt:
las personas tienen diferentes opiniones sobre tener un archivo robots.txt en su sitio web.
Razones para tener un archivo robots.txt:
- Bloquea los contenidos de los motores de búsqueda.
- Sintoniza el acceso al sitio desde robots acreditados.
- Se utiliza en el sitio web en desarrollo actual, que no necesita mostrarse en los motores de búsqueda.
- Se utiliza para hacer que los contenidos estén disponibles para motores de búsqueda específicos.
¿Uso del archivo robots.txt?
El uso más importante de un archivo robots.txt es mantener la privacidad de Internet. No todo en nuestra página web debe mostrarse en mundo abierto, por lo que es una preocupación seria que se trata fácilmente con el archivo robots.txt.
Publicación traducida automáticamente
Artículo escrito por Pulkit_Singh y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA