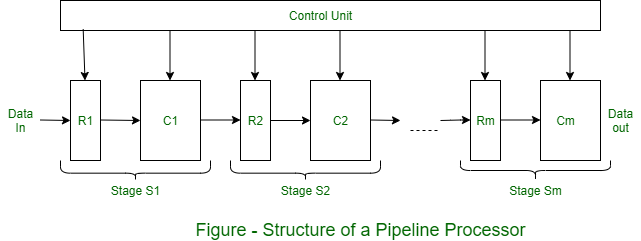
Pipeline Processor consta de una secuencia de m circuitos de procesamiento de datos, llamados etapas o segmentos, que en conjunto realizan una sola operación en un flujo de operandos de datos que pasan a través de ellos. En cada etapa se lleva a cabo algo de procesamiento, pero el resultado final se obtiene solo después de que un conjunto de operandos haya pasado por toda la canalización. Como se muestra en la figura, una etapa S (i) contiene un registro de entrada multipalabra o pestillo R (i) y un circuito de ruta de datos C (i) , que generalmente es combinacional. Los R (i) contienen resultados parcialmente procesados a medida que se mueven a través de la canalización; también sirven como amortiguadores que evitan que las etapas vecinas interfieran entre sí.
Una señal de reloj común hace que los R (i) cambien de estado sincrónicamente. Cada R (i) cambia de estado sincrónicamente. Cada R (i) recibe un nuevo conjunto de datos de entrada D (i-1) de la etapa anterior S (i-1) excepto R (1) cuyos datos se suministran desde una fuente externa. D (i-1) representa los resultados calculados por C (i-1) durante el período de reloj anterior. Una vez que D (i-1) se ha cargado en R (i) , C (i) procede a D (i-1) para computarizar un nuevo conjunto de datos D (i). Así, en cada período de reloj, cada etapa transfiere sus resultados anteriores a la etapa siguiente y computa un nuevo conjunto de resultados.
Publicación traducida automáticamente
Artículo escrito por rajkumarupadhyay515 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA