YOLO v2 y YOLO 9000 fueron propuestos por J. Redmon y A. Farhadi en 2016 en el documento titulado YOLO 9000: Better, Faster, Stronger . A 67 FPS, YOLOv2 da mAP de 76,8 % y a 67 FPS da un mAP de 78,6 % en el conjunto de datos VOC 2007 mejoró los modelos como Faster R-CNN y SSD . YOLO 9000 usó la arquitectura YOLO v2 pero pudo detectar más de 9000 clases. YOLO 9000, sin embargo, tiene un mAP de 19.7% mAP con 16% mAP en aquellas clases 156 clases que no están en COCO. Sin embargo, YOLO puede predecir más de 9000 clases.
Arquitectura:

Arquitectura Darknet-19
La arquitectura de YOLO9000 es muy similar a la arquitectura de YOLOv2. También utiliza la arquitectura Darknet-19 como su arquitectura de red neuronal profunda (DNN). Sin embargo, la principal diferencia entre su arquitectura de clasificación. Veamos la arquitectura de clasificación de YOLO 9000 a continuación:
Tarea de clasificación:
El conjunto de datos de detección de objetos (COCO: 80 clases) tiene muchas menos clases que la clasificación (ImageNet: 22k clases). Para ampliar las clases que YOLO puede detectar. El documento propone un método para fusionar las tareas de clasificación y detección con la detección. Entrena con la red de extremo a extremo mientras retropropaga la pérdida de clasificación. Sin embargo, el problema de la simple fusión de todas las clases de detección y clasificación no son simplemente excluyentes entre sí. Por ejemplo, en los conjuntos de datos de COCO, las etiquetas de clase son clases generales como Gato, Perro, etc., pero en Imagenet hay clases específicas (por ejemplo, para Perro tenemos clases Norfolk terrier”, “Yorkshire terrier” o “Bedlington terrier”). No podríamos tener también diferentes clases de softmax para «Dog» y «Norfolk terrier» porque no son mutuamente excluyentes.
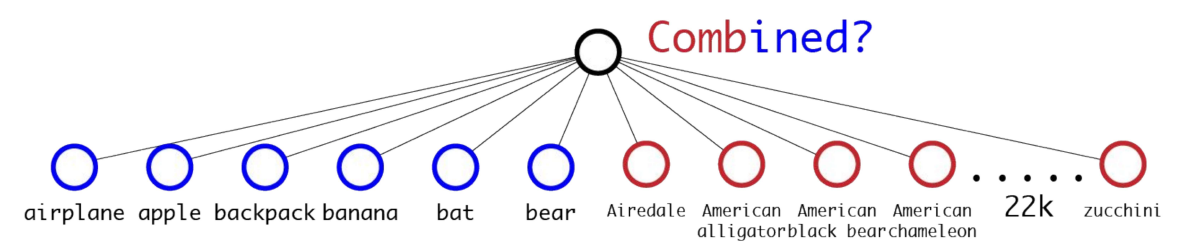
No podemos combinar directamente porque las clases no son mutuamente excluyentes.
Clasificación Jerárquica:
YOLO9000 propuso un método llamado Clasificación Jerárquica. En este método. propusieron una estructura jerárquica basada en un árbol para representar las clases con sus subclases cuando hacemos la clasificación. Por ejemplo, Norfolk Terrier pertenece a la categoría de «terrier», que a su vez pertenece a la clase de «perro». Esta estructura está inspirada en WordNet. Pero, en lugar de usar la estructura gráfica, solo usa la estructura de árbol jerárquico basada en el concepto de colecciones de imágenes en el conjunto de datos Imagenet). Esta estructura jerárquica se llama WordTree.

Ejemplo de árbol de palabras
Para realizar la clasificación, este WordTree utiliza probabilidad condicional en cada nivel de Node. Para calcular la probabilidad condicional del Node hoja (clase específica) necesitamos multiplicar la probabilidad condicional de todos sus padres. Esta arquitectura define “Objeto Físico” ya que su Node raíz considera que P r (Objeto Físico) =1.
Por ejemplo, la probabilidad condicional para diferentes tipos de terrier se puede calcular como:

Ahora, podemos obtener la probabilidad absoluta de que el objeto pertenezca a la clase “Norfolk Terrier”.

Aquí, el documento utiliza ImageNet-1000 como ejemplo para realizar el experimento. En lugar de crear una estructura plana de 1000 capas, creamos una estructura de árbol jerárquico similar a WordTree con 1000 Nodes de hoja y 369 Nodes principales.

Imagenet simple de 1k frente a WordTree
Utilizando los mismos parámetros de entrenamiento que en YOLOv2, este Darknet-19 jerárquico en Imagenet logra una precisión del 71,9 % entre los primeros 1 y una precisión del 90,4 % entre los 5 primeros. La ventaja de la clasificación jerárquica cuando este modelo no puede distinguir entre clases de hojas es que otorga una alta probabilidad a la clase principal.
Entrenamiento:
El modelo combina las clases COCO con las etiquetas de clase top-9000 de Imagenet usando el método WordTree para obtener un WordTree de 9418 Nodes. Entonces, el WordTree correspondiente tiene 9418 clases. Imagenet es un conjunto de datos mucho más grande que COCO. Para equilibrar el conjunto de datos, sobremuestreamos COCO de modo que la relación entre Imagenet y la muestra COCO sea de 4:1.
Entrenamos el modelo usando el conjunto de datos YOLOv2, pero usamos solo 3 cuadros de anclaje en lugar de 5. Cuando esta red ingresa una imagen de detección, esto retropropaga la pérdida de detección como normal, pero para la pérdida de clasificación, retropropaga la pérdida en o por encima del nivel correspondiente del etiqueta.
Resultados y conclusión:
YOLO9000 tiene un mAP general del 19,7 % con un 16 % de mAP en las clases que no están presentes en el conjunto de datos de detección. También funciona mejor en nuevas especies de animales que no están presentes en el conjunto de datos de COCO. El mAp es más alto que el mAp que resulta en el modelo DPM.
La principal ventaja de YOLO9000 es que es capaz de predecir más de 9000 clases (9418 para ser precisos) en tiempo real.

Resultados YOLO 9000
Debido a su gran número de capacidad de predicción de clase. Es una de las arquitecturas de reconocimiento de objetos más utilizadas, desde imágenes médicas hasta vigilancia con drones, industria manufacturera, etc.
Referencia: