En un entorno de subprocesos múltiples, los algoritmos sin bloqueo proporcionan una forma en que los subprocesos pueden acceder a los recursos compartidos sin la complejidad de los bloqueos y sin bloquear los subprocesos para siempre. Estos algoritmos se convierten en la elección de un programador, ya que proporcionan un mayor rendimiento y evitan puntos muertos.
Esto se debe principalmente a que el diseño de algoritmos basados en bloqueos, para la concurrencia, trae sus propios desafíos sobre la mesa. La complejidad de escribir bloqueos y sincronización eficientes para reducir la contención de subprocesos no es del agrado de todos. Y además, incluso después de escribir el código complejo, muchas veces ocurren errores difíciles de encontrar en los entornos de producción, donde se involucran múltiples subprocesos, lo que se vuelve aún más difícil de resolver.
Manteniendo esta perspectiva, hablaremos sobre cómo podemos aplicar un algoritmo sin bloqueo a una de las estructuras de datos más utilizadas en Java , llamada Stack . Como sabemos, Stack se usa en muchas aplicaciones de la vida real, como funciones de deshacer/rehacer en un procesador de textos, evaluación de expresiones y análisis de sintaxis, en procesamiento de lenguaje, en el soporte de recursiones y también nuestra propia JVM está orientada a Stack. Entonces, tengamos una idea de cómo escribir una pila sin bloqueo. Espero que encienda su mente lo suficiente como para leer y adquirir más conocimientos sobre este tema.
Clases atómicas en Java
Java proporciona una plétora de clases que admiten programación sin bloqueo y segura para subprocesos. La API atómica proporcionada por Java, el paquete java.util.concurrent.atomic contiene muchas clases y características avanzadas que proporcionan control de concurrencia sin tener que usar bloqueos. AtomicReference también es una de esas clases en la API que proporciona una referencia a las referencias de objetos subyacentes que se pueden leer y escribir atómicamente. Por atómico, queremos decir que las lecturas y escrituras en estas variables son seguras para subprocesos. Por favor, consulte el siguiente enlace para más detalles.
CAS Inside – Operación CompareAndSwap:
La operación más importante, que es el componente básico de los algoritmos sin bloqueo, es la comparación y el intercambio. Se compila en una sola operación de hardware, lo que lo hace más rápido ya que la sincronización aparece en un nivel granular. Además, esta operación está disponible en todas las Clases Atómicas. CAS tiene como objetivo actualizar el valor de una variable/referencia comparándolo con su valor actual.
Aplicación de CAS para una pila sin bloqueo:
Una pila sin bloqueo básicamente significa que las operaciones de la pila están disponibles para todos los subprocesos y ningún subproceso está bloqueado. Para usar CAS en las operaciones de la pila, se escribe un ciclo en el que el valor del Node superior (llamado stack top) de la pila se verifica usando CAS. Si el valor de stackTop es el esperado, se reemplaza con el nuevo valor superior; de lo contrario, no se cambia nada y el subproceso vuelve a entrar en el bucle.
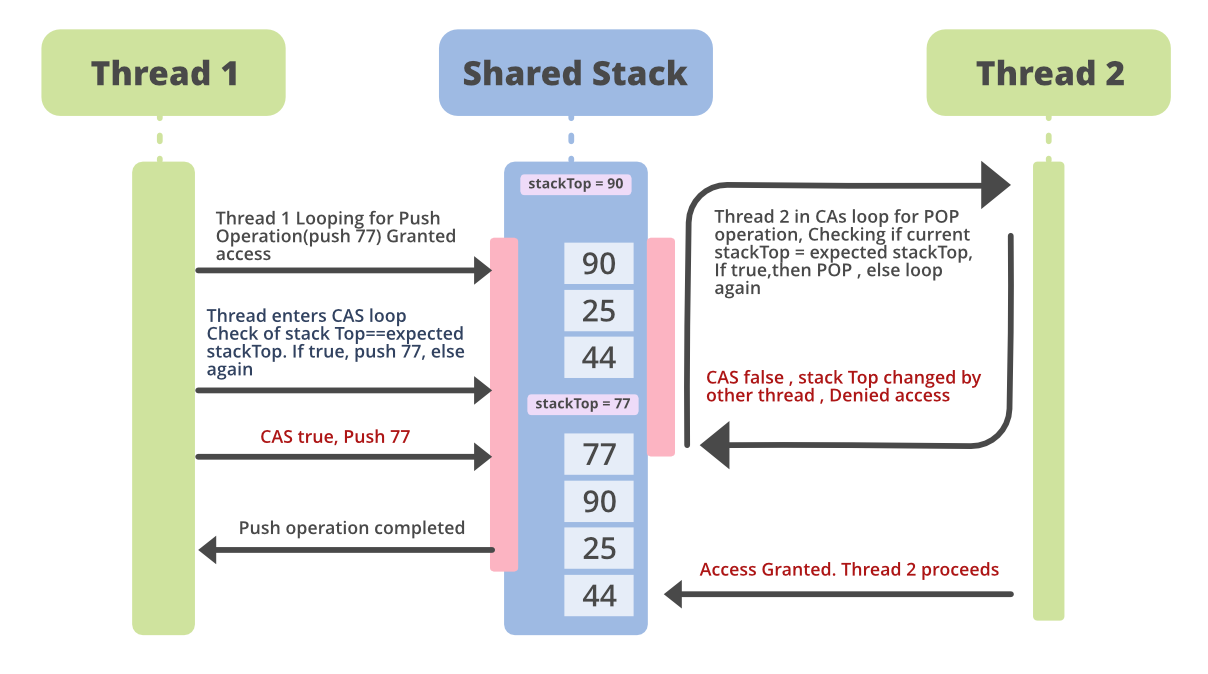
Digamos que tenemos una pila de enteros. Supongamos que thread1 quiere insertar un valor 77 en la pila cuando el valor de la parte superior de la pila es 90. Y thread2 quiere sacar la parte superior de la pila que es 90, actualmente. Si el subproceso1 intenta acceder a la pila y se le otorga acceso porque ningún otro subproceso está accediendo a él en ese momento, entonces el subproceso primero obtiene el valor más reciente de la parte superior de la pila. Luego ingresa al bucle CAS y verifica la parte superior de la pila con el valor esperado (90). Si los dos valores son iguales, es decir: CAS devolvió verdadero, lo que significa que ningún otro subproceso lo ha modificado, el nuevo valor (77 en nuestro caso) se coloca en la pila. Y 77 se convierte en el nuevo tope de la pila. Mientras tanto, thread2 sigue repitiendo el CAS, hasta que CAS devuelve verdadero, para sacar un elemento de la parte superior de la pila. Esto se muestra a continuación en el diagrama.
Ejemplo de código para la pila sin bloqueo:
El ejemplo de código de pila se muestra a continuación. En este ejemplo, hay dos pilas definidas. Uno que usa sincronización tradicional ( llamado ClassicStack aquí ) para lograr el control de concurrencia. La otra pila utiliza la operación de comparación y configuración de la clase AtomicReference para establecer un algoritmo sin bloqueo (llamado aquí LockFreeStack ). Aquí estamos contando el número de operaciones realizadas por la Pila en un lapso de 1/2 segundo. Comparamos el rendimiento de las dos pilas a continuación:
Java
// Java program to demonstrate Lock-Free
// Stack implementation
import java.io.*;
import java.util.List;
import java.util.ArrayList;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.locks.LockSupport;
class GFG {
public static void main(String[] args)
throws InterruptedException
{
// Defining two stacks
// Uncomment the following line to see the
// standard stack implementation.
// ClassicStack<Integer> operStack = new
// ClassicStack<Integer>(); Lock-Free Stack
// definition.
LockFreeStack<Integer> operStack
= new LockFreeStack<Integer>();
Random randomIntegerGenerator = new Random();
for (int j = 0; j < 10; j++) {
operStack.push(Integer.valueOf(
randomIntegerGenerator.nextInt()));
}
// Defining threads for Stack Operations
List<Thread> threads = new ArrayList<Thread>();
int stackPushThreads = 2;
int stackPopThreads = 2;
for (int k = 0; k < stackPushThreads; k++) {
Thread pushThread = new Thread(() -> {
System.out.println("Pushing into stack...");
while (true) {
operStack.push(Integer.valueOf(
randomIntegerGenerator.nextInt()));
}
});
// making the threads low priority before
// starting them
pushThread.setDaemon(true);
threads.add(pushThread);
}
for (int k = 0; k < stackPopThreads; k++) {
Thread popThread = new Thread(() -> {
System.out.println(
"Popping from stack ...");
while (true) {
operStack.pop();
}
});
popThread.setDaemon(true);
threads.add(popThread);
}
for (Thread thread : threads) {
thread.start();
}
Thread.sleep(500);
System.out.println(
"The number of stack operations performed in 1/2 a second-->"
+ operStack.getNoOfOperations());
}
// Class defining the implementation of Lock Free Stack
private static class LockFreeStack<T> {
// Defining the stack nodes as Atomic Reference
private AtomicReference<StackNode<T> > headNode
= new AtomicReference<StackNode<T> >();
private AtomicInteger noOfOperations
= new AtomicInteger(0);
public int getNoOfOperations()
{
return noOfOperations.get();
}
// Push operation
public void push(T value)
{
StackNode<T> newHead = new StackNode<T>(value);
// CAS loop defined
while (true) {
StackNode<T> currentHeadNode
= headNode.get();
newHead.next = currentHeadNode;
// perform CAS operation before setting new
// value
if (headNode.compareAndSet(currentHeadNode,
newHead)) {
break;
}
else {
// waiting for a nanosecond
LockSupport.parkNanos(1);
}
}
// getting the value atomically
noOfOperations.incrementAndGet();
}
// Pop function
public T pop()
{
StackNode<T> currentHeadNode = headNode.get();
// CAS loop defined
while (currentHeadNode != null) {
StackNode<T> newHead = currentHeadNode.next;
if (headNode.compareAndSet(currentHeadNode,
newHead)) {
break;
}
else {
// waiting for a nanosecond
LockSupport.parkNanos(1);
currentHeadNode = headNode.get();
}
}
noOfOperations.incrementAndGet();
return currentHeadNode != null
? currentHeadNode.value
: null;
}
}
// Class defining the implementation
// of a Standard stack for concurrency
private static class ClassicStack<T> {
private StackNode<T> headNode;
private int noOfOperations;
// Synchronizing the operations
// for concurrency control
public synchronized int getNoOfOperations()
{
return noOfOperations;
}
public synchronized void push(T number)
{
StackNode<T> newNode = new StackNode<T>(number);
newNode.next = headNode;
headNode = newNode;
noOfOperations++;
}
public synchronized T pop()
{
if (headNode == null)
return null;
else {
T val = headNode.getValue();
StackNode<T> newHead = headNode.next;
headNode.next = newHead;
noOfOperations++;
return val;
}
}
}
private static class StackNode<T> {
T value;
StackNode<T> next;
StackNode(T value) { this.value = value; }
public T getValue() { return this.value; }
}
}
Producción:
Pushing into stack... Pushing into stack... Popping from stack ... Popping from stack ... The number of stack operations performed in 1/2 a second-->28514750
El resultado anterior se recibe al implementar la estructura de datos de pila Lock Free. Vemos que hay 4 subprocesos diferentes, 2 para empujar y 2 para sacar de Stack . El número de operaciones significa operaciones Pop o Push en la pila.
Para compararlo con la versión de pila estándar en la que se usa la sincronización tradicional para la concurrencia, podemos simplemente descomentar la primera línea del código y comentar la segunda línea de código de la siguiente manera.
Java
// Lock Based Stack programming
// This will invoke the lock-based version of the stack.
import java.io.*;
class GFG {
public static void main(String[] args)
{
ClassicStack<Integer> operStack = new ClassicStack<Integer>();
// LockFreeStack<Integer> operStack = new LockFreeStack<Integer>();
}
}
El resultado de la pila basada en bloqueos se muestra a continuación. Muestra claramente que la implementación sin bloqueo (arriba) proporciona casi 3 veces más salida.
Producción:
Pushing into stack... Pushing into stack... Popping from stack ... Popping from stack ... The number of stack operations performed in 1/2 a second-->8055597
Aunque la programación sin bloqueo ofrece una gran cantidad de beneficios, programarla correctamente no es una tarea trivial.
Ventajas:
- Programación verdaderamente libre de bloqueos.
- Prevención de interbloqueo.
- Mayor rendimiento.
Contras
- El problema de ABA aún puede ocurrir en un algoritmo sin bloqueo (que es un cambio en el valor de una variable de A a B y luego de regreso a A mientras dos subprocesos están leyendo el mismo valor A, sin que el otro subproceso lo sepa)
- Es posible que los algoritmos sin bloqueo no siempre sean muy fáciles de codificar.
Los algoritmos y las estructuras de datos sin bloqueo son un tema muy debatido en el mundo de Java. Cuando se utilizan algoritmos basados en bloqueo o sin bloqueo, se debe realizar una comprensión profunda del sistema. Uno debe estar muy atento para usar cualquiera de ellos. No existe una solución o algoritmo de «talla única» para los diferentes tipos de problemas de simultaneidad. Por lo tanto, decidir qué algoritmo se adapta mejor a una situación es una parte crucial de la programación en el mundo de subprocesos múltiples.
Referencias:
- Resumen del paquete atómico concurrente
- Soporte de bloqueo
- Treiber_stack
- Introducción a los algoritmos de no bloqueo
Publicación traducida automáticamente
Artículo escrito por mathurritika y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA