La palabra CAPTCHA significa la prueba de Turing pública completamente automatizada para diferenciar a las computadoras de los humanos .
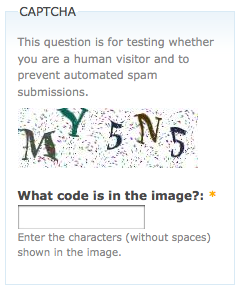
¿Cuántos de ustedes lo encontraron molesto? Luis von Ahn inventó el término llamado CAPTCHA y la razón es que existe para asegurarse de que usted, la entidad que completa el formulario, sea un ser humano y no una especie de programa de computadora escrito para enviar el formulario millones de veces. Por ejemplo, en el caso de Ticketmaster, la razón por la que debe escribir estos caracteres distorsionados es para evitar que los revendedores escriban un programa que pueda comprar millones de boletos a la vez.
Este proyecto fue algo que Luis von Ahn, Manuel Blum, Nicholas J. Hopper y John Langford hicieron en Carnegie Mellon hace unos diez años y se usa en todas partes. Luego hicieron un proyecto unos años más tarde, que es una especie de próxima evolución de captchas. Este es el proyecto que llamaron reCAPTCHA , que es algo que comenzaron allí en Carnegie Mellon, luego lo convirtieron en una empresa nueva y luego, hace aproximadamente un año y medio, Google adquirió esta empresa. Para saber cómo generar un CAPTCHA, consulte Programa para generar CAPTCHA y verificar usuario .
Problema con CAPTCHA y Evolución de reCAPTCHA
Este proyecto comenzó con la subsiguiente constatación de que parece que personas de todo el mundo escriben aproximadamente 200 millones de captchas al día. Así que aquí está el hecho de que cada vez que escribes un captcha, esencialmente, pierdes 10 segundos de algún tiempo y si lo multiplicas por 200 millones obtienes que la humanidad en su conjunto está perdiendo alrededor de 500,000 horas al día escribiendo estos molestos captchas. Incluso, no podemos deshacernos de los captchas, ya que la seguridad de la web depende de ellos.
Pero luego, Luis von Ahn y su equipo comenzaron a pensar: «¿Hay alguna forma en que puedan usar este esfuerzo para algo bueno para la humanidad?» Supongamos que una persona está escribiendo un captcha, durante esos 10 segundos, su cerebro está haciendo algo increíble que las computadoras no pueden hacer. Entonces, hoy en día, mientras un ser humano está escribiendo un captcha, no solo se está autenticando como humano, sino que también está ayudando a digitalizar libros.
reCAPTCHA (CAPTCHA invertido)
Muchos proyectos intentan digitalizar libros. Google tiene uno, el archivo web tiene uno, Amazon, con Kindle, está tratando de digitalizar libros. La forma en que funciona es que comienzas con un libro y luego lo escaneas. Escanear un libro es como tomar una fotografía digital de cada página del libro. Te da una imagen de cada página del libro. El siguiente paso en el proceso es que la PC debe estar lista para descifrar todas las palabras en esta imagen. Eso se hace usando una tecnología llamada OCR (Reconocimiento Óptico de Caracteres), que toma una foto del texto y trata de averiguar qué texto hay allí. Ahora, el problema es que el OCR no es perfecto, especialmente para libros antiguos, donde la tinta se ha desvanecido y, por lo tanto, las páginas se han vuelto amarillas, el OCR no puede reconocer toneladas de palabras. Por cosas que fueron escritas hace 50 años, la computadora ni siquiera puede reconocer alrededor del 30 por ciento de las palabras. Entonces, lo que están haciendo ahora es tomar todas las palabras que la computadora no puede reconocer y hacer que la gente las lea y escriba un captcha en Internet. Entonces, la próxima vez que escriba un captcha, estas palabras que está escribiendo son palabras que provienen de libros que se están digitalizando y que la computadora no pudo reconocer.
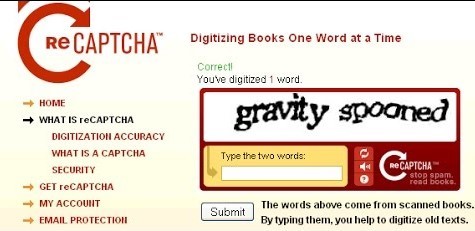
Por lo tanto, así suele funcionar el sistema, y desde que lo lanzaron hace unos 3 o 4 años, toneladas de sitios de Internet comenzaron a cambiar del antiguo captcha, en el que la gente perdía el tiempo, al nuevo captcha, en el que la gente ayuda a digitalizar libros. Entonces, por ejemplo, Ticketmaster, cada vez que compras boletos en Ticketmaster, ayudas a digitalizar un libro. Facebook, cada vez que agregas un amigo o empujas a alguien, ayudas a digitalizar un libro. Alrededor de 350 000 sitios web utilizan reCAPTCHA. Y, de hecho, la cantidad de sitios web que usan reCAPTCHA es tan alta que la cantidad de palabras que digitalizamos por día es extremadamente grande. Son alrededor de 100 millones cada día ., que es el equivalente a unos dos millones y medio de libros al año. Y esto a menudo se hace palabra a palabra por personas que escriben captchas en la web.
Cosas relacionadas con CAPTCHA
1. Sin CAPTCHA reCAPTCHA: Google implementa una API de reemplazo que simplifica radicalmente la experiencia reCAPTCHA. Lo llaman «No CAPTCHA reCAPTCHA». En los sitios web que usan esta nueva API, una gran cantidad de usuarios estarán listos para verificar de manera segura y simple que son humanos sin tener que desentrañar un CAPTCHA. En cambio, con solo un clic, confirmarán que no son un robot. Y así es como se ve:
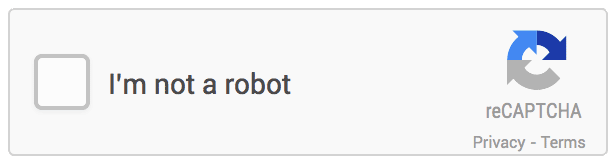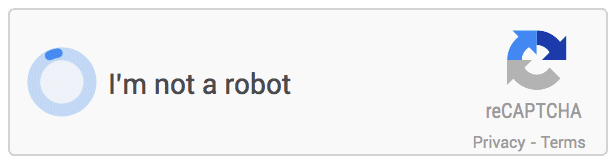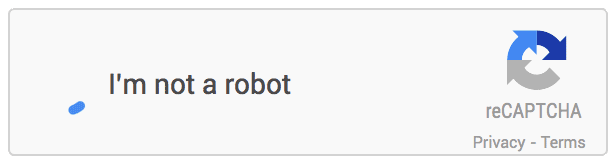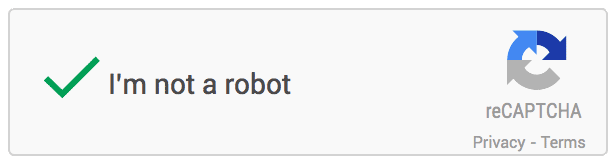
2. SQUIGL-PIX: Para resolver este CAPTCHA, un usuario debe leer y comprender una instrucción escrita en lenguaje natural. Un usuario tiene que entender qué rastrear, luego encontrar un objeto en una de las imágenes dadas y rastrearlo. Si él / ella rastrea el objeto correcto, podemos decir que las instrucciones se han entendido correctamente. Y así es como se ve:

3. ESP-PIX: en lugar de escribir letras, puede autenticarse como persona reconociendo qué objeto es común durante un conjunto de imágenes. Este fue el ejemplo principal de un reconocimiento de imagen compatible con CAPTCHA. Y así es como se ve:

Aplicaciones de los CAPTCHA:
- Prevención del spam en los comentarios de los blogs.
- Protección de direcciones de correo electrónico de raspadores.
- Protección del registro del sitio web.
- Prevención de ataques de diccionario.
- Gusanos y spam.
- Robots de motores de búsqueda.
- Encuestas en línea.
Publicación traducida automáticamente
Artículo escrito por AmiyaRanjanRout y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA