Requisito previo: instalación de BeautifulSoup
En este artículo, extraeremos una cita y los detalles del autor de este sitio http//quotes.toscrape.com usando el marco de Python llamado BeautifulSoup y desarrollaremos un juego de adivinanzas usando diferentes estructuras de datos y algoritmos.
El usuario tendrá 4 oportunidades para adivinar el autor de una cita famosa. En cada oportunidad, el usuario recibirá una pista que puede ser la fecha de nacimiento del autor, la primera letra del nombre, la primera letra del segundo nombre, etc. Al adivinar con éxito el autor, se imprime un mensaje y si el usuario no logra adivinar la respuesta incluso después de las 4 oportunidades, se imprime nuevamente un mensaje junto con la respuesta.
Acercarse
- Módulo de importación
- Las requests nos ayudan a capturar la página, cuando se recibe la respuesta, se almacena en forma de string.
- La biblioteca bs4 se usa para crear un objeto beasutifulSoup.
- La biblioteca csv ayuda a leer y escribir archivos CSV usando python
- La función de suspensión del módulo de tiempo ayuda a agregar retraso en la ejecución del programa.
- La función de elección del módulo aleatorio devuelve un elemento aleatorio.
- Crear una lista para almacenar valores raspados
- Extraiga los detalles de este enlace: http//quotes.toscrape.com
- Extraer datos
- lógica del juego
- Devuelve elementos aleatorios del diccionario creado
- Establecer el número de conjeturas
- Escribir mensaje para el éxito y el fracaso
- Siga dando pistas hasta que el número de posibilidades llegue a cero o el usuario lo haga bien
Programa:
Python3
import requests
from bs4 import BeautifulSoup
from csv import writer
from time import sleep
from random import choice
# list to store scraped data
all_quotes = []
# this part of the url is constant
base_url = "http://quotes.toscrape.com/"
# this part of the url will keep changing
url = "/page/1"
while url:
# concatenating both urls
# making request
res = requests.get(f"{base_url}{url}")
print(f"Now Scraping{base_url}{url}")
soup = BeautifulSoup(res.text, "html.parser")
# extracting all elements
quotes = soup.find_all(class_="quote")
for quote in quotes:
all_quotes.append({
"text": quote.find(class_="text").get_text(),
"author": quote.find(class_="author").get_text(),
"bio-link": quote.find("a")["href"]
})
next_btn = soup.find(_class="next")
url = next_btn.find("a")["href"] if next_btn else None
sleep(2)
quote = choice(all_quotes)
remaining_guesses = 4
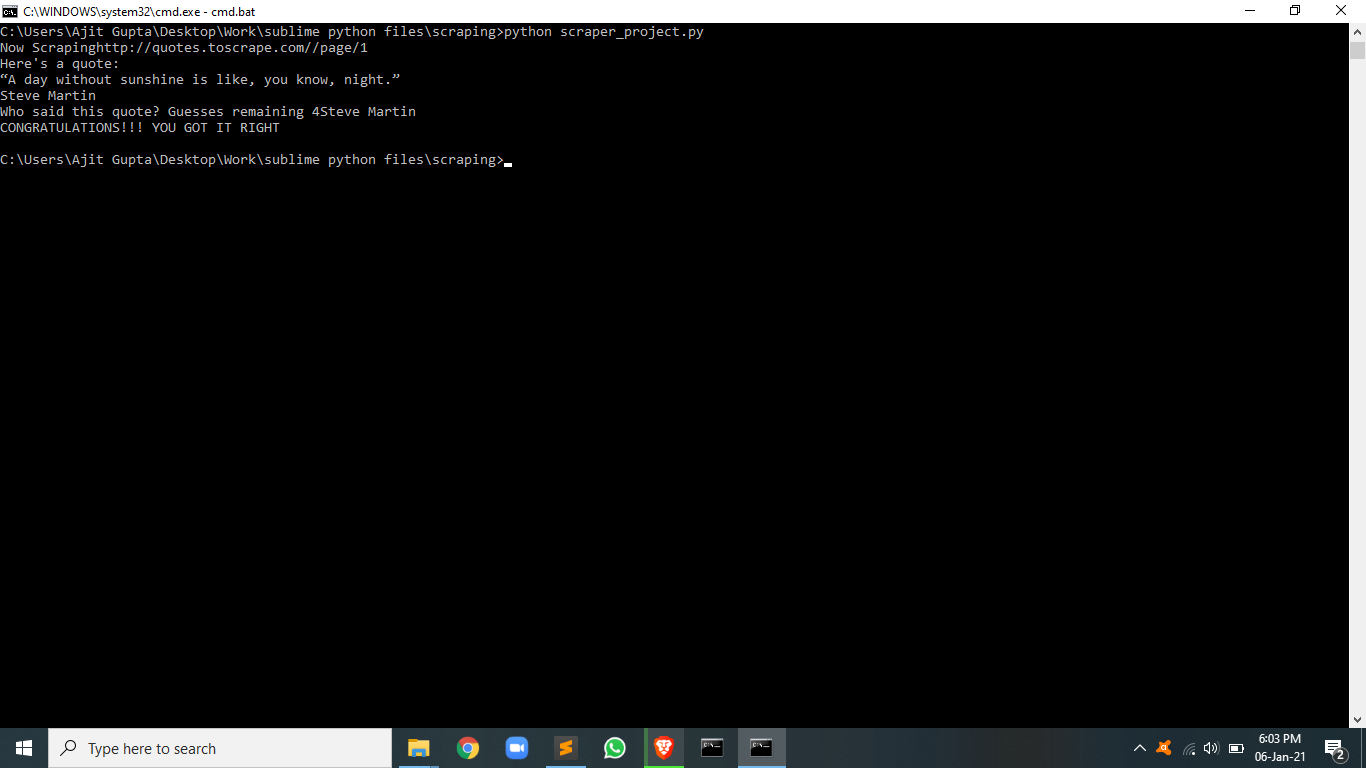
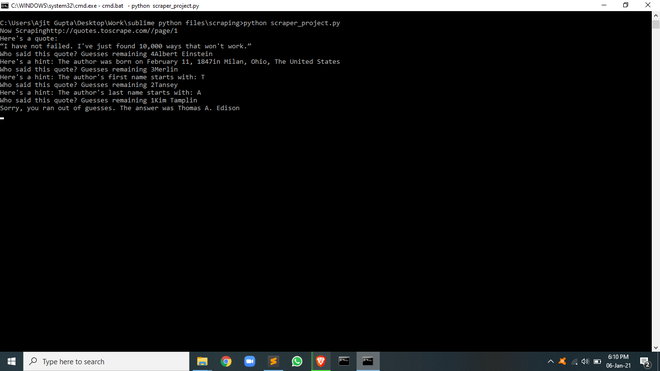
print("Here's a quote: ")
print(quote["text"])
guess = ''
while guess.lower() != quote["author"].lower() and remaining_guesses > 0:
guess = input(
f"Who said this quote? Guesses remaining {remaining_guesses}")
if guess == quote["author"]:
print("CONGRATULATIONS!!! YOU GOT IT RIGHT")
break
remaining_guesses -= 1
if remaining_guesses == 3:
res = requests.get(f"{base_url}{quote['bio-link']}")
soup = BeautifulSoup(res.text, "html.parser")
birth_date = soup.find(class_="author-born-date").get_text()
birth_place = soup.find(class_="author-born-location").get_text()
print(
f"Here's a hint: The author was born on {birth_date}{birth_place}")
elif remaining_guesses == 2:
print(
f"Here's a hint: The author's first name starts with: {quote['author'][0]}")
elif remaining_guesses == 1:
last_initial = quote["author"].split(" ")[1][0]
print(
f"Here's a hint: The author's last name starts with: {last_initial}")
else:
print(
f"Sorry, you ran out of guesses. The answer was {quote['author']}")
Producción:
Publicación traducida automáticamente
Artículo escrito por prernaajitgupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA